- The paper introduces GraphAnchor, an iterative RAG framework that uses a dynamic graph index to anchor critical entities and relations for enhanced multi-hop reasoning.
- The paper employs entity and relation extraction to construct an RDF-structured index, enabling stepwise evidence gathering and subquery generation.
- The paper demonstrates robust performance improvements—up to 12% in EM and F1 metrics—across multiple multi-hop QA benchmarks, validating the graph's role in reducing noise.
Graph-Anchored Knowledge Indexing for Retrieval-Augmented Generation
Motivation and Context
Retrieval-Augmented Generation (RAG) addresses factuality issues in LLMs by injecting external evidence, but faces systematic challenges in noise accumulation and distributed evidence aggregation, especially in multi-hop QA. Traditional RAG pipelines aggregate retrieved passages as flat context, leading to insufficient knowledge integration and suboptimal reasoning, particularly as retrieval depth increases. Existing solutions employ reranking, summarization, or rudimentary structuring, but these approaches do not fully leverage the potential of explicit relational modeling or dynamic cross-document indexing.
GraphAnchor: Evolving Graphs as Active Knowledge Indices
GraphAnchor introduces an iterative RAG framework wherein a dynamically evolving graph structure explicitly anchors salient entities and relations extracted from retrieved documents at each retrieval step. This mechanism shifts the role of the knowledge graph from static representation to an active, context-aware index that supports stepwise reasoning, query generation, and answer production.
The system operates as follows: for each initial query, relevant documents are retrieved and used to update the graph via entity/relation extraction, forming an RDF-structured, linearly verbalized index. The model then assesses sufficiency of indexed knowledge; if gaps remain, follow-up subqueries are generated and the cycle continues. Final answer generation leverages both the union of all retrieved documents and the evolved graph index. This process strongly modulates LLM attention and guides evidence aggregation across distributed sources.
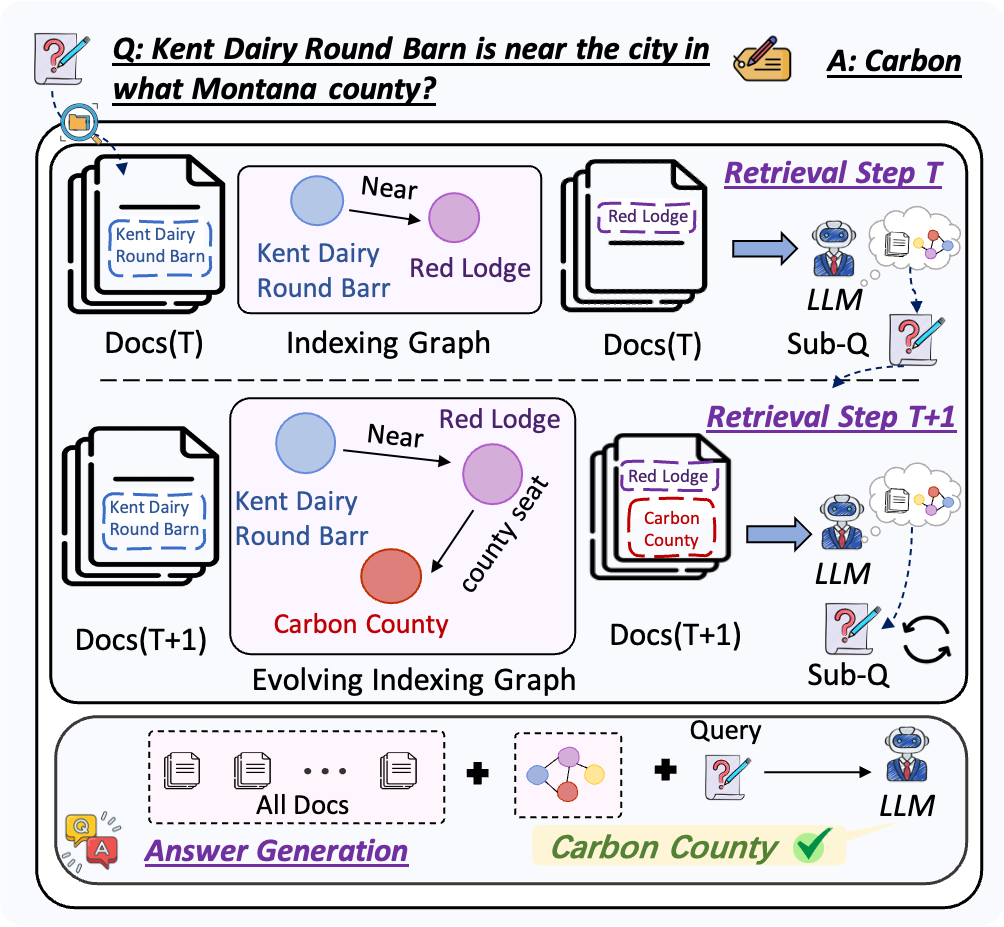
Figure 1: Illustration of GraphAnchor's progressive knowledge indexing, where the graph is updated as retrieval proceeds.
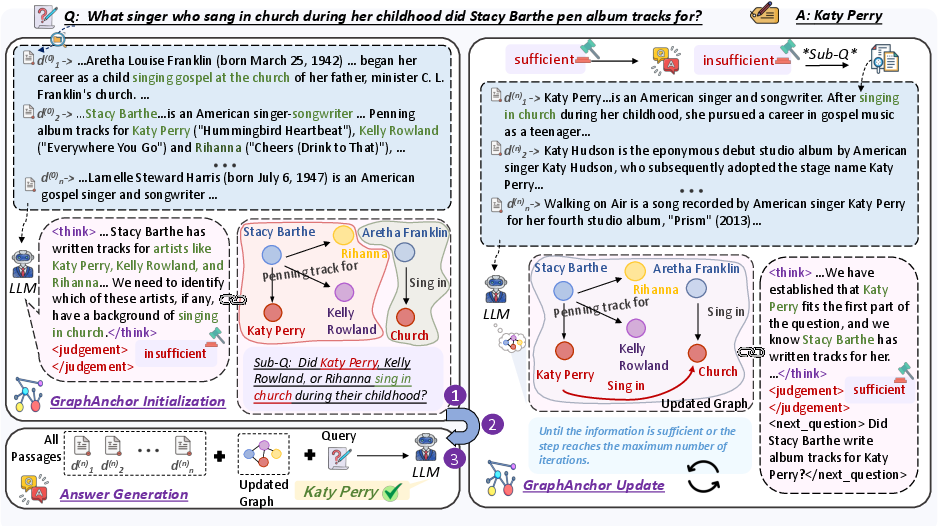
Figure 2: Schematic overview of the iterative retrieval and graph evolution in GraphAnchor.
Evaluation and Numerical Results
GraphAnchor is evaluated on four multi-hop QA benchmarks (MuSiQue, HotpotQA, 2WikiMQA, Bamboogle) using multiple LLM backbones (Qwen2.5-7B/14B, Qwen3-32B, Llama3.1-8B). The method is compared against strong RAG variants including IRCoT, Iter-RetGen, DeepNote, Search-R1, and vanilla RAG.
GraphAnchor achieves an absolute F1 gain of 3–10% and EM gains up to 12% over all baselines, with consistent relative improvements across model and dataset scales. The strong performance is robust to increases in retrieval depth, unlike classical RAG where additional context increases noise and degrades output quality.
Ablations and Graph Structure Analysis
Ablation experiments demonstrate that (i) iterative retrieval is indispensable for sufficient evidence gathering, (ii) the explicit graph index provides significant margin in both document retrieval diversity (lower redundancy) and retrieval accuracy (higher ground-truth hit rate), (iii) structured graph-based indexing is superior to text-based summarization as an intermediate index.
When QA is performed solely on the graph (without documents), there is a measurable (~3%) drop in performance, indicating that the graph acts primarily as an evidence-anchoring mechanism, not as a complete surrogate for the source documents. Full removal of the graph from the pipeline results in >6% F1 drop, highlighting the critical importance of graph-based knowledge management for both retrieval and reasoning.
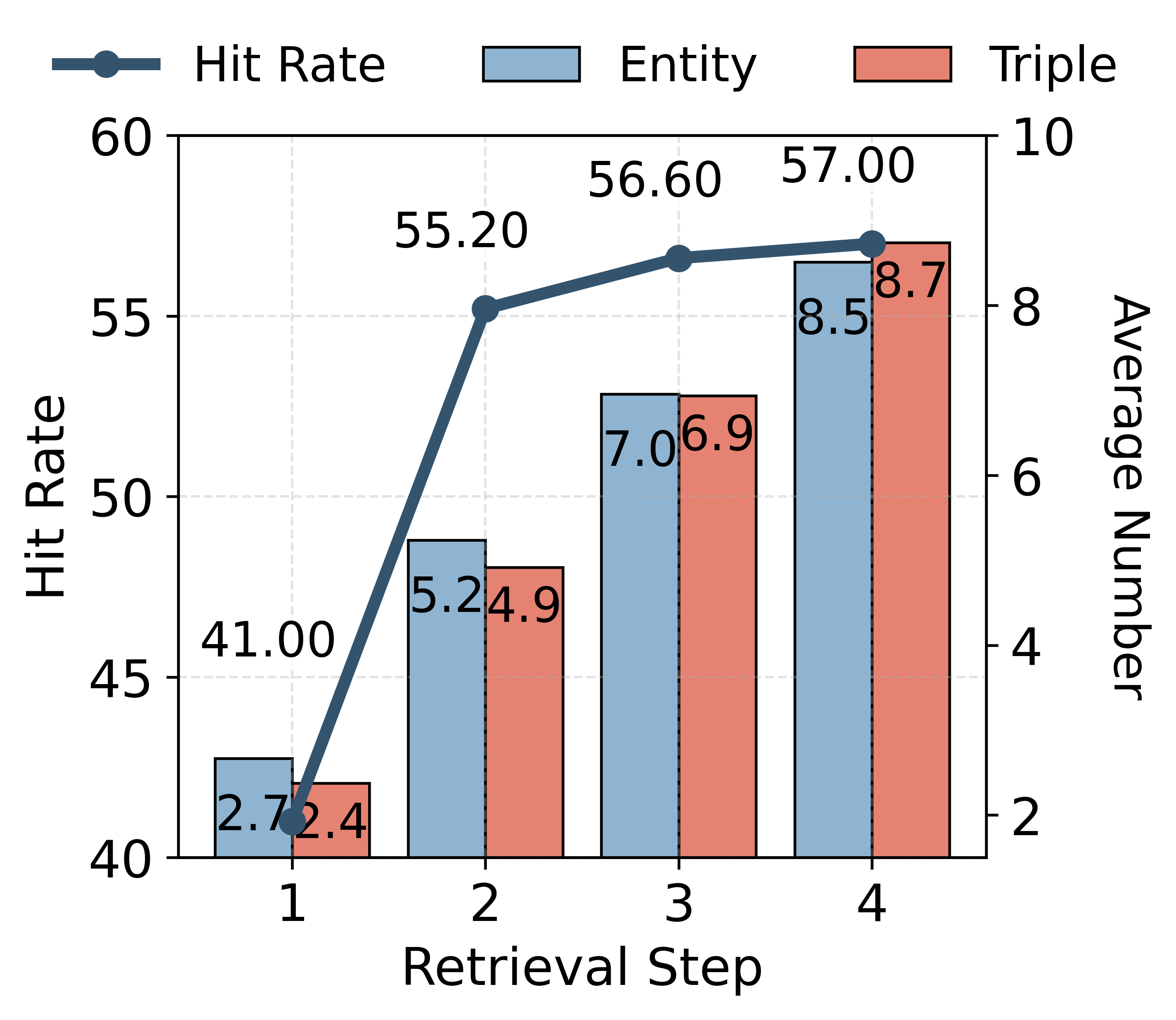
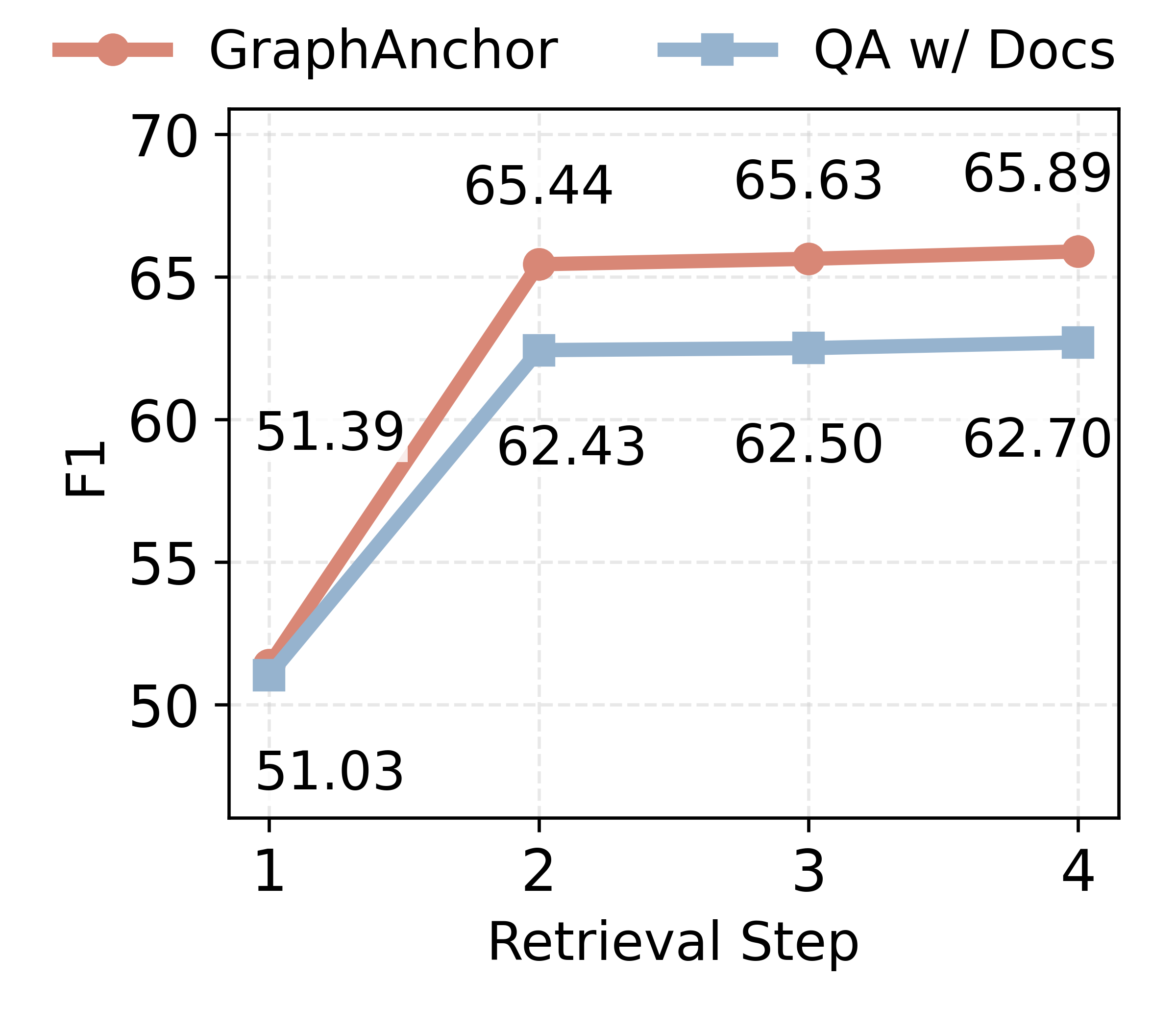
Figure 3: Knowledge anchoring effectiveness across retrieval steps: entity/triple growth and indexed answer hit rate.
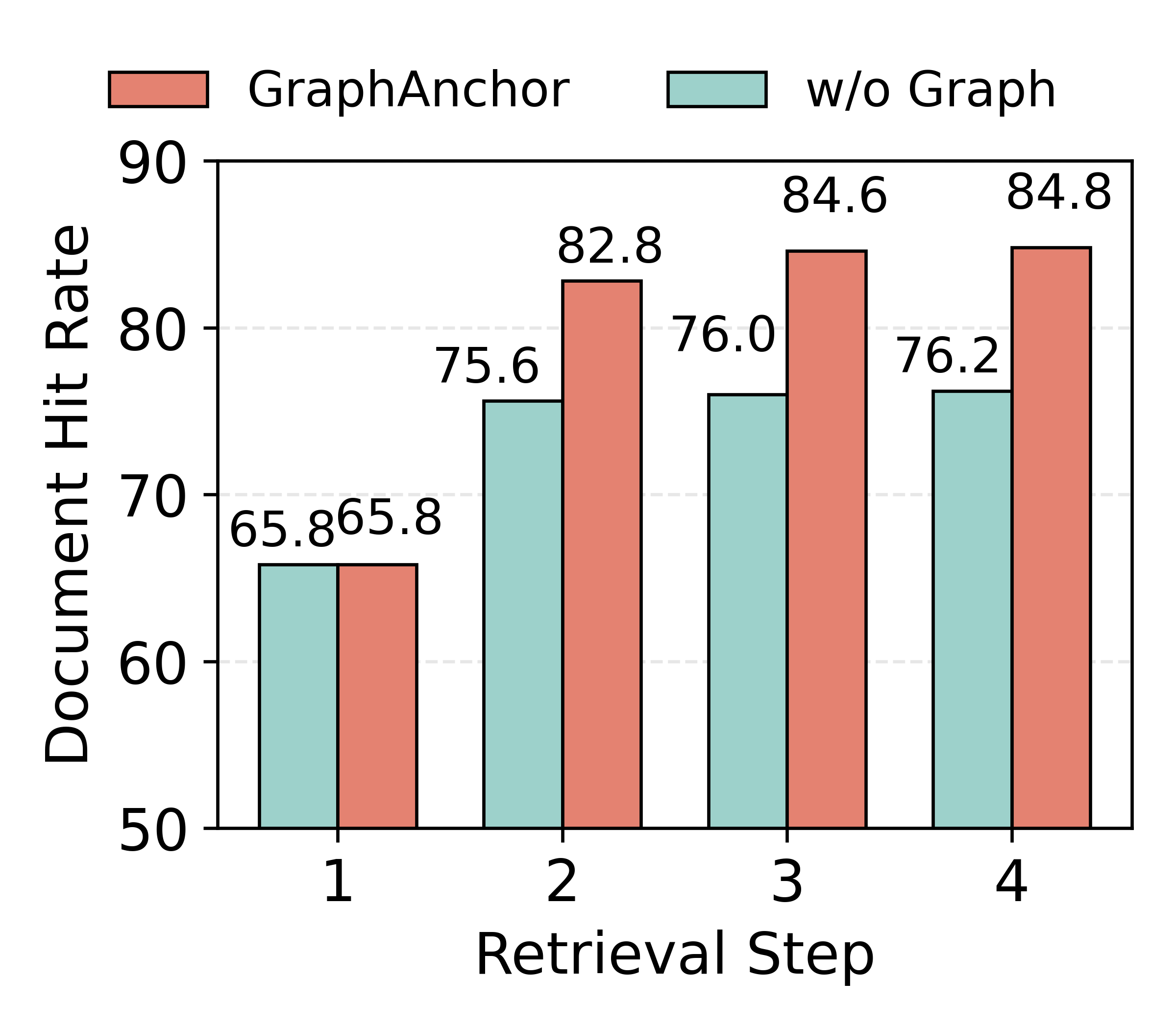
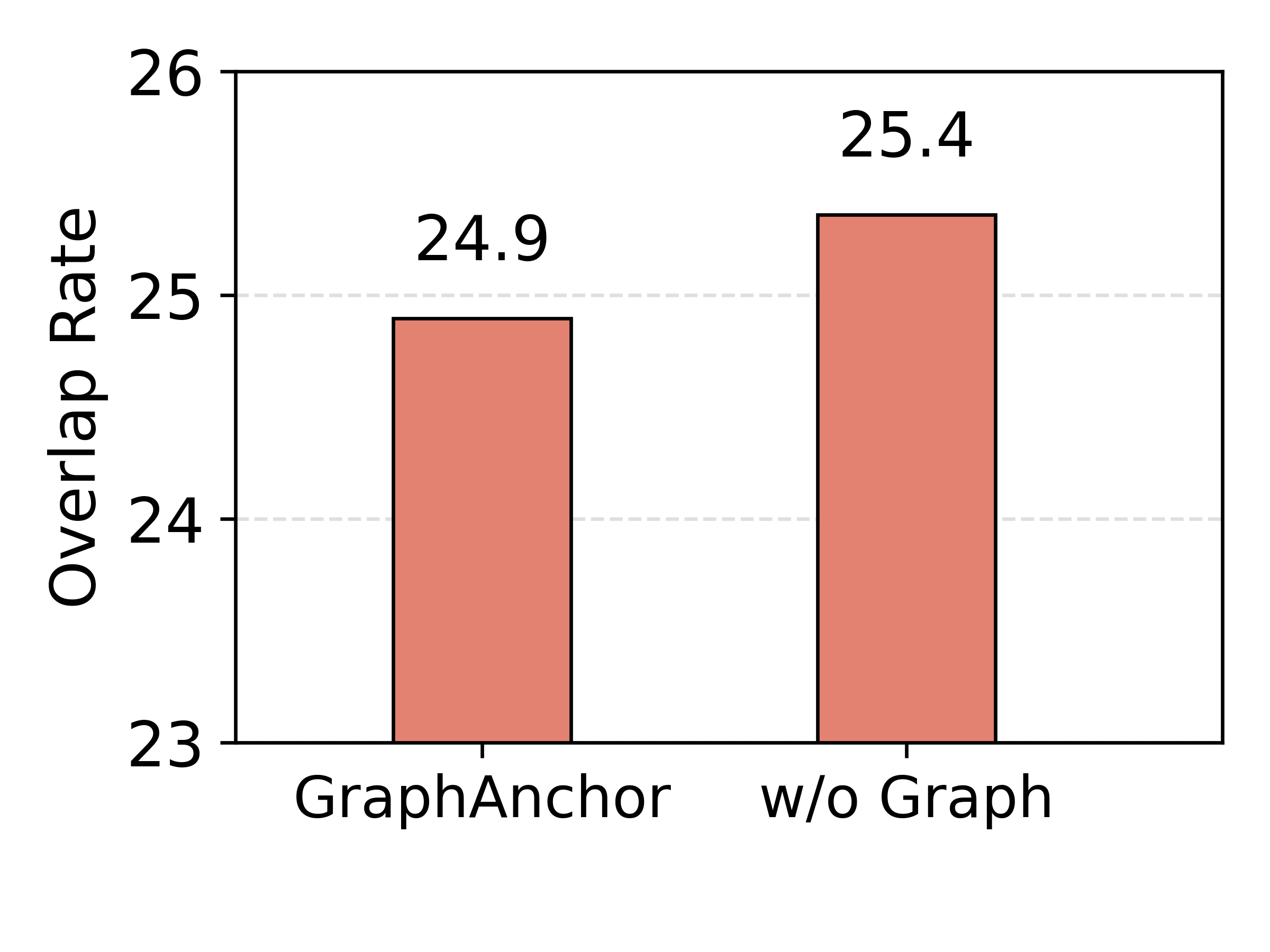
Figure 4: Retrieval effectiveness using the constructed knowledge graph, assessing hit rate and document overlap (accuracy and diversity metrics).
Attention and Knowledge Utilization Analysis
Comprehensive attention analyses reveal that as the graph index evolves, LLM attention becomes progressively more focused on graph-linked evidence spans, resulting in lower reasoning perplexity and more robust answer inference.
- The majority of LLM attention is allocated to the graph index at generation time, increasing with each step of graph evolution.
- Attention entropy rises as more retrieval steps are completed, indicating more selective focus on relevant tokens, and greater suppression of noise.
- Newly anchored entities receive surges of attention at the step they are added, directly guiding answer derivation via the graph structure.
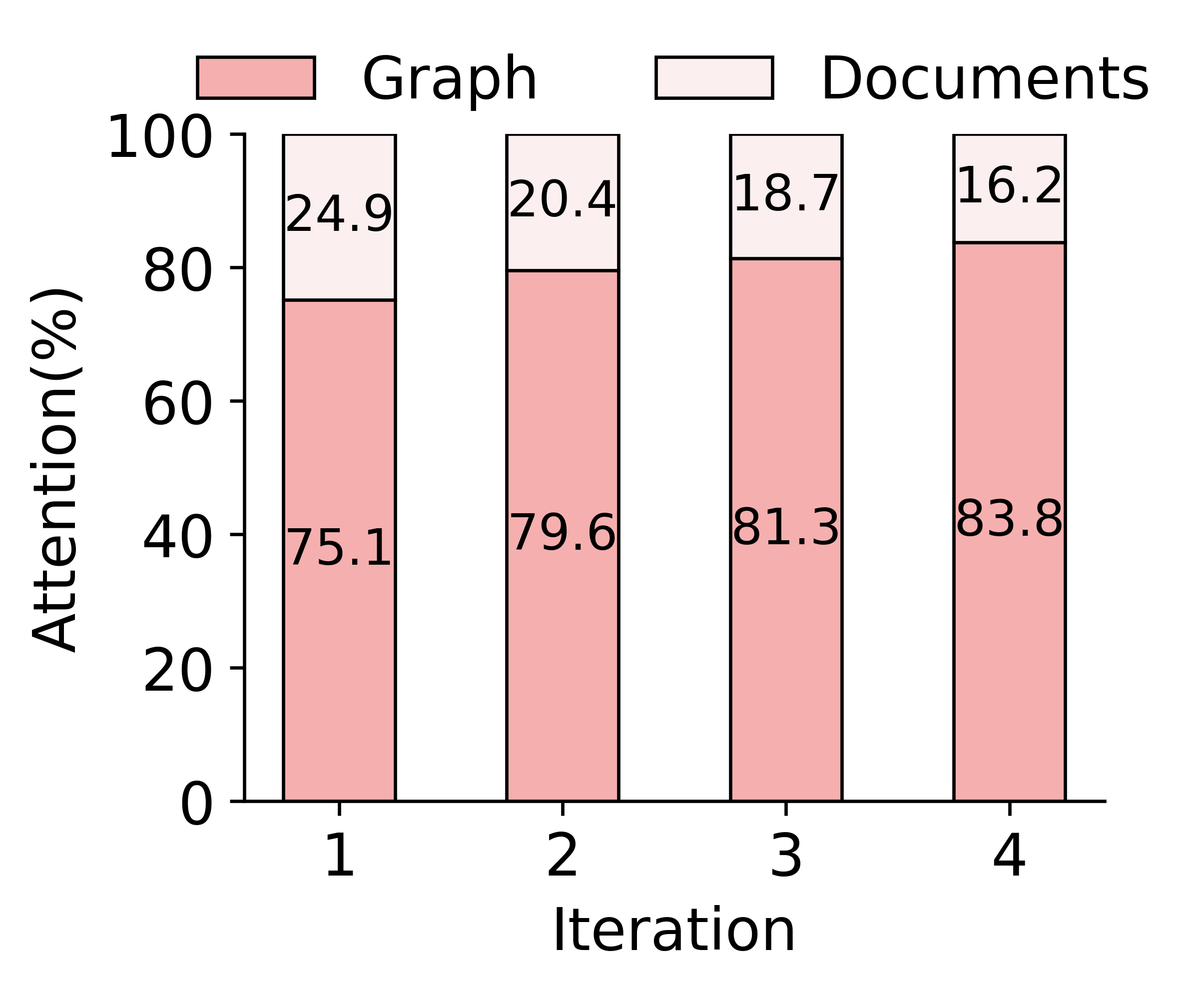
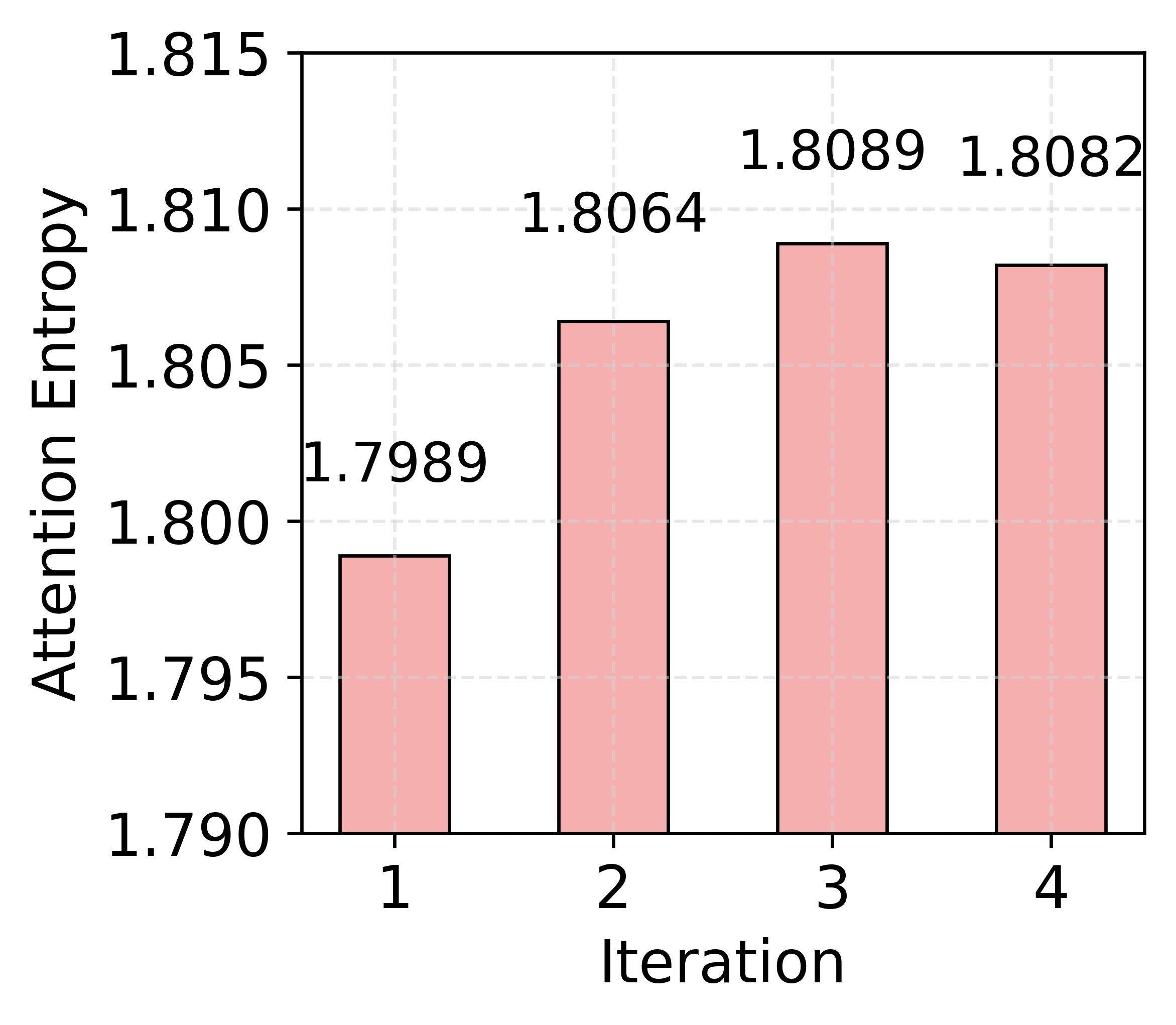
Figure 5: Attention distribution over documents and graphs in GraphAnchor indicating the growing prominence of the knowledge graph in LLM reasoning.
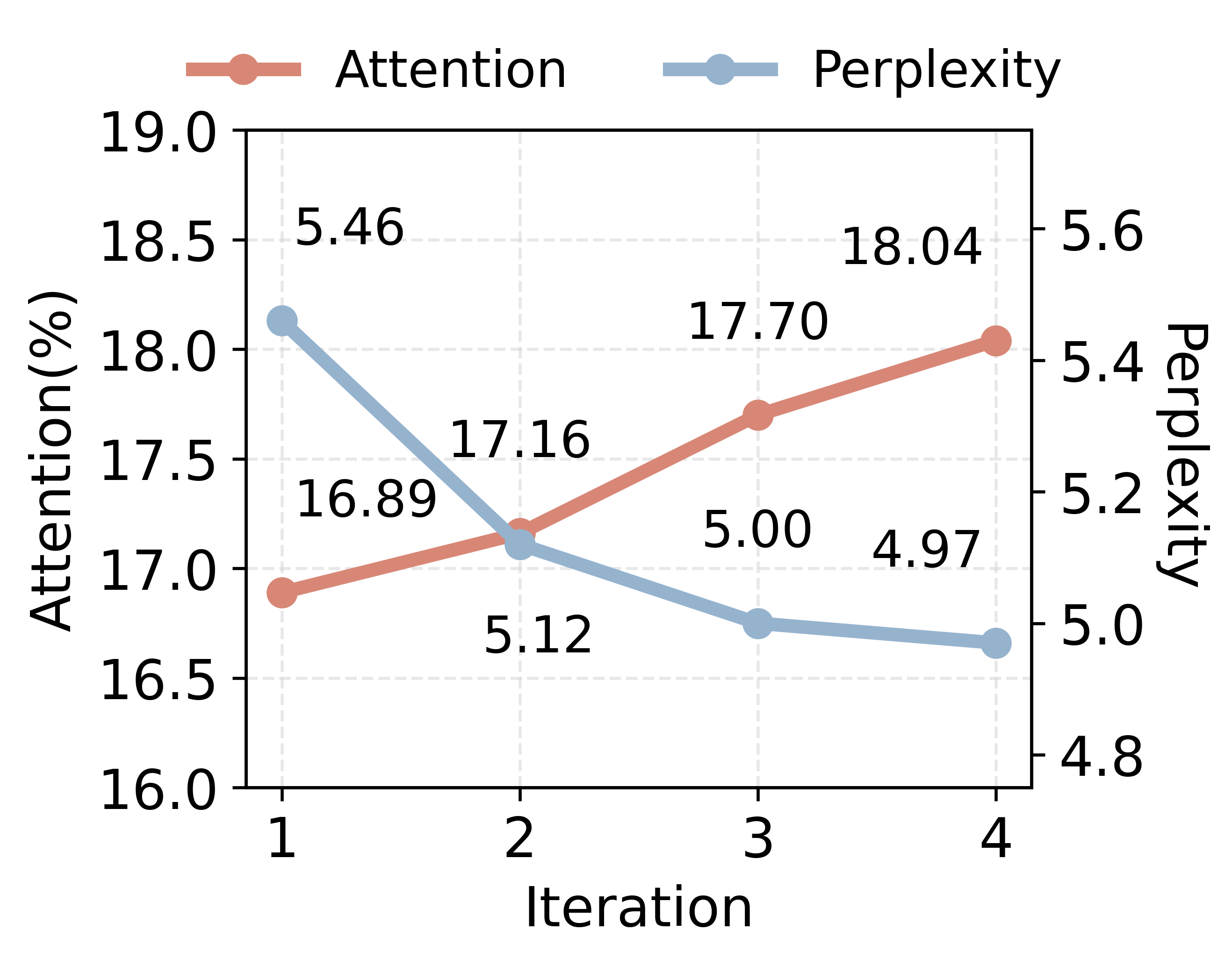
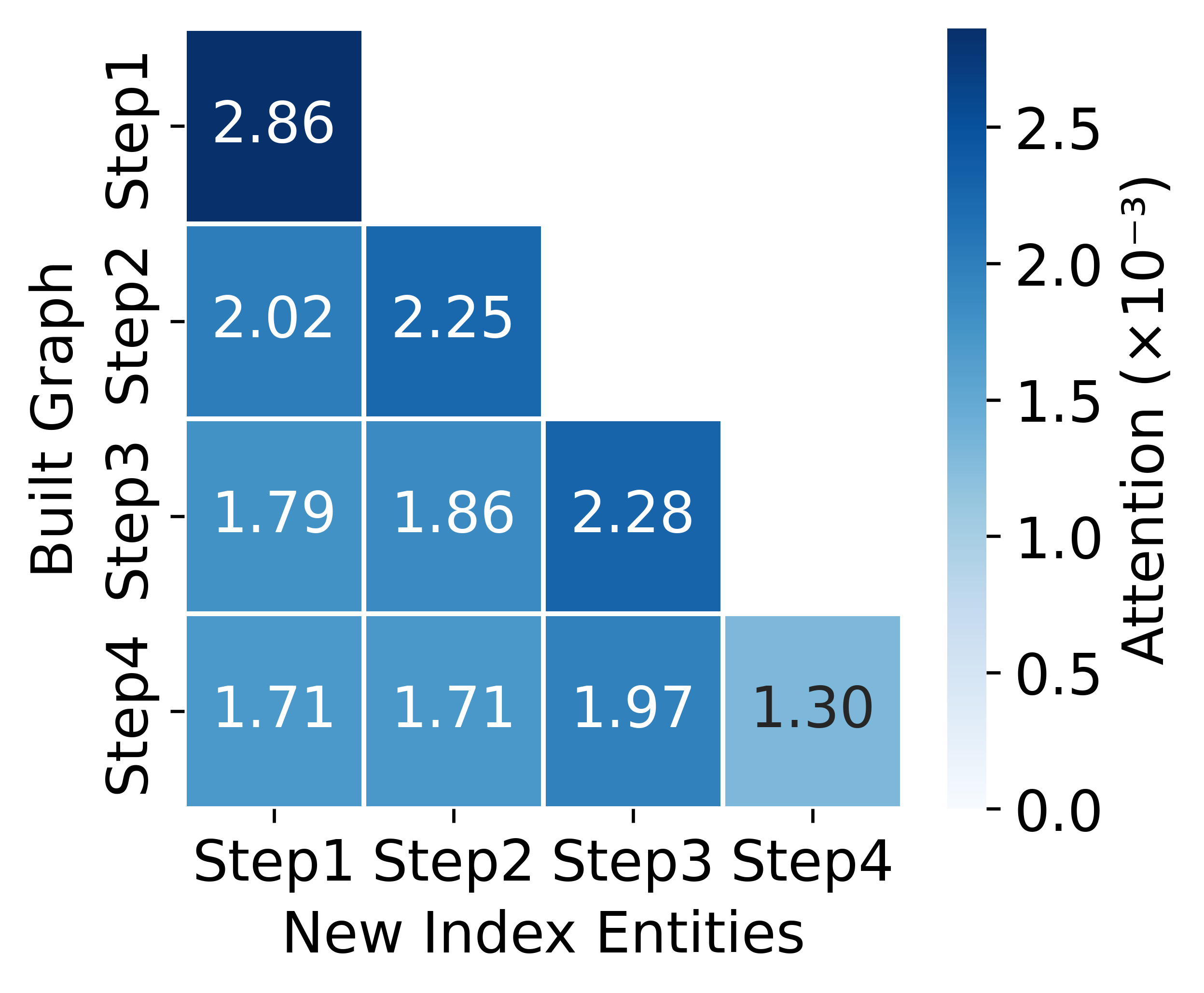
Figure 6: Attention over indexed entities highlighting the direct guidance of QA by stepwise graph anchoring.
Case Studies and Practical Implications
Attention visualizations demonstrate that GraphAnchor yields concentrated, context-aware attention on critical supporting evidence, enabling correct answer derivation where vanilla RAG is distracted or misled by irrelevant context.

Figure 7: In cases where both methods succeed, GraphAnchor displays more concentrated attention on relevant evidence.

Figure 8: GraphAnchor precisely anchors the answer even in complex queries handled correctly by both methods.
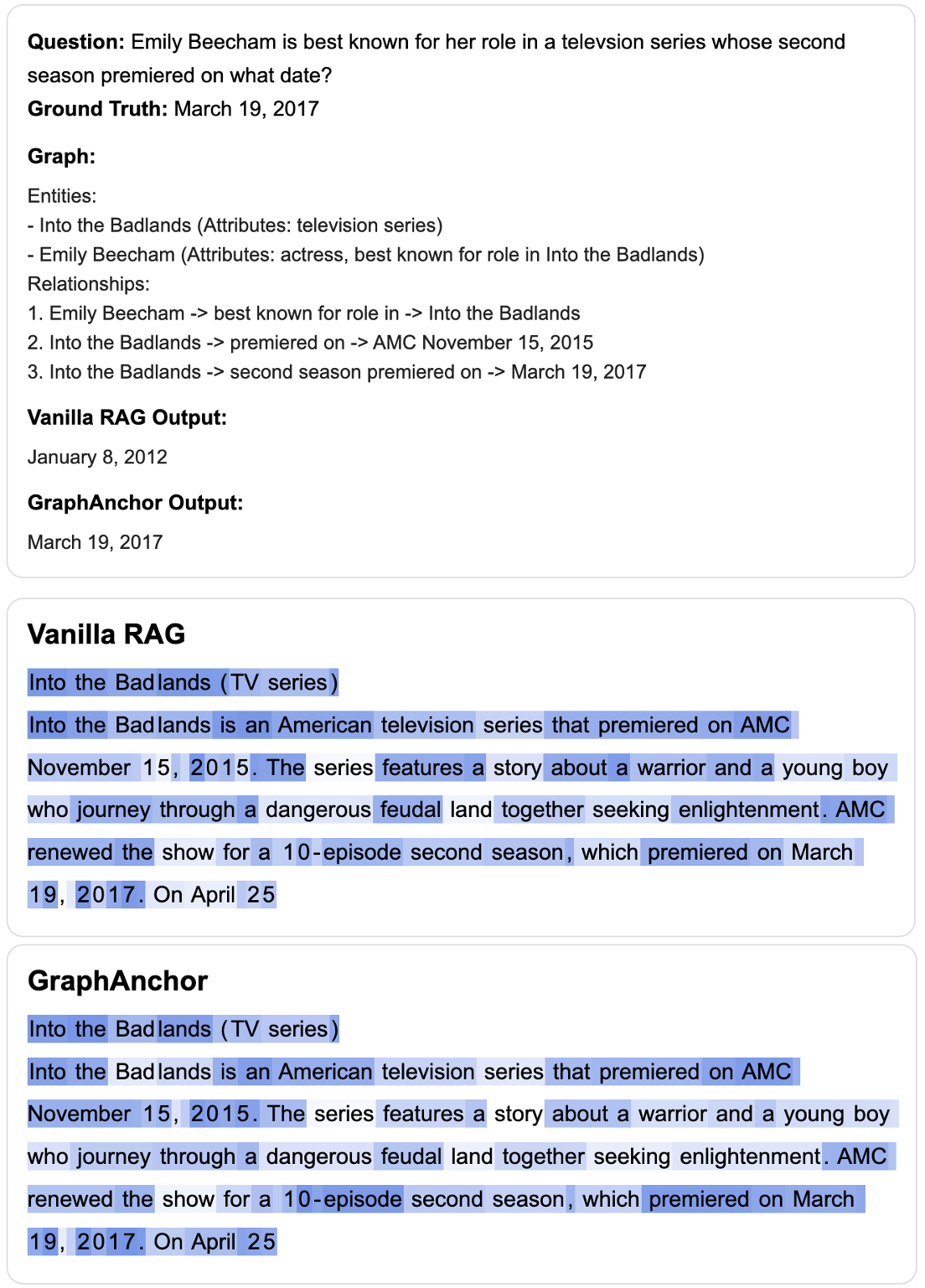
Figure 9: For challenging examples, GraphAnchor enables correct answers where vanilla RAG fails, by explicitly focusing on graph-anchored entities.

Figure 10: Additional cases where GraphAnchor's evidence anchoring corrects errors made by standard RAG.
The explicit graph construction also supports interpretable subquery generation and tracking of reasoning chains, which can facilitate broader applications in agentic multi-hop reasoning, tool-use, and explainable AI.
Theoretical and Practical Implications
GraphAnchor bridges deficiencies of prior iterative-RAG systems by (1) providing an explicit, dynamically maintained index of cross-document entities and relations, (2) improving robustness to noise accumulation, and (3) enabling structured reasoning over sparse, distributed evidence. The framework generalizes to any architecture supporting entity/relation extraction and can accommodate more sophisticated graph encoding methods, such as neural graph embeddings or hyper-relational structures.
The practical implications extend to high-stakes QA pipelines, scientific discovery agents, and settings where rationale transparency and resilience to hallucination are essential. Future work can explore tighter integration with active retrieval agents, rich graph encodings, and learning-to-index modules co-trained end-to-end within the RAG loop.
Conclusion
GraphAnchor operationalizes graph-anchored knowledge indexing as a core principle in retrieval-augmented generation, showing substantial gains in multi-hop QA. The evolving, context-driven graph index acts as both a reasoning substrate and an evidence aggregator, yielding superior attention patterns, increased retrieval diversity, and enhanced factuality. This structured approach opens new frontiers for interpretable, robust, and scalable LLM systems in knowledge-intensive tasks (2601.16462).