- The paper demonstrates that integrating Test-Time Training modules improves long-term forecasting accuracy by dynamically updating hidden states at inference time.
- The model architecture replaces traditional Mamba blocks with quadruple TTT blocks, leveraging both channel mixing and channel independence modes to capture complex dependencies.
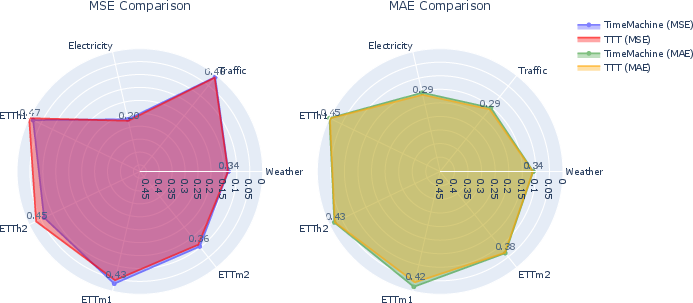
- Experimental results on benchmark datasets like Electricity, Traffic, and Weather show significant improvements in MSE and MAE compared to state-of-the-art models.
Test Time Learning for Time Series Forecasting
Introduction
The paper "Test Time Learning for Time Series Forecasting" (2409.14012) introduces a novel approach to enhance time-series forecasting performance through the integration of Test-Time Training (TTT) modules into the model architecture. The authors identify that while recent advancements such as state-space models (SSMs) have improved long-range dependency capture using linear RNNs, there is still a gap in accuracy and scalability when predicting extended sequences. The proposed TTT modules aim to fill this gap by leveraging dynamic hidden states updated at inference time, providing adaptability to non-stationary data and improving long-term forecasting accuracy.
Model Architecture
The proposed architecture modifies the existing Mamba-based TimeMachine model by replacing Mamba blocks with quadruple TTT blocks (Figure 1). This change retains the model's compatibility with linear RNNs while enhancing its capacity to manage long-range dependencies due to the adaptive nature of TTT. The architecture supports two operational modes:
- Channel Mixing Mode: Captures inter-channel correlations, crucial for understanding complex multivariate dependencies.
- Channel Independence Mode: Focuses on intra-channel dynamics, vital for analyzing each channel's unique characteristics.
These modes are illustrated through hierarchical processing layers that operate at both high and low resolutions to extract contextual cues effectively (Figure 1 and Figure 2).
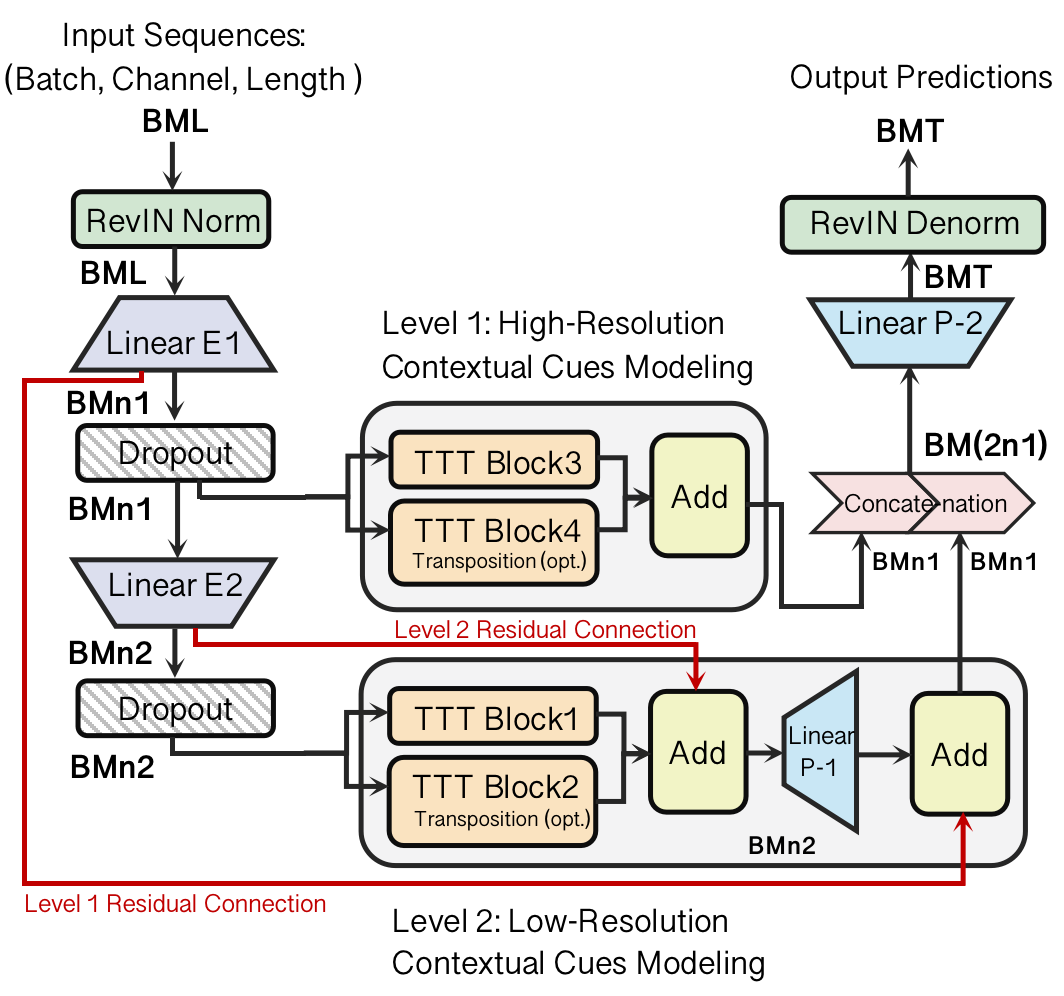
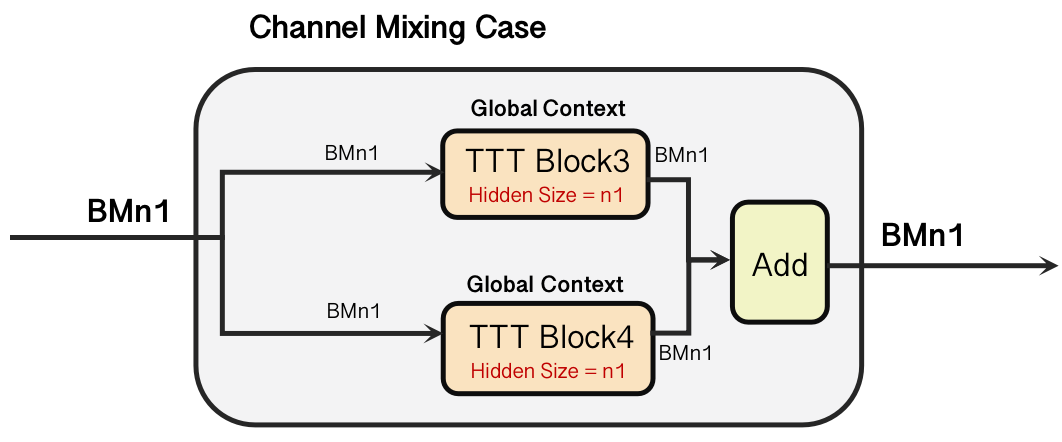
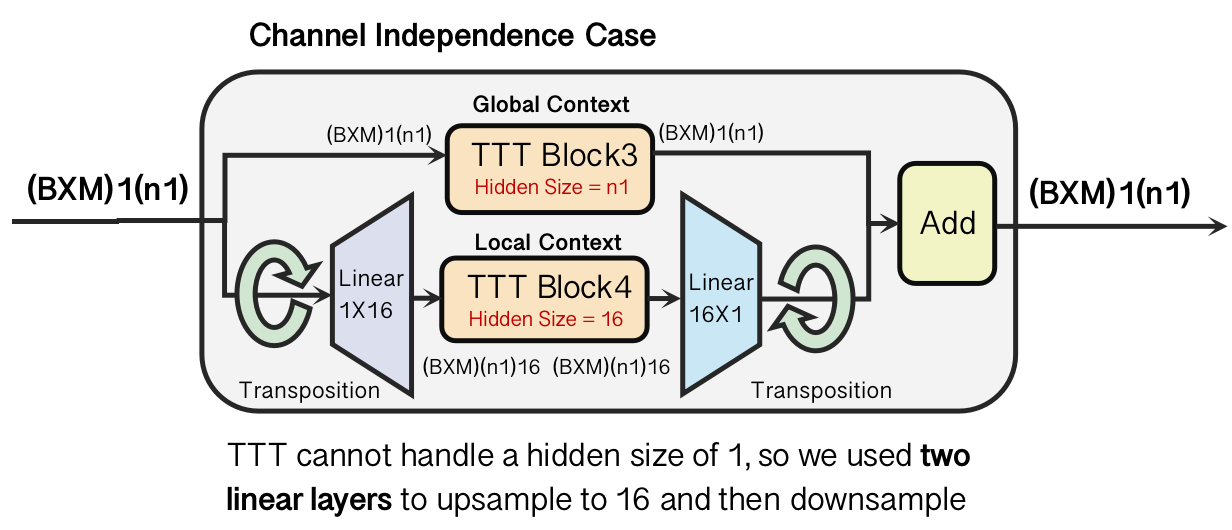
Figure 1: Our model architecture. (a) We replace the four Mamba Block in TimeMachine with four TTT(Test-Time Training) Block. (b) There are two modes of TimeMachine, the channel mixing mode for capturing strong between-channel correlations, and the channel independence mode for modeling within-channel dynamics.
Experimental Evaluation
The efficacy of the TTT-based architecture is substantiated through comprehensive experiments on several standard benchmark datasets. These experiments reveal that TTT modules consistently outperform state-of-the-art models, especially on larger datasets like Electricity, Traffic, and Weather.
Implications and Future Work
The research sets a new benchmark for scalable, high-performance time-series forecasting and opens pathways for future explorations:
- Theoretical Contributions: Introduces a theoretical foundation that supports the adaptability of TTT in capturing long-range dependencies without catastrophic forgetting.
- Practical Applications: Shows promise in enhancing forecasting models in domains with inherently dynamic data, such as energy consumption, traffic flow, and climate science.
Further investigations could explore hybrid architectures combining TTT with more complex models like Transformers and assess the applicability of TTT in real-time systems where computational overhead is a critical consideration.
Conclusion
The paper presents a compelling advancement in time-series forecasting by deploying Test-Time Training modules, which enhance model adaptability to dynamic data distributions. By integrating these modules into existing models, researchers can achieve superior forecasting accuracy in scenarios with long sequence dependencies and non-stationary data. This approach not only redefines the state of the art but also lays a strong foundation for future research in scalable forecasting models.