LLaDA2.1: Speeding Up Text Diffusion via Token Editing
Abstract: While LLaDA2.0 showcased the scaling potential of 100B-level block-diffusion models and their inherent parallelization, the delicate equilibrium between decoding speed and generation quality has remained an elusive frontier. Today, we unveil LLaDA2.1, a paradigm shift designed to transcend this trade-off. By seamlessly weaving Token-to-Token (T2T) editing into the conventional Mask-to-Token (M2T) scheme, we introduce a joint, configurable threshold-decoding scheme. This structural innovation gives rise to two distinct personas: the Speedy Mode (S Mode), which audaciously lowers the M2T threshold to bypass traditional constraints while relying on T2T to refine the output; and the Quality Mode (Q Mode), which leans into conservative thresholds to secure superior benchmark performances with manageable efficiency degrade. Furthering this evolution, underpinned by an expansive context window, we implement the first large-scale Reinforcement Learning (RL) framework specifically tailored for dLLMs, anchored by specialized techniques for stable gradient estimation. This alignment not only sharpens reasoning precision but also elevates instruction-following fidelity, bridging the chasm between diffusion dynamics and complex human intent. We culminate this work by releasing LLaDA2.1-Mini (16B) and LLaDA2.1-Flash (100B). Across 33 rigorous benchmarks, LLaDA2.1 delivers strong task performance and lightning-fast decoding speed. Despite its 100B volume, on coding tasks it attains an astounding 892 TPS on HumanEval+, 801 TPS on BigCodeBench, and 663 TPS on LiveCodeBench.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
LLaDA2.1: A simple explanation
What is this paper about?
This paper introduces LLaDA2.1, a new way for a LLM to generate text much faster while keeping the quality high. It does this by not only “writing” words but also “editing” them on the fly, so the model can fix mistakes as it goes. The team shows two modes you can choose from: a faster “Speedy Mode” and a more careful “Quality Mode.”
What questions are the researchers trying to answer?
They focus on three main goals:
- How can we make text generation faster without making the output worse?
- Can the model fix its own mistakes during generation, instead of waiting until the end?
- Can we give users control to pick between speed and quality depending on what they need?
How does it work? (Using everyday comparisons)
Think of writing an essay in two different ways:
- Autoregressive writing (typical LLMs): You write one word at a time, carefully checking each step. This is accurate but slower.
- Diffusion writing (dLLMs like LLaDA): You fill in many blanks in parallel and refine them. This is faster but can make more small mistakes.
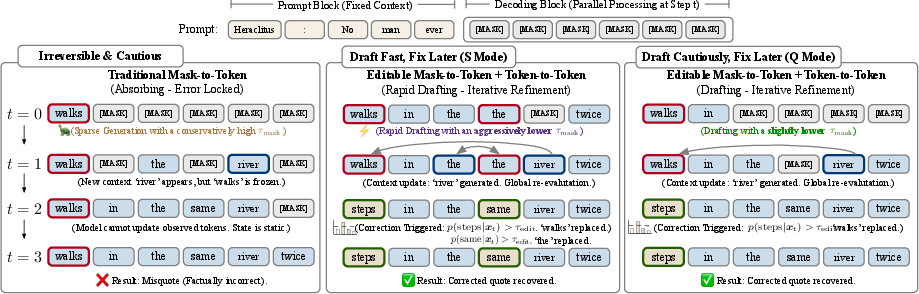
LLaDA2.1 adds a clever “Draft-and-Edit” system:
- Mask-to-Token (M2T): Filling in blanks with likely words (drafting).
- Token-to-Token (T2T): Replacing a wrong word with a better one (editing).
The model uses two “confidence thresholds” to decide:
- If the model is confident enough, it fills a blank (M2T).
- If it sees a word that’s probably wrong and has a better candidate, it edits it (T2T).
By tuning these thresholds, you get:
- Speedy Mode (S): Lower thresholds, draft quickly, rely more on edits to fix mistakes.
- Quality Mode (Q): Higher thresholds, be conservative, make fewer mistakes upfront.
Training and alignment:
- The model is trained to be good at both drafting and editing. It learns to fill blanks and to correct noisy or wrong tokens.
- They also use Reinforcement Learning (RL) to improve reasoning and instruction-following. In simple terms, RL rewards the model for better answers, using a stable math trick (called ELBO) to estimate progress without breaking the system.
Engineering for speed:
- Specialized software and hardware tricks speed things up: mixture-of-experts kernels, lightweight number formats (FP8), attention optimized for long contexts, and smart caching.
- During inference (the model answering your prompt), it uses threshold rules and can even revisit earlier parts (“Multi-Block Editing”) to fix past mistakes when new context arrives.
What did they find?
Across 33 benchmarks, LLaDA2.1 is both fast and strong:
- The big 100B model (LLaDA2.1-Flash) achieved very high throughput in coding:
- Around 892 tokens per second (TPS) on HumanEval+
- About 801 TPS on BigCodeBench
- About 663 TPS on LiveCodeBench
- Speedy Mode boosts speed a lot, with only small drops in scores on many tasks.
- Quality Mode often beats the older LLaDA2.0 in accuracy, with acceptable speed.
- Multi-Block Editing improves scores across reasoning and coding, with only a modest speed cost.
- Different domains vary: coding is fastest; instruction-following is slower.
Why this matters:
- You can choose the mode that fits your job: fast drafting for coding or math, more careful generation for complex instructions or general chat.
- It shows that “editable” diffusion models can be both efficient and smart, instead of trading one for the other.
What’s the bigger impact?
This approach suggests a new path for future AI models:
- Instead of just generating text in one direction, models can quickly draft and then correct themselves, which is more like how people write.
- Giving users control over speed vs. quality makes AI more practical for real tasks (coding assistants, long documents, agent workflows).
- The RL method they scale for diffusion models could boost reasoning and following instructions over time.
Limitations and what’s next:
- There’s still a speed-vs-accuracy trade-off. You may need to adjust thresholds per domain (code vs chat).
- Parallel generation can introduce more small errors; editing helps, but it’s not perfect yet.
- They plan to deepen the editing abilities and combine them even more tightly with RL to improve reliability and quality.
In short, LLaDA2.1 shows that letting a model “draft fast and edit smart” can make text generation both speedy and strong—and gives you the steering wheel to pick what you care about most.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated, actionable list of what remains missing, uncertain, or unexplored in the paper. Items are grouped to aid follow-up research.
Decoding and editing dynamics
- Lack of principled rules for setting or adapting dual thresholds and ; no automatic, task-aware or token-wise scheduling policy is provided.
- No sensitivity analysis or robustness study of decoding performance to small changes in / across tasks, lengths, and languages.
- Absence of mechanisms to detect and prevent oscillatory edits (e.g., token flipping, loops, “stuttering”) beyond qualitative mention; no anti-cycling heuristics or convergence criteria are defined.
- Unclear stopping criteria for editing passes within a block and across blocks (maximum edits, confidence margins, or edit budget).
- No analysis of when T2T edits help or harm (e.g., editing previously correct tokens) and how to control edit selectivity to reduce collateral changes.
- No formal characterization of the editable-state transition process (e.g., fixed points, mixing time, convergence guarantees) relative to absorbing-state diffusion.
- No evaluation of calibration of under the editable regime; thresholds rely on model confidence that may be miscalibrated without temperature scaling or post-hoc calibration.
- Missing comparison between single-pass aggressive drafting + edits vs. multi-pass conservative drafting (same compute budget) to understand optimal compute allocation.
Training objectives and data
- Unspecified noise schedules and perturbation distributions for the T2T “editing stream,” risking a train–test mismatch between random perturbations and realistic decoding errors.
- No ablations quantifying the marginal gains from each training component (M2T vs. T2T, MTF augmentation, CPT vs. SFT).
- MTF (Multi-turn Forward) augmentation details are absent (data selection, turn count, perturbation types); no analysis of how MTF affects editability or domain-specific gains.
- Data composition, domain balance, and changes relative to LLaDA2.0 are not described; this prevents isolating the effect of the new objectives.
- No study of how much edit exposure is needed (edit frequency/intensity) to achieve robust post-hoc correction without overfitting to synthetic noise patterns.
Reinforcement learning (EBPO) formulation and stability
- Limited mathematical detail on ELBO-based Block-level Policy Optimization (EBPO) (e.g., variance properties, bias relative to true gradients, convergence behavior).
- No ablations on EBPO hyperparameters (clip ranges, timestep set , weights ) or sensitivity to reward scaling and advantage estimation.
- Missing comparison of EBPO to other RL baselines (e.g., off-policy estimators, REINFORCE variants, actor–critic with value baselines) under matched compute.
- Unclear reward design and coverage (reasoning, instruction following, safety); no breakdown of which capabilities benefit most from RL vs. SFT.
- No study of credit assignment across blocks and long horizons in block-causal settings; unclear whether EBPO adequately propagates distant rewards.
- Lack of reporting on sample efficiency, compute cost, and carbon footprint for scaling RL to 100B parameters.
Inference algorithm and Multi-Block Editing (MBE)
- MBE lacks algorithmic details: how many revisits, selection policy for blocks to edit, and termination conditions beyond empirical TPF/TPS reporting.
- No analysis of MBE’s latency variance, worst-case tail behavior, and predictability for real-time applications.
- Missing study of memory footprint and KV-cache churn induced by cross-block revisits in very long contexts.
- No error taxonomy showing which error types MBE corrects vs. fails to correct; absence of per-step edit success rates.
- No exploration of adaptive MBE schedules that condition revisit depth on estimated uncertainty or utility.
Evaluation methodology and metrics
- Throughput is reported in TPF/TPS without end-to-end wall-clock latency breakouts (drafting vs. editing vs. MBE) for a fair operational comparison to AR baselines.
- Hardware, batch size, and kernel-level settings (e.g., megakernel, radix caching) are not fully standardized across comparisons; portability to other hardware/backends is untested.
- Missing human evaluations for instruction following and helpfulness–harmlessness–honesty; heavy reliance on automatic metrics may miss qualitative regressions.
- No length-conditioned analyses (short vs. long inputs/outputs) to reveal where editing provides the most/least benefit.
- Lack of per-domain threshold tuning protocols or automatic parameter search; reported domain variability is not linked to concrete tuning strategies.
- No open reproduction kit for the evaluation pipeline (prompts, seeds, decoding hyperparameters), making comparisons hard to replicate.
Robustness, generalization, and safety
- No stress tests on distribution shifts (domain, style, adversarial prompts) or low-resource languages; generalization of editability beyond English/Chinese remains unclear.
- No safety analysis of editing dynamics (e.g., whether post-hoc edits can bypass safety filters or amplify harmful content).
- Robustness to prompt injection or instruction conflicts during edits is not evaluated.
- No investigation of catastrophic edits (large unintended rewrites) and safeguards to preserve validated text spans or structural invariants (e.g., syntax- or schema-aware editing).
- Unclear behavior under extremely long contexts (near window limits) and agentic multi-turn settings where edits may interact with tool outputs.
Theoretical analysis and guarantees
- No formal link between editable diffusion dynamics and error-correction theory (e.g., conditions under which edits reduce expected risk).
- Absence of guarantees on monotonic improvement w.r.t. a surrogate objective when using dual thresholds and MBE.
- No analysis of the trade-off frontier between speed and fidelity in terms of information-theoretic bounds or optimal stopping criteria.
Systems and deployment considerations
- FP8 per-block quantization and Alpha-MoE megakernel are reported to help, but there is no study of accuracy–speed–stability trade-offs across tasks or calibration drift due to quantization.
- Portability to other accelerators (e.g., AMD, TPU) and smaller-memory devices is not examined; dependence on specific kernels may limit adoption.
- Energy efficiency and cost-per-token metrics are not reported; uncertain operational benefits vs. high parallelism overhead.
- Determinism and run-to-run variance with parallel editing are not quantified; production reproducibility policies are missing.
Comparisons and scope
- Limited comparisons to strong AR acceleration methods (speculative decoding, prefix LM/Medusa, edit-based AR) under matched hardware and budgets.
- No study combining editable diffusion with external verifiers (e.g., unit tests for code, symbolic checkers for math) to guide edits.
- Insufficient disentanglement of gains from T2T editing, MBE, quantization, and RL—their individual and combined contributions are not systematically ablated.
Practical guidance and usability
- No guidelines for selecting , , and MBE depth per domain/task; practitioners lack recipes for deployment-time tuning.
- Absence of monitoring metrics (e.g., live edit acceptance rate, edit oscillation count) that could drive adaptive control loops during inference.
These gaps suggest concrete next steps: develop adaptive thresholding policies with calibration, formalize editable diffusion dynamics, provide comprehensive ablations and RL details, design anti-oscillation safeguards, expand robustness/safety testing, standardize latency reporting, and release reproducible evaluation and tuning recipes.
Glossary
- Absorbing-state framework: A diffusion modeling setup where states transition monotonically from a special mask token to fixed tokens, preventing edits after unmasking. "the standard absorbing-state frameworkâwhich enforces a rigid, monotonic transition from to fixed tokensâfaces inherent limitations in fidelity."
- Advantage function: A reinforcement learning quantity that measures how much better an action is compared to the policy’s average expectation. "where is an estimator of the advantage function at timestep , quantifying the relative improvement of the chosen action over the average expectation under the current policy."
- Alpha-MoE: An optimized Mixture-of-Experts implementation that fuses expert computations into a single kernel to accelerate inference. "we integrate Alpha-MoE~\citep{alphamoe}, a MoE megakernel that combines the two FusedMoE computations into one kernel"
- AReaL framework: A reinforcement learning system used to orchestrate RL for LLMs, extended here for diffusion LLMs. "we extend the AReaL framework~\citep{fu2025areal, mei2025real} by developing specialized likelihood estimation and advantage estimation protocols"
- Autoregressive generation: A standard text generation approach where tokens are produced sequentially, each conditioned on previous outputs. "Discrete diffusion LLMs (dLLMs) have emerged as a compelling alternative to autoregressive generation"
- Block-autoregressive models: Models that generate in blocks with autoregressive dependencies, making certain RL computations difficult. "applying policy gradients to block-autoregressive models remains challenging due to the intractability of sequence log-likelihoods."
- Block-Causal Mask: An attention constraint ensuring each block can only attend to its valid past context. "Here, denotes a Block-Causal Mask ensuring the -th block attends only to valid history."
- Block diffusion LLMs: Diffusion-based LLMs that operate with block-level generation and decoding. "We further enable radix caching and batching support for block diffusion LLMs in SGLang."
- Block-diffusion models: Diffusion models that decode text in blocks rather than token-by-token. "LLaDA2.0 showcased the scaling potential of 100B-level block-diffusion models and their inherent parallelization"
- Block-level Policy Optimization (EBPO): A reinforcement learning framework using ELBO-based proxies to optimize policies at the block level in diffusion LLMs. "We circumvent this by adopting an ELBO-based Block-level Policy Optimization (EBPO) framework tailored for our editable setting."
- Block-wise causal masked attention: An attention mechanism that respects causality within blocks, enabling one-pass computation for long contexts. "To accelerate inference on long-context sequences, we adopt block-wise causal masked attention, allowing the KV cache for the entire long context to be computed in a single forward pass."
- Chain-of-thought reasoning: A reasoning style where models produce intermediate steps that can help self-correct errors. "autoreg models exhibit lower exposure bias and can self-correct through extended chain-of-thought reasoning."
- Clipped surrogate objective: An RL objective that clips probability ratios to stabilize training (similar to PPO). "Formally, we maximize a clipped surrogate objective, where the advantage is weighted by the probability ratio :"
- Continual Pre-Training (CPT): Ongoing pre-training to adapt the model to new objectives or data after initial training. "This objective is applied throughout both the Continual Pre-Training (CPT) and Supervised Finetuning (SFT) stages."
- Context window: The maximum length of input tokens a model can attend to during inference or training. "Furthering this evolution, underpinned by an expansive context window, we implement the first large-scale Reinforcement Learning (RL) framework"
- Discrete diffusion: A generative process over discrete symbols (tokens), iteratively refining masked or noisy states. "Specifically, we extend standard discrete diffusion to support it."
- dFactory: An infrastructure/toolkit providing efficient training recipes tailored for diffusion LLMs. "leveraging dFactory~\citep{dfactory}, which provides efficient training recipes specifically designed for dLLMs"
- dLLMs: Discrete diffusion LLMs that decode in parallel via diffusion over tokens. "Discrete diffusion LLMs (dLLMs) have emerged as a compelling alternative to autoregressive generation"
- Draft-and-Edit paradigm: A decoding approach that first drafts tokens and then edits them using thresholds and token-level corrections. "our framework introduces a dynamic ``Draft-and-Edit" paradigm controlled by dual probability thresholds."
- Editable State Evolution: A generalized diffusion framework where states can transition not only from mask to token but also between tokens. "we align with the direction of generalizing discrete diffusion beyond absorbing states \citep{rutte_generalized_2025} and propose a comprehensive framework for Editable State Evolution."
- Editing Set Δ_t: The set of token positions eligible for token-to-token updates at a timestep given an edit threshold. "We formalize the state evolution by defining two active update sets at timestep : the Unmasking Set and the Editing Set ."
- ELBO (Evidence Lower Bound): A lower bound on log-likelihood used as a tractable proxy for optimization in probabilistic models. "By utilizing the Evidence Lower Bound (ELBO) as a principled proxy for exact likelihood"
- Error-Correcting Editable decoding strategy: A decoding method with dual thresholds enabling both unmasking and token edits to fix errors. "we first design a novel Error-Correcting Editable decoding strategy, which introduces a dynamic paradigm controlled by dual probability thresholds."
- Exposure Bias: The compounding of errors when a model conditions on its own imperfect outputs during generation. "During LLM decoding, Exposure Biasâwhere errors compound as the model conditions on its own imperfect predictionsâis inevitable."
- FusedMoE: A fused computation scheme for Mixture-of-Experts layers that reduces overhead by combining kernels. "a MoE megakernel that combines the two FusedMoE computations into one kernel"
- KV cache: Cached key/value attention states used to accelerate decoding over long contexts. "allowing the KV cache for the entire long context to be computed in a single forward pass."
- Mask-to-Token (M2T): An operation that fills masked positions with predicted tokens during diffusion decoding. "By seamlessly weaving Token-to-Token (T2T) editing into the conventional Mask-to-Token (M2T) scheme"
- Mixture of M2T and T2T objective: A training objective combining both unmasking and token-edit tasks to align with draft-and-edit inference. "we employ a unified Mixture of M2T and T2T objective."
- MoE megakernel: A single optimized GPU kernel that executes multiple Mixture-of-Experts operations efficiently. "a MoE megakernel that combines the two FusedMoE computations into one kernel"
- Multiple Block Editing (MBE): A mechanism allowing edits across previously generated blocks based on new content. "we further introduce a Multiple Block Editing (MBE) mechanism."
- Non-monotonic reasoning: Reasoning where outputs can revise or backtrack rather than strictly proceed forward. "offering the potential for non-monotonic reasoning and parallel decoding."
- Parallel decoding: Generating multiple tokens simultaneously rather than sequentially. "Discrete diffusion LLMs (dLLMs) have emerged as a compelling alternative to autoregressive generation, offering the potential for non-monotonic reasoning and parallel decoding."
- Per-block FP8 quantization: Low-precision quantization applied at the block level to speed inference with limited accuracy loss. "and adopt per-block FP8 quantization to balance the inference speed and model accuracy."
- Policy gradients: RL methods that compute gradients of expected rewards with respect to policy parameters. "applying policy gradients to block-autoregressive models remains challenging due to the intractability of sequence log-likelihoods."
- Probability ratio ρ: The ratio between new and old policy probabilities used to weight advantages in clipped objectives. "where the advantage is weighted by the probability ratio :"
- Quality Mode (Q Mode): A conservative decoding configuration using higher thresholds to prioritize output quality. "Quality Mode (Q Mode), which leans into conservative thresholds to secure superior benchmark performances with manageable efficiency degrade."
- Radix caching: A caching technique designed to accelerate block diffusion inference and batching. "We further enable radix caching and batching support for block diffusion LLMs in SGLang."
- Reinforcement Learning (RL): An optimization paradigm that updates policies based on rewards and advantages, here scaled for diffusion LLMs. "we implement the first large-scale Reinforcement Learning (RL) framework specifically tailored for dLLMs"
- Remasking: Reintroducing mask tokens based on confidence to mitigate errors in parallel decoding. "confidence-based remasking \citep{wang_remasking_2025}"
- Retroactive correction: Editing previously drafted outputs to fix errors after initial generation. "Aggressive parallel drafting, backed by retroactive correction, accelerates inference."
- Sequence-level log-likelihood: The probability of an entire output sequence under a model, often intractable for diffusion policies. "the intractability of the sequence-level log-likelihood, "
- SGLang: A system used for fast rollout and inference of (diffusion) LLMs with specialized features. "utilizes a customized version of SGLang~\citep{antgroupdeepxputeamPowerDiffusionLLMs} as the dedicated rollout engine."
- Speedy Mode (S Mode): A decoding configuration that lowers thresholds to maximize throughput, relying on edits for corrections. "the Speedy Mode (S Mode), which audaciously lowers the M2T threshold to bypass traditional constraints while relying on T2T to refine the output"
- Supervised Finetuning (SFT): A training phase where models learn from labeled data to improve task performance. "This objective is applied throughout both the Continual Pre-Training (CPT) and Supervised Finetuning (SFT) stages."
- Threshold Decoding: A decoding technique that only commits updates when confidence exceeds preset thresholds. "we adopt a decoding algorithm that combines Threshold Decoding~\citep{ma2025dinfer} with an explicit editing mechanism."
- Token-to-Token (T2T): An editing operation where an already generated token is replaced by another token during diffusion. "By seamlessly weaving Token-to-Token (T2T) editing into the conventional Mask-to-Token (M2T) scheme"
- Tokens per forward (TPF): The number of tokens processed or generated per model forward pass in diffusion LLMs. "For diffusion LLM, we report its scores across each benchmark along with its TPF (tokens per forward);"
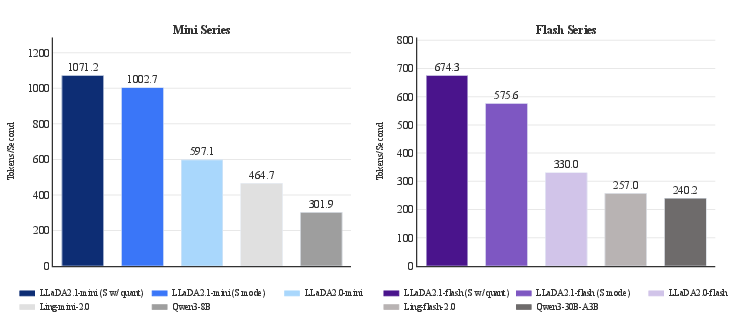
- Tokens per second (TPS): Throughput metric indicating how many tokens a system can generate per second. "after quantization, LLaDA2.1-flash achieves a peak TPS of 891.74 on HumanEval+"
- Transition operator: The operator that updates token states based on unmasking and editing sets during diffusion decoding. "The transition operator then applies the updates strictly on the union of these sets:"
- Unmasking Set Γ_t: The set of masked positions eligible to be filled with predicted tokens when confidence exceeds a mask threshold. "We formalize the state evolution by defining two active update sets at timestep : the Unmasking Set and the Editing Set ."
- Vectorized Likelihood Estimation: A method to compute likelihood bounds in parallel across blocks and timesteps to speed RL. "implementing Vectorized Likelihood Estimation~\citep{Blockdiffusion2025} to parallelize bound computation"
Practical Applications
Practical Applications of LLaDA2.1 (Editable Discrete-Diffusion LLMs)
LLaDA2.1 introduces a draft-and-edit decoding scheme with dual thresholds (Mask-to-Token and Token-to-Token), two user-facing personas (Speedy Mode and Quality Mode), scalable RL alignment via EBPO, and an optimized inference stack (SGLang-based, Alpha-MoE megakernel, FP8 quantization, block-causal attention, radix caching). These advances translate into high-throughput language generation with competitive quality, especially on structured domains (coding, math).
Below are actionable applications, grouped by deployment timeline and linked to sectors, with concrete tools/workflows and feasibility notes.
Immediate Applications
The following can be deployed with the released LLaDA2.1-Mini (16B) and LLaDA2.1-Flash (100B), leveraging S Mode for throughput and Q Mode/MBE when quality is paramount.
- [Software] Ultra-fast code assistants in IDEs
- Use cases: Autocomplete, function stubs, refactoring suggestions, unit-test synthesis, docstring generation, rapid “first draft then edit” coding.
- Tools/workflows: VS Code/JetBrains plugins calling LLaDA2.1 in S Mode for instant drafts, with local T2T edits and optional MBE for cross-file fixes; CI bots that regenerate failing snippets with T2T.
- Assumptions/dependencies: Access to LLaDA2.1 APIs; prompt templates for code tasks; threshold tuning by language; guardrails for unsafe code; optional retrieval for project context.
- [Software] High-throughput code review and PR bots
- Use cases: Auto-summarize diffs, detect anomalies, propose patches; first-pass linting and style alignment.
- Tools/workflows: GitHub/GitLab apps running S Mode for quick triage, Q Mode for final suggestions; T2T to revise earlier comments as more context is read (MBE).
- Assumptions/dependencies: Repository access; quality improves with domain-tuned thresholds and MBE; integration with test pipelines.
- [Data/Analytics] NL-to-SQL and data wrangling copilots
- Use cases: Dashboard query drafting, SQL rewriting, schema-mapping assistance.
- Tools/workflows: BI tool plugins (Tableau/Power BI/dbt) invoking S Mode to propose multiple query drafts, then T2T edits to correct syntax or schema mismatches; MBE to revise earlier clauses after seeing later joins/filters.
- Assumptions/dependencies: Schema metadata and example queries; stronger results on structured tasks align with paper’s benchmarks; human-in-the-loop recommended.
- [Customer Service/Contact Centers] Low-latency reply drafting and summarization
- Use cases: Live chat response suggestions, case summaries, escalation notes.
- Tools/workflows: Speed tiering—S Mode for near-real-time drafts, Q Mode for final customer-facing responses; T2T to fix tone/policy mismatch after tool calls (function-calling alignment evaluated via BFCL/Nexus FC).
- Assumptions/dependencies: Safety/policy constraints; domain-specific threshold presets; content moderation and audit logs.
- [Education] Math and programming tutors with instant hints
- Use cases: Step-wise hints, solution verification, code debugging exercises.
- Tools/workflows: S Mode for immediate hinting; Q Mode for final solutions; T2T to correct intermediate steps; configurable thresholds per topic difficulty.
- Assumptions/dependencies: Curriculum-aligned prompts; monitoring for hallucinations on open-ended questions; educator review for graded outputs.
- [Enterprise Knowledge/QA] Fast RAG assistants for internal documents
- Use cases: FAQ answering, policy lookup, SOP drafting with citations.
- Tools/workflows: Two-pass generation—S Mode for draft + T2T edits post-retrieval; MBE to revise earlier sections when new evidence is retrieved later.
- Assumptions/dependencies: High-quality retrieval; citation enforcement; threshold tuning higher (Q Mode) for non-structured topics.
- [Developer Productivity] Latency-tiered generation as a product feature
- Use cases: User-selectable “Speed” vs “Quality” modes in apps; dynamic SLAs.
- Tools/workflows: Expose and as configuration per endpoint; auto-switch to Q Mode on safety-critical prompts.
- Assumptions/dependencies: Telemetry for error rates; domain-based presets; A/B testing to set defaults.
- [Platform/Infra] Inference cost reduction and throughput scaling
- Use cases: Serve more concurrent sessions per GPU for structured workloads (coding/math).
- Tools/workflows: Deploy with SGLang extensions, Alpha-MoE megakernel, FP8 per-block quantization, block-causal attention, radix caching; batch large job queues (bulk drafting, translations).
- Assumptions/dependencies: GPU support for FP8; quality checks post-quantization; ops capability for kernel upgrades.
- [Content Operations] Bulk content drafting with retroactive consistency
- Use cases: Product descriptions, variant rewrites, localization templates.
- Tools/workflows: S Mode for speed; T2T/MBE to unify style terms and fix inconsistencies across batches; terminology constraints injected as post-edit rules.
- Assumptions/dependencies: Style guides; constraint-checkers; final human review for brand safety.
- [Research/Academia] RL for diffusion LLMs via EBPO
- Use cases: Reproducible alignment experiments at scale; curriculum design for editing behavior; new benchmark studies on exposure bias.
- Tools/workflows: EBPO training loop with Vectorized Likelihood Estimation; dFactory/ASystem/SGLang stack; MTF augmentation for editable supervision.
- Assumptions/dependencies: Access to training infra and datasets; compute budget; evaluation baselines across 33+ benchmarks.
- [Governance/Policy Teams] Draft-and-edit workflows with auditable revisions
- Use cases: Draft policy memos, compliance checklists with iterative corrections.
- Tools/workflows: Keep S Mode for brainstorming; switch to Q Mode or apply MBE for final drafts; store T2T edit traces as provenance for audits.
- Assumptions/dependencies: Human approval gates; retrieval of authoritative sources; stricter thresholds for sensitive content.
- [Long-context Knowledge Work] Fast first-pass analysis over large corpora
- Use cases: Legal e-discovery triage, long document summarization, codebase overviews.
- Tools/workflows: Block-wise KV precompute for long contexts; S Mode to skim and mark sections; T2T/MBE to refine earlier summaries as later sections are read.
- Assumptions/dependencies: Memory/caching configured; content privacy controls; acceptance of minor quality tradeoffs during triage.
Long-Term Applications
These require further research, robustness gains, tighter safety controls, or deeper product integration (e.g., editing integrated into RL, dynamic threshold policies).
- [Software] Self-correcting continuous integration copilots
- Vision: An agent that drafts code, runs tests/builds, and uses T2T/MBE to patch failures in-place across files.
- Emerging tools: “Test-then-edit” pipelines; patch stack management via cross-block edits.
- Dependencies: Reliable tool-use, sandboxed execution, stronger guarantees on regression avoidance.
- [Robotics/Autonomy] Editable plan synthesis and retroactive replanning
- Vision: Generate action plans rapidly (S Mode), then refine earlier steps based on new constraints via MBE.
- Emerging tools: Plan verifiers that trigger T2T corrections; block-causal memory for long-horizon tasks.
- Dependencies: Real-world safety layers; grounding/perception integration; low-latency control loops.
- [Finance] Compliance-aware function-calling agents
- Vision: Trading/ops assistants that revise order parameters post-checks (T2T) and maintain audit trails of edits.
- Emerging tools: Policy engines that adjust / by risk; immutable edit logs.
- Dependencies: Stronger instruction-following guarantees; regulator-approved testing; domain RL finetuning.
- [Healthcare] Clinical documentation assistants with self-correction
- Vision: Draft notes rapidly and retroactively fix codes, medications, and dates as new info appears.
- Emerging tools: EHR-integrated T2T edits; terminology and safety checkers that trigger edits.
- Dependencies: Medical-grade validation; HIPAA/GDPR compliance; high accuracy thresholds (Q Mode) and rigorous human oversight.
- [Legal/Government] High-fidelity statutory/citation drafting
- Vision: Rapid drafting with post-hoc correction of citations and definitions; transparent provenance of edits.
- Emerging tools: Retrieval-verifier loops that trigger T2T edits; policy dashboards showing edit diffs.
- Dependencies: Verified RAG; citation correctness metrics; legal review workflows.
- [Education] Personalized, mastery-based tutoring with adaptive thresholds
- Vision: The system tunes / per learner profile—fast hints when confident, conservative mode on novel topics.
- Emerging tools: Threshold-policy learners; skill model integration.
- Dependencies: Robust calibration; fairness and bias checks; educator dashboards.
- [Platform/Infra] Autotuning “threshold policies” for domain and user intent
- Vision: Systems that learn to set decoding thresholds dynamically from telemetry (latency, error rates, user feedback).
- Emerging tools: Bandit/RL controllers for decoding persona selection; SLO-aware routers.
- Dependencies: High-quality feedback signals; safety constraints to avoid over-aggressive S Mode in sensitive contexts.
- [On-device/Edge AI] Diffusion-LLM assistants with specialized hardware
- Vision: High-parallelism decoding running at the edge with FP8 or lower precision and fused kernels.
- Emerging tools: Mobile/edge runtimes with block-diffusion primitives; offline code/math helpers.
- Dependencies: Hardware support for quantization; memory-optimized KV caching; model distillation.
- [Safety/Alignment] Editing-integrated RL (future work flagged by authors)
- Vision: Train policies that explicitly reward accurate self-correction, reducing exposure bias and hallucinations.
- Emerging tools: EBPO variants with edit-aware rewards; synthetic editing curricula (MTF) at scale.
- Dependencies: Stable gradient estimation for edit operations; high-quality reward models and benchmarks.
- [Enterprise KM/Agent OS] Cross-document retroactive consistency maintenance
- Vision: Agents that maintain consistent terminology and facts across large knowledge graphs by editing prior outputs as new info emerges.
- Emerging tools: MBE-backed global consistency checkers; corpus-level “style/fact synchronization” passes.
- Dependencies: Versioned content stores; change management; human-in-the-loop approval.
- [Public Sector/Policy] Procurement and governance templates for speed–quality SLAs
- Vision: Standardize when to use S Mode vs Q Mode, how to audit T2T edits, and how to log provenance for accountability.
- Emerging tools: Compliance profiles that fix thresholds per task type; evaluation harnesses for benchmark-aligned acceptance testing.
- Dependencies: Cross-agency standards; legal frameworks for AI-assisted drafting; audit infrastructure.
Cross-cutting Assumptions/Dependencies
- Domain sensitivity to thresholds: The paper reports best speed/quality trade-offs on structured domains (code, math). General chat/instruction following may require conservative thresholds (Q Mode) or MBE.
- Infrastructure availability: Many speed gains depend on SGLang modifications, Alpha-MoE megakernel, FP8 per-block quantization, block-causal attention, and radix caching.
- Safety and governance: For regulated sectors (health, finance, legal), human oversight, retrieval verification, and logged edit provenance are essential.
- Model access and licensing: Deployment depends on access to LLaDA2.1-Mini/Flash under suitable licenses, and optionally dFactory/ASystem for training or EBPO alignment.
- Cost-performance tuning: Quantization may slightly affect scores; organizations should validate quality post-quantization and calibrate / per workload.
- Latency vs quality controls: Multi-Block Editing improves quality with modest throughput cost; choosing S vs Q Mode and enabling MBE should be governed by task criticality.
Collections
Sign up for free to add this paper to one or more collections.