- The paper presents Adaptive Parallel Decoding (APD) that dynamically adjusts parallel token generation to improve speed over traditional autoregressive methods.
- APD integrates a smaller autoregressive model to assess joint token probabilities, effectively balancing marginal and joint distributions.
- Experiments demonstrate that APD boosts throughput while maintaining high-quality results, making diffusion LLMs viable for time-sensitive applications.
Accelerating Diffusion LLMs via Adaptive Parallel Decoding
Introduction
The paper "Accelerating Diffusion LLMs via Adaptive Parallel Decoding" introduces a novel technique, Adaptive Parallel Decoding (APD), aimed at enhancing the generation speed of diffusion LLMs (dLLMs). The current bottleneck in text generation lies in autoregressive decoding, which predicts tokens sequentially. Diffusion models, while theoretically capable of parallel generation, face quality degradation when exploiting full parallelism without additional modifications. APD addresses these challenges by dynamically adjusting the number of tokens sampled in parallel.
Background
Diffusion LLMs (dLLMs) present an intriguing alternative to autoregressive models, offering potential for parallelized token generation. dLLMs are inspired by the mechanisms of image diffusion models and seek to reverse the noise process added to data sequences. A core limitation is that dLLMs generate tokens based on marginal probabilities, often neglecting inter-token dependencies that autoregressive models inherently capture. Thereby, maintaining quality in parallelized generation poses a significant challenge.

Figure 1: Autoregressive vs Adaptive Parallel Decoding (APD).
Methodology
Adaptive Parallel Decoding (APD): APD redefines the decoding paradigm for dLLMs by integrating a smaller autoregressive model to evaluate joint token probabilities. The critical insight is that rather than fixing a predetermined number of tokens to generate in parallel, APD adaptively decides the parallelizable token count based on a "multiplicative mixture" of marginal and joint token probabilities. This approach allows APD to maintain fidelity to the target text distribution while efficiently sampling in parallel.
The procedure hinges on a universal coupling mechanism using shared randomness to sample from a target distribution, achieving a balance between generation speed and quality. Algorithmically, APD requires three tunable parameters: the multiplicative mixture weight, the recompute KV window, and the maximum masked lookahead. These parameters provide flexibility in managing the trade-off between throughput and quality.
Optimization Enhancements: The methodology also incorporates architectural optimizations such as KV caching and limiting the masked input size, which are traditionally used in autoregressive models to improve computational efficiency. By extending these techniques, APD significantly enhances the practical throughput of dLLMs.
Experimental Results
The experiments conducted validate that APD can deliver high throughput with minimal quality loss across tasks such as GSM8K. The findings highlight that for small values of the mixture weight parameter, the algorithm achieves impressive token parallelism rates while maintaining high generation quality (Figure 2).
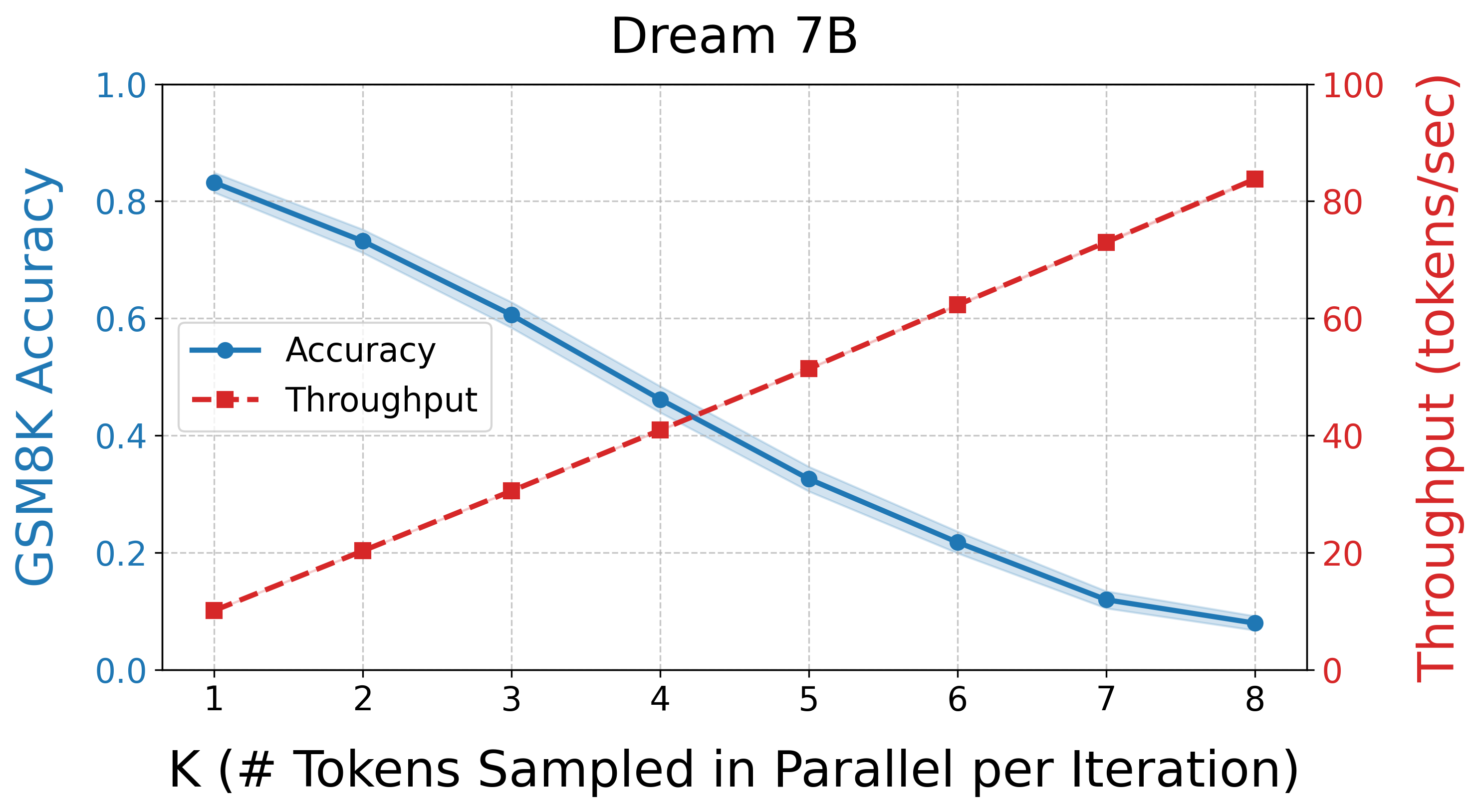
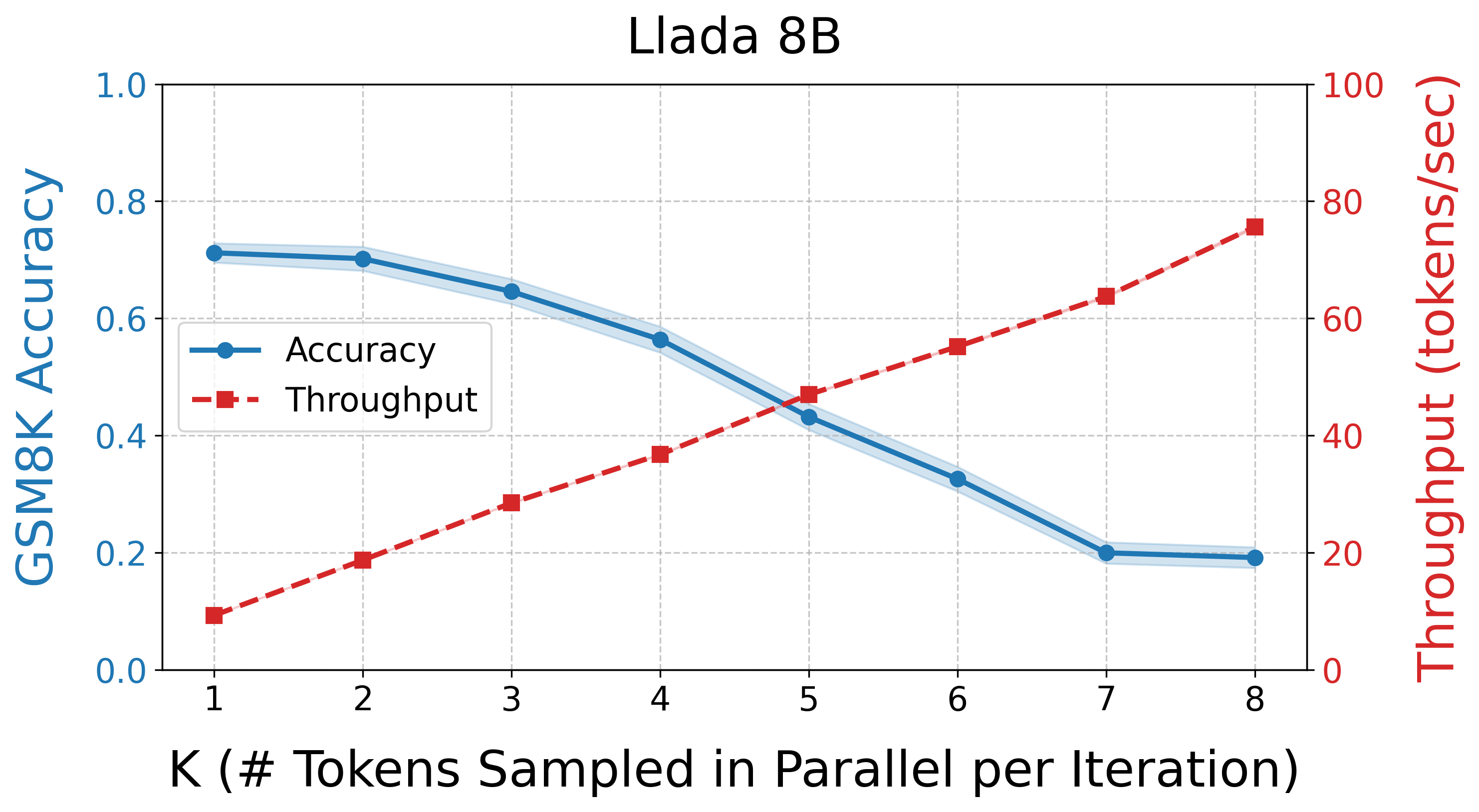
Figure 2: Naive Parallel Generation. The tradeoff between parallelization and generation quality in diffusion models.
The Pareto frontier analysis demonstrates that APD offers a unique position by providing optimal configurations in terms of speed and quality. APD-enabled dLLMs not only outpace baseline dLLMs but also match and exceed the efficacies of autoregressive LLMs under certain configurations.
Conclusion
The introduction of Adaptive Parallel Decoding represents a tangible advancement in the field of LLM generation, offering a mechanism to reconcile the inherent parallel capabilities of diffusion models with the strong dependency modeling of autoregressive approaches. By doing so, APD enables dLLMs to be considered viable contenders in time-sensitive applications. Future research could explore further integration of APD with other architectural innovations and broader applications beyond standard benchmarks, potentially redefining efficient LLM deployment.

