- The paper introduces a dual-structure indexing method combining LLM-generated summary trees and SpaCy-constructed entity graphs to boost efficiency.
- It leverages an adaptive retrieval mechanism that dynamically switches between local and global contexts, optimizing query handling without manual settings.
- The framework achieves significant performance gains, with up to 10x faster indexing and 100x faster retrieval, while maintaining competitive QA benchmarks.
E2GraphRAG: Streamlining Graph-based RAG for High Efficiency and Effectiveness
Introduction
E2GraphRAG presents a novel approach to enhancing the efficiency and effectiveness of graph-based Retrieval-Augmented Generation (RAG) systems. Traditional RAG methodologies often suffer from inefficiencies and require predefined query modes, limiting their practical applicability in real-world scenarios. E2GraphRAG addresses these challenges by introducing a streamlined framework that constructs summary trees using LLMs and entity graphs via SpaCy. This integration facilitates robust and fast retrieval processes, supporting both local and global contexts.
Indexing Stage
E2GraphRAG's indexing stage innovatively combines the strengths of graph and tree structures for document representation. It constructs a hierarchical summary tree by recursively summarizing document chunks with an LLM. Concurrently, it creates an entity graph by extracting entities with SpaCy. This dual-structure approach not only accelerates the indexing process but also captures both coarse and fine-grained knowledge effectively.
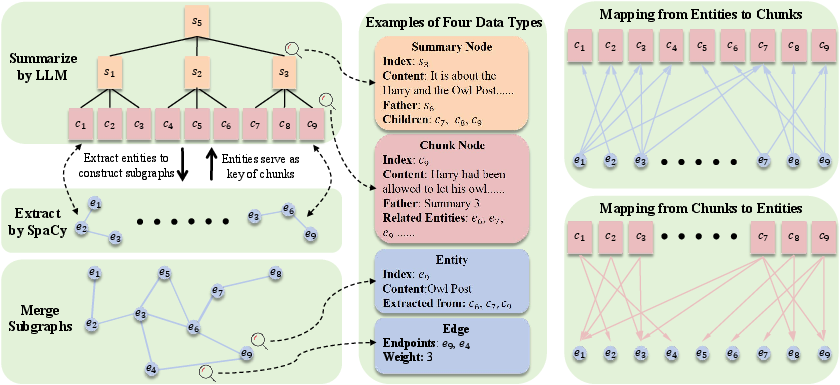
Figure 1: Overview of the indexing stage of E2GraphRAG. The left part shows the indexing tasks, the center presents the four data structures, and the right part displays the two constructed indexes.
Retrieval Stage
The retrieval stage of E2GraphRAG is characterized by its adaptive mechanism that distinguishes between local and global context retrieval. This is achieved by utilizing a lightweight strategy that dynamically switches modes based on query characteristics and graph entity connectivity. The approach ensures efficient retrieval by modeling structural relationships among entities, enhancing the model's flexibility to various queries without tedious manual settings.
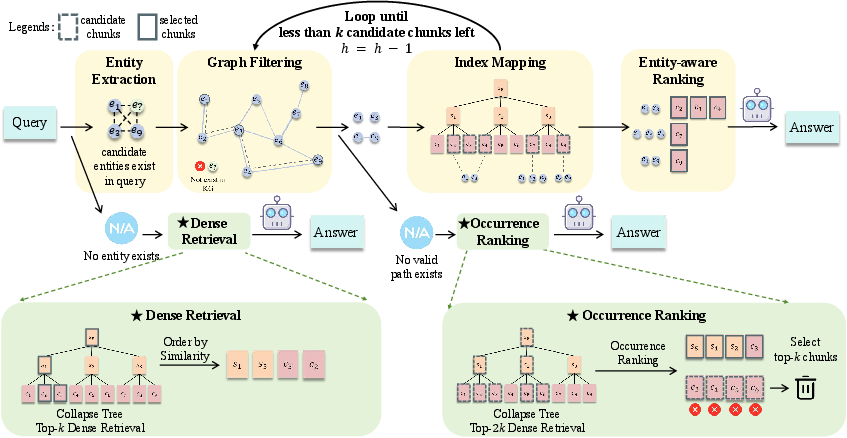
Figure 2: The retrieval stage of E2GraphRAG. Operations belonging to the local retrieval are highlighted in light yellow, while those for global retrieval are highlighted in light green.
Computational Efficiency and Effectiveness
E2GraphRAG demonstrates significant gains in both efficiency and effectiveness compared to previous methods like GraphRAG and LightRAG. Empirical results indicate up to a 10x speedup in the indexing stage and 100x speedup in retrieval processes, all while maintaining competitive question-answering (QA) performance benchmarks.
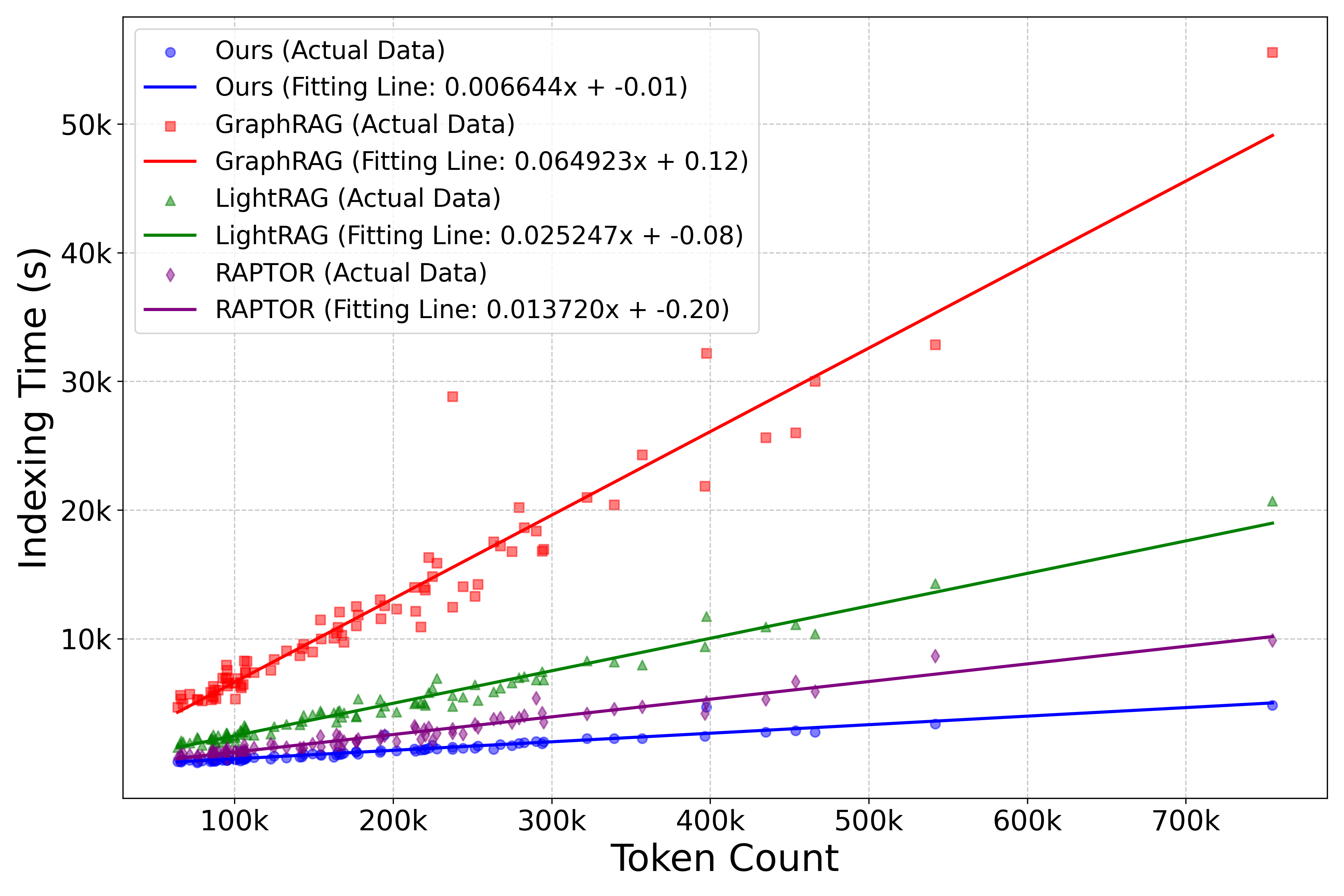
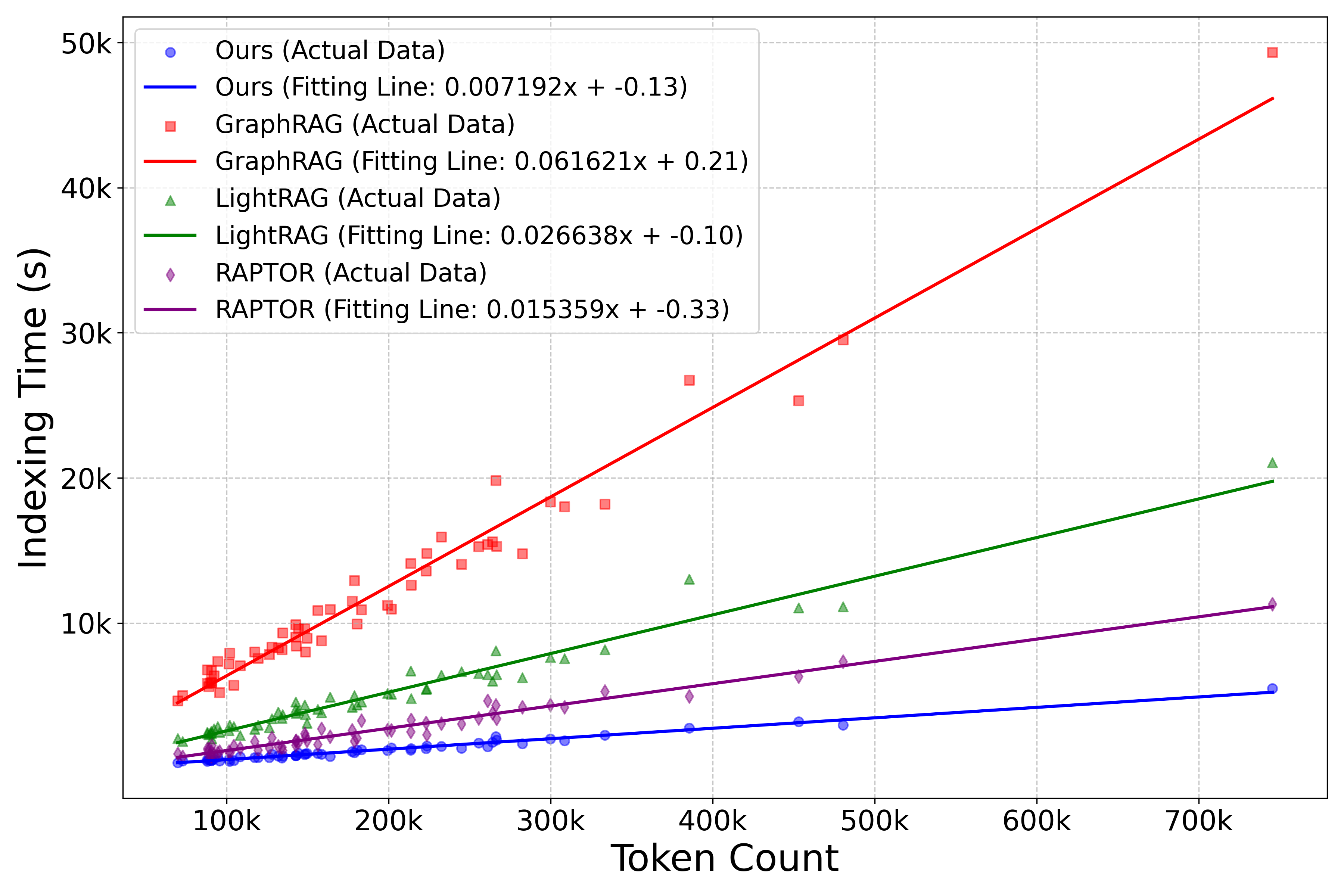
Figure 3: Time cost as a function of document token count for each method. The statistic is based on NovelQA and InfiniteChoice with Qwen as the base model.
E2GraphRAG effectively reduces both computational and time overhead by intelligently orchestrating the indexing and retrieval strategies between tree and graph structures. Its efficiency makes it particularly suitable for applications requiring rapid processing of extensive textual data.
Implications and Future Work
The E2GraphRAG framework has significant implications for improving the scalability and adaptability of modern NLP systems, especially in environments constrained by computational resources. Future research could further optimize retrieval strategies, explore alternative methods for entity extraction and relation mapping, and address potential biases in automated extraction systems.
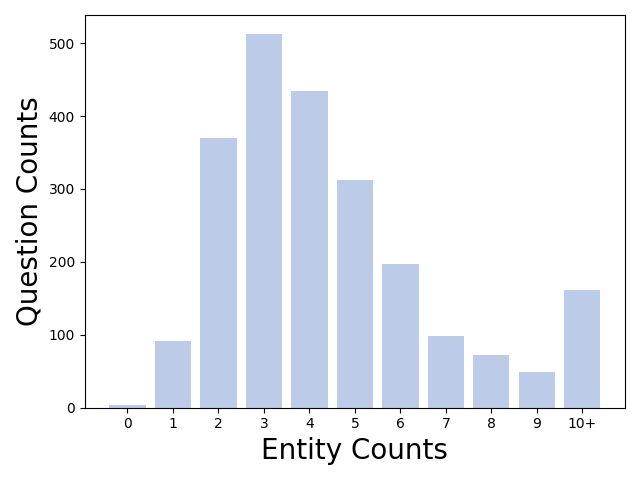
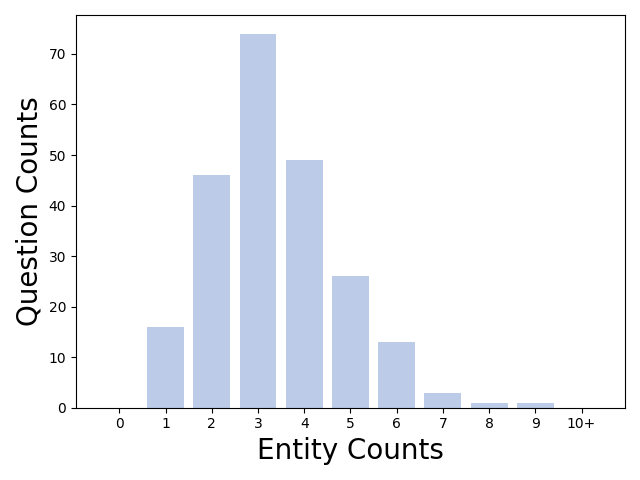
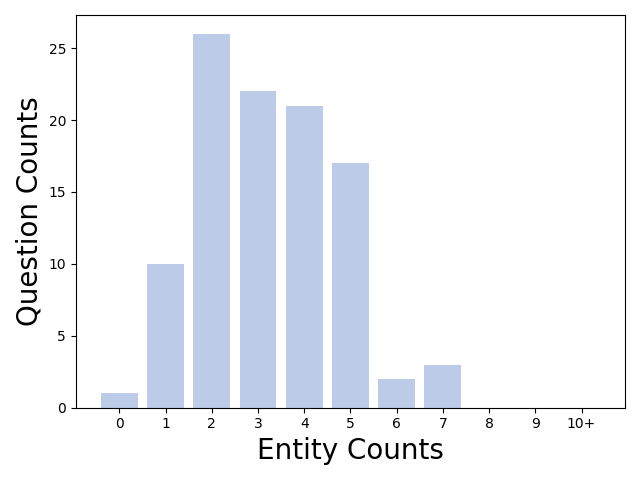
Figure 4: Distribution of questions across different entity count buckets.
Conclusion
E2GraphRAG represents a substantial advancement in the domain of RAG systems by optimizing both efficiency and effectiveness in handling long documents. Its novel integration of LLM-driven tree summarization and SpaCy-facilitated graph construction underscores a balanced approach to high-performance NLP applications. Moving forward, E2GraphRAG sets a promising precedent for future iterations of graph-based retrieval frameworks in various AI-driven tasks.
