Test-Time Training Done Right
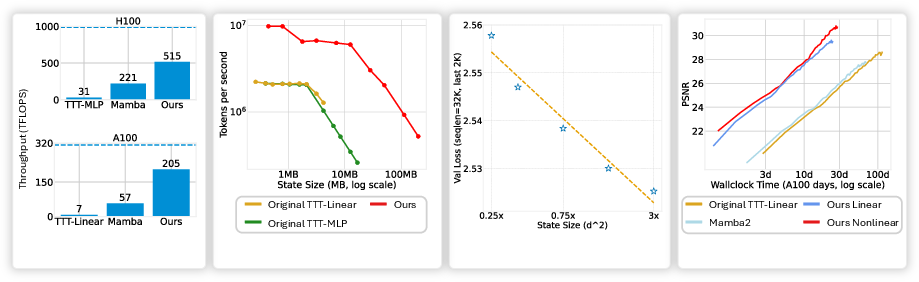
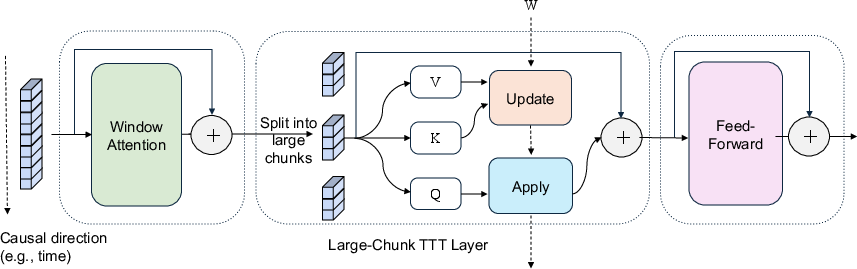
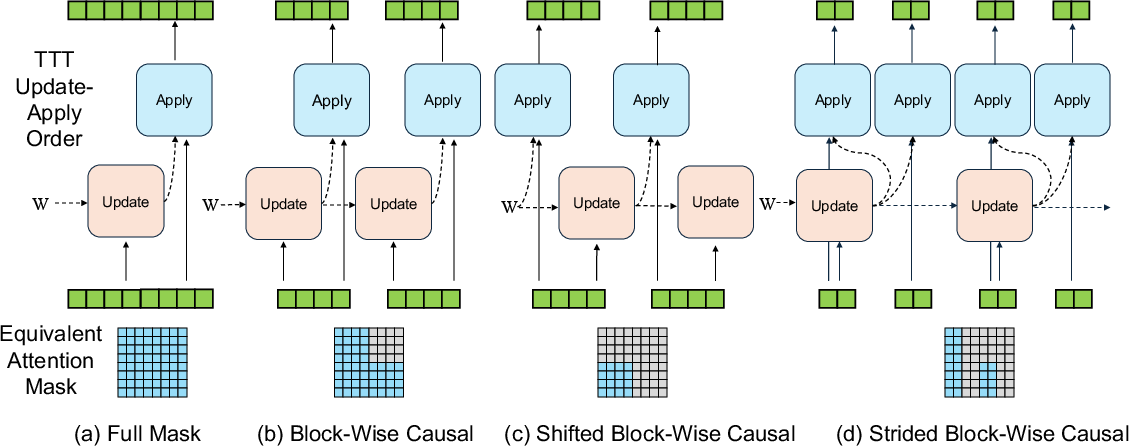
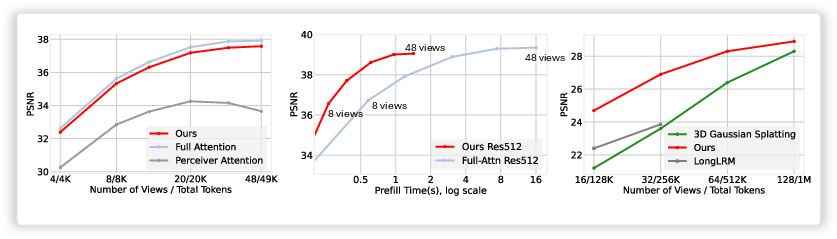
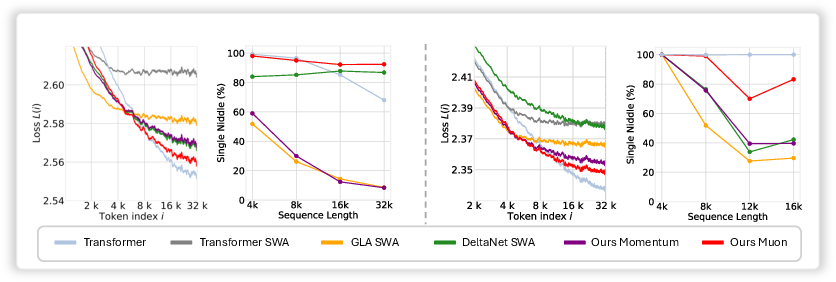
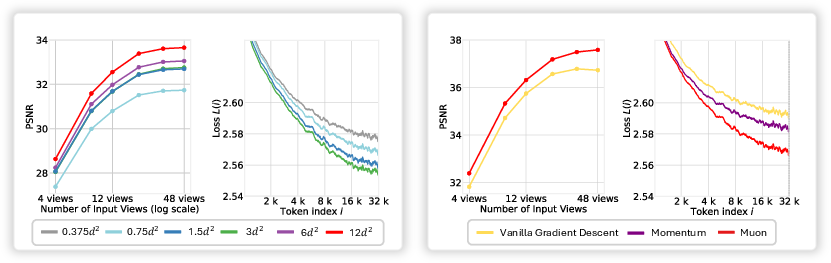
Abstract: Test-Time Training (TTT) models context dependencies by adapting part of the model's weights (referred to as fast weights) during inference. This fast weight, akin to recurrent states in RNNs, stores temporary memories of past tokens in the current sequence. Existing TTT methods struggled to show effectiveness in handling long-context data, due to their inefficiency on modern GPUs. The TTT layers in many of these approaches operate with extremely low FLOPs utilization (often <5%) because they deliberately apply small online minibatch sizes (e.g., updating fast weights every 16 or 64 tokens). Moreover, a small minibatch implies fine-grained block-wise causal dependencies in the data, unsuitable for data beyond 1D ordered sequences, like sets or N-dimensional grids such as images or videos. In contrast, we pursue the opposite direction by using an extremely large chunk update, ranging from 2K to 1M tokens across tasks of varying modalities, which we refer to as Large Chunk Test-Time Training (LaCT). It improves hardware utilization by orders of magnitude, and more importantly, facilitates scaling of nonlinear state size (up to 40% of model parameters), hence substantially improving state capacity, all without requiring cumbersome and error-prone kernel implementations. It also allows easy integration of sophisticated optimizers, e.g. Muon for online updates. We validate our approach across diverse modalities and tasks, including novel view synthesis with image set, LLMs, and auto-regressive video diffusion. Our approach can scale up to 14B-parameter AR video diffusion model on sequences up to 56K tokens. In our longest sequence experiment, we perform novel view synthesis with 1 million context length. We hope this work will inspire and accelerate new research in the field of long-context modeling and test-time training. Website: https://tianyuanzhang.com/projects/ttt-done-right
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.