- The paper introduces a novel hybrid retrieval framework that bypasses traditional knowledge graphs by using path-based data augmentation.
- It fuses dense, sparse, and semantic indices with weighted reciprocal rank fusion to achieve significant improvements in recall and precision.
- Empirical evaluations on FinanceBench, Mini-Wiki, and SeaCompany demonstrate substantial gains and nearly an order-of-magnitude speed-up in online retrieval.
Path-Aligned Hybrid Retrieval without Knowledge Graphs: An Expert Analysis of Orion-RAG
Motivation and Problem Setting
Retrieval-Augmented Generation (RAG) pipelines, which combine IR techniques (dense or sparse) with LLMs, have demonstrated substantial efficacy on knowledge-intensive tasks. However, these frameworks face major obstacles in practical deployments where the underlying data is highly fragmented and lacks explicit relational structure—enterprise document repositories, regulatory filings, and operational logs are typical examples. Existing knowledge-graph-based solutions incur prohibitive computational costs for global construction and are brittle to frequent updates. Traditional RAG retrievers, in turn, often fail to bridge context gaps and suffer from lack of transparency for human auditing.
System Design and Path-Based Data Augmentation
Orion-RAG introduces a linear-complexity hybrid retrieval paradigm that sidesteps the need for explicit knowledge graphs. Its architecture centers on path-based data augmentation and multi-index retrieval. The Data Augmentation subsystem leverages LLM-driven dual-layer tagging agents to extract both global "Master Tags" (document-level) and fine-grained "Paragraph Tags" (chunk-level). These are concatenated into hierarchical "Semantic Paths" for each segment, yielding lightweight relational anchors that serve as navigational coordinates for downstream retrieval.
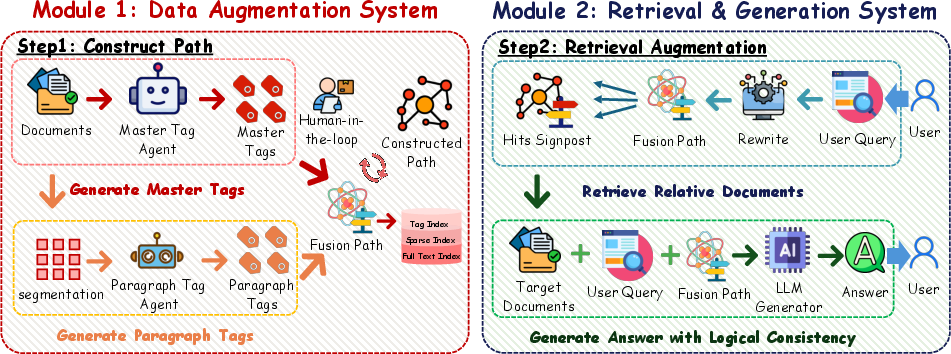
Figure 1: System overview of Orion-RAG, illustrating the dual-layer path-annotation subsystem and the hybrid retrieval pipeline leveraging sparse and dense indices guided by explicit semantic paths.
Path annotation and chunking are strictly local and incremental—no global recursive clustering or knowledge graph construction is required—enabling real-time updates and efficient HITL verifiability. This strategy creates ephemeral, human-readable graph surrogates that act as indexable structures for both automated and expert-driven optimization.
Hybrid Retrieval with Weighted Fusion and Pruning
The retrieval system of Orion-RAG is a multi-stage pipeline. User queries are first expanded by a rewriting agent to optimize coverage across both lexical and semantic search spaces. Each sub-query is used to query three parallel indices:
- Tag Index (dense embedding of semantic paths)
- Dense Text Index (standard dense representation)
- Sparse Index (BM25 inverted index for exact match retrieval)
Candidates from all three are fused with a Weighted Reciprocal Rank Fusion (RRF) mechanism, integrating path, semantic, and sparse ranks. Importantly, a pruning stage filters irrelevant or spurious results, leveraging explicit path structures as anchors for context disambiguation and redundancy suppression.
By prefixing context chunks passed to the generator with their semantic path, the system maximizes both explainability and precision by ensuring that the LLM can distinguish polysemous or homographic tokens across different document subspaces.
Empirical Evaluation and Numerical Results
Orion-RAG is evaluated across diverse settings: FinanceBench (long-form financial QA), Mini-Wiki (synthetic general knowledge), and SeaCompany (highly fragmented Southeast Asian firm profiles). Key comparative baselines include standard dense, sparse, and hybrid retrieval (RRF), as well as agent-based/recursive approaches (ReAct, DeepSieve, RAPTOR).
Orion-RAG consistently outperforms baselines on both recall and precision across all evaluation regimes. On FinanceBench at k=10, Orion-RAG achieves a Hit Rate of 97.3% and a Precision improvement of 25.2% relative to the strongest baseline, a substantive gain that confirms effective noise suppression without sacrificing coverage.
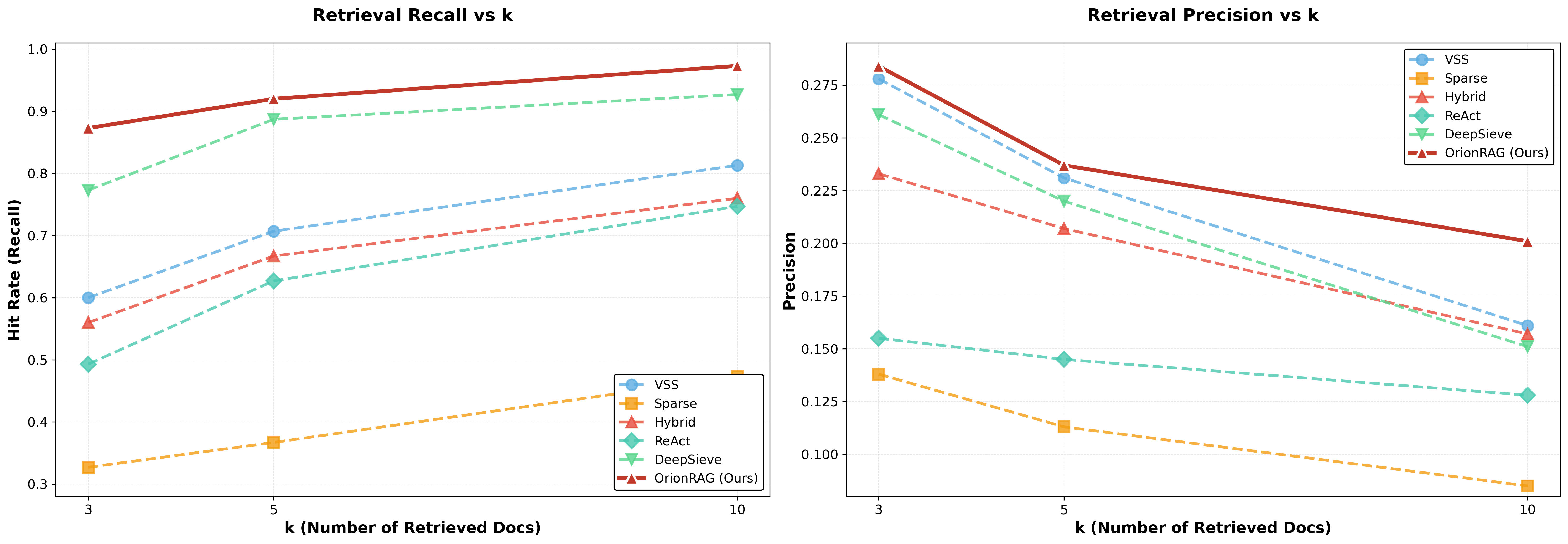
Figure 2: Retrieval Performance Comparison. Orion-RAG achieves superior Hit Rate and Precision compared to all baselines across datasets.
Ablation demonstrates that chunk size and path expressiveness are critical: 500-character chunks yield optimal retrieval by balancing context completeness and semantic specificity; further increases dilute signal-to-noise, while aggressive micro-chunking degrades coverage.
Downstream generation quality is assessed using BERTScore (F1) and ROUGE-L. Orion-RAG improves both factual faithfulness and semantic coherence; for instance, on FinanceBench, it reaches a 12.35% gain in ROUGE-L over RAPTOR, and leads Mini-Wiki and SeaCompany as well.
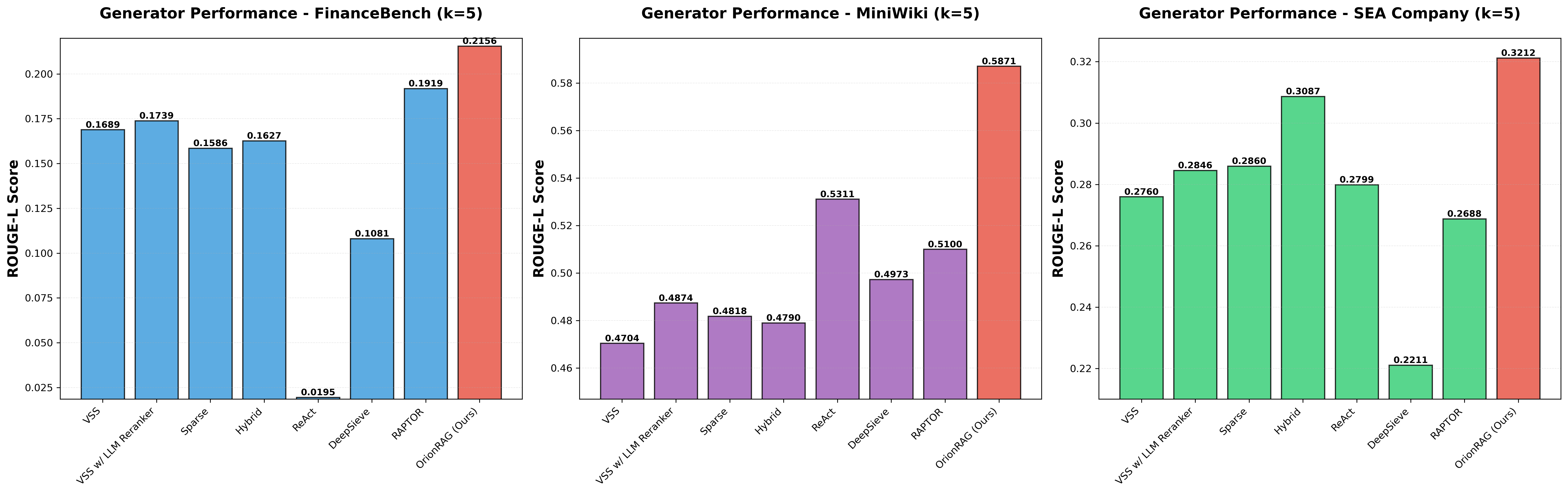
Figure 3: Generation Performance Comparison. Orion-RAG demonstrates superior semantic alignment and factual accuracy compared to prior methods.
Notably, Orion-RAG maintains high performance even for fragmentary, disconnected domains—where baseline systems relying on shallow chain-of-thought, recursive summarization, or naive fusion degrade sharply.
Scalability, HITL Support, and Runtime
The architectural efficiency of Orion-RAG affords robust scalability for enterprise deployment. Unlike graph-based or agentic RAGs, which require either global structure reconstruction or expensive multi-step reasoning loops, Orion-RAG processes are strictly local, with overall complexity O(N). Runtime studies on the SeaCompany benchmark show Orion-RAG achieves nearly an order-of-magnitude speed-up in online retrieval compared to ReAct and DeepSieve under concurrent loads.
Furthermore, the system supports interpretable, fine-grained HITL optimization. Modifying or injecting tags directly impacts retrieval outcomes. For instance, domain expert addition of a missing entity-specific tag demonstrably reduces the retrieval distance for target queries, enabling targeted rectification without global index maintenance.
Theoretical and Practical Implications
Orion-RAG re-frames the retrieval problem for graphless data by leveraging induced path structures that are sufficiently expressive to encode local relational context, without incurring the rigidity or computational burden of traditional KGs. This approach generalizes across domains with diverse topologies, from monolithic reports to highly fragmented corpora.
Theoretically, the methodology demonstrates that for many real-world RAG deployments, the marginal utility of complex graph construction is minimal when effective hierarchical tagging and path annotation are available. Practically, Orion-RAG delivers production-ready throughput and supports explicit human intervention, addressing longstanding accountability and transparency concerns in enterprise LLM systems.
Limitations and Future Directions
Current limitations include sensitivity to tag extraction quality (i.e., reliance on the presence of salient entities and well-defined paragraphs) and hyperparameter choices (chunk size, pruning thresholds). In highly abstract text where path annotation yields sparse signals, retrieval advantages diminish. As observed in ablation, domain-adaptive tuning is critical for optimal trade-off. Prompt design for tag/rewriter agents remains an open area for robustness improvement.
Future research may address automatic hyperparameter selection, integration with adaptive prompt optimization, and extension to domains characterized by noisier or lower-density semantic signals (e.g., legal or clinical narratives).
Conclusion
Orion-RAG introduces a robust, cost-efficient, and interpretable framework for retrieval-augmented generation on fragmented, graphless corpora, demonstrating substantial empirical and practical benefits over both naive and graph/agentic RAG variants. By capturing document structure via lightweight local path annotation and hybrid search, Orion-RAG enables high-precision, scalable QA and knowledge synthesis in real-world enterprise contexts, while supporting explicit HITL interventions for system transparency and control (2601.04764).