Structured Decomposition for LLM Reasoning: Cross-Domain Validation and Semantic Web Integration
Abstract: Rule-based reasoning over natural language input arises in domains where decisions must be auditable and justifiable: clinical protocols specify eligibility criteria in prose, evidence rules define admissibility through textual conditions, and scientific standards dictate methodological requirements. Applying rules to such inputs demands both interpretive flexibility and formal guarantees. LLMs provide flexibility but cannot ensure consistent rule application; symbolic systems provide guarantees but require structured input. This paper presents an integration pattern that combines these strengths: LLMs serve as ontology population engines, translating unstructured text into ABox assertions according to expert-authored TBox specifications, while SWRL-based reasoners apply rules with deterministic guarantees. The framework decomposes reasoning into entity identification, assertion extraction, and symbolic verification, with task definitions grounded in OWL 2 ontologies. Experiments across three domains (legal hearsay determination, scientific method-task application, clinical trial eligibility) and eleven LLMs validate the approach. Structured decomposition achieves statistically significant improvements over few-shot prompting in aggregate, with gains observed across all three domains. An ablation study confirms that symbolic verification provides substantial benefit beyond structured prompting alone. The populated ABox integrates with standard semantic web tooling for inspection and querying, positioning the framework for richer inference patterns that simpler formalisms cannot express.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Structured Decomposition for LLM Reasoning: A Simple Explanation
Overview
This paper is about making AI better at following strict rules when reading and understanding text. In areas like law, medicine, and science, decisions must be clear, explainable, and correct. Big LLMs, like ChatGPT, are great at understanding messy text, but they sometimes make mistakes and don’t give guarantees. Symbolic systems (think formal logic and rule engines) are great at applying rules correctly but need clean, structured input.
The authors propose a way to combine both: use LLMs to turn unstructured text into structured facts, and then use a rule engine to apply the rules with reliable results. They test their idea across three areas: deciding if something is hearsay in law, checking if a scientific method is used for a task, and determining if someone qualifies for a clinical trial.
Key Objectives
The paper aims to answer three simple questions:
- Can we split the reasoning process into clear steps (find important things, extract facts, check rules) so AI becomes more reliable?
- Can LLMs fill in a structured “fact sheet” from text that a rule engine can use to make decisions?
- Does this approach work in different fields (law, science, medicine), and does it beat standard prompting techniques?
How the Method Works (With Simple Analogies)
Think of the system as a team with two specialists and a shared rulebook:
- The rulebook: An ontology (OWL 2) and rule set (SWRL).
- Ontology is like a well-organized dictionary plus a blueprint for the domain: it defines the kinds of things that exist (classes), their properties, and how they relate.
- In ontology terms:
- TBox = the “definitions and rules” section (like the glossary and how things fit together).
- ABox = the “filled-in fact sheet” for this specific case.
- SWRL rules are “if-then” statements placed on top of the ontology (e.g., “If a statement was made outside court and is used to prove it’s true, then it’s hearsay.”).
- Specialist 1: The LLM (the translator and fact-finder)
- It reads messy text (like legal scenarios or clinical criteria) and:
- Identifies entities (who said what, which method, which task, which patient condition).
- Extracts assertions (which relationships or properties hold, like “said outside court” or “method applied to task”).
- It writes these as structured facts into the ABox (the fact sheet).
- Specialist 2: The rule engine (the referee)
- A symbolic reasoner (like Pellet) checks the facts against the SWRL rules.
- It decides the final classification (e.g., “This is hearsay” or “This method is applied to that task”) deterministically—that means it gives the same answer every time for the same facts.
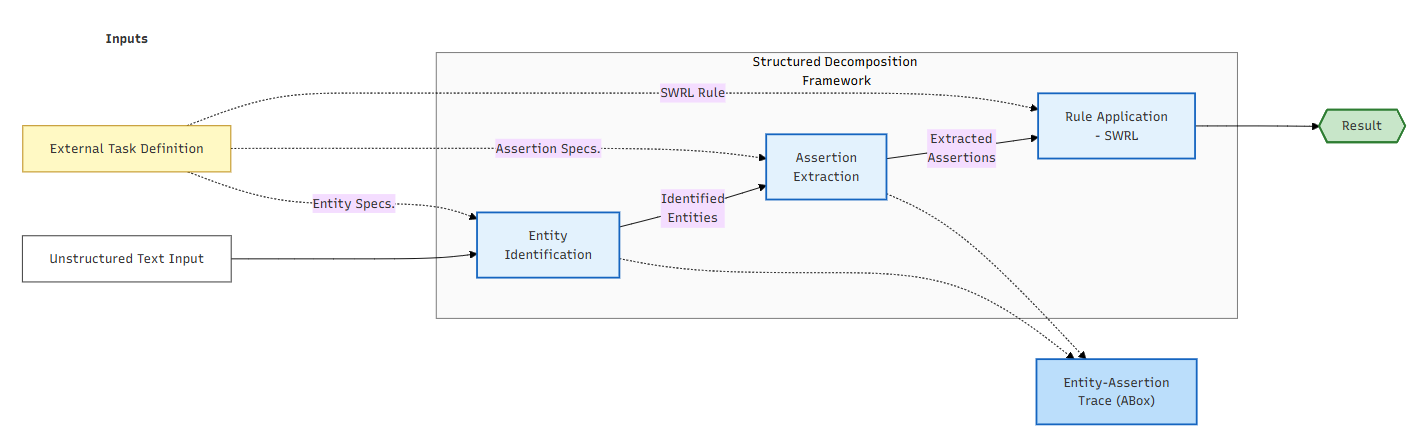
To make this clear, the authors break the process into three steps:
- Entity identification: Finding the “who/what” in the text (like spotting “the witness’s statement” or “the method named Tree Adjoining Grammar”).
- Assertion extraction: Deciding what is true about those entities (like “the statement happened out of court,” or “the method is actually used for the task”).
- Symbolic verification: Applying the formal rules to those extracted facts for a reliable decision.
A helpful detail: Because in the ontology world “unknown” doesn’t mean “false” (called the open-world assumption), the authors sometimes use paired checks (like “is out of court” and “is in court”) to force the LLM to be explicit. This reduces mistakes where the model assumes something that wasn’t actually stated.
Main Findings and Why They Matter
Here’s what their experiments showed across law, science, and medicine, using many different LLMs:
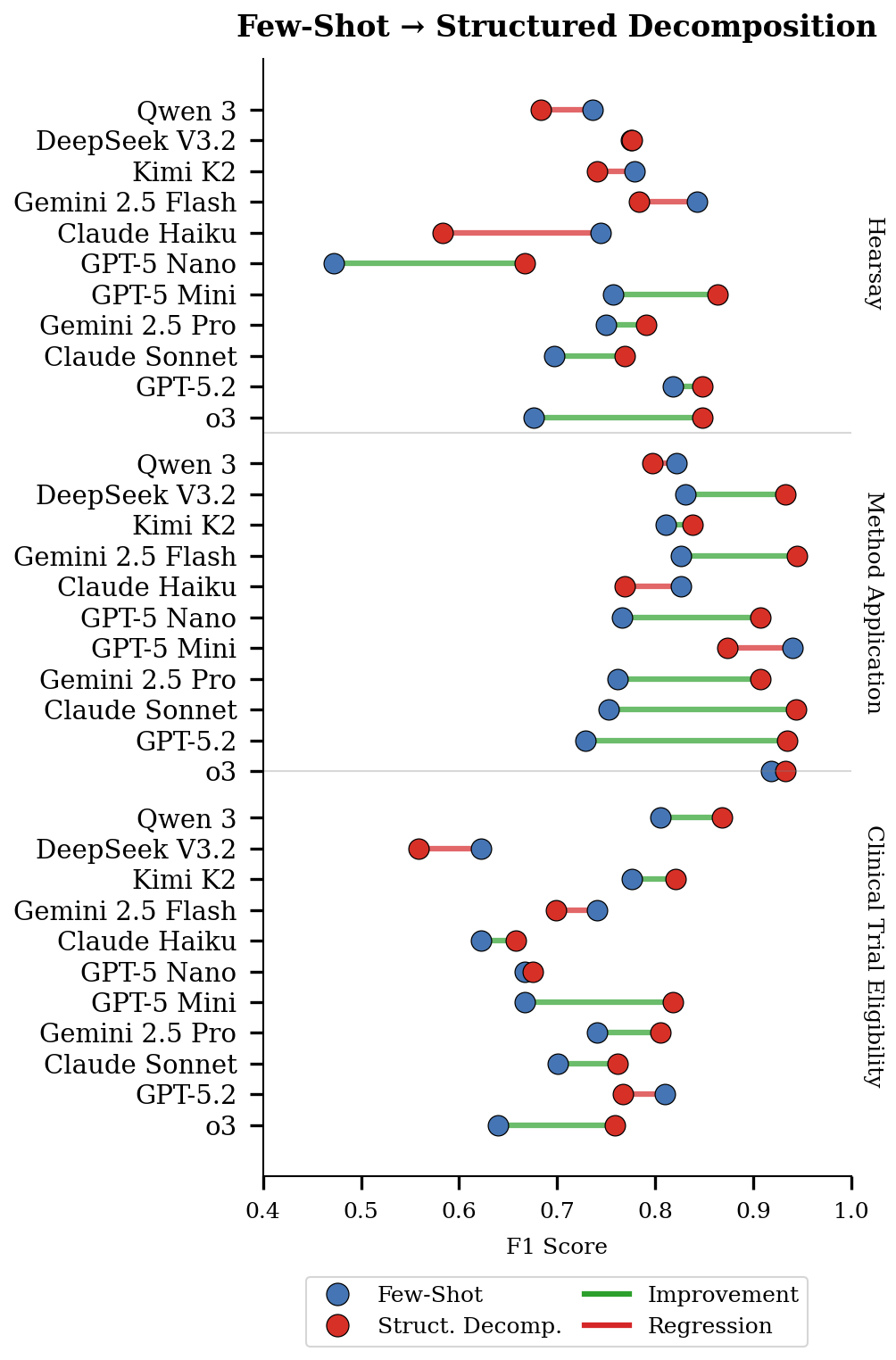
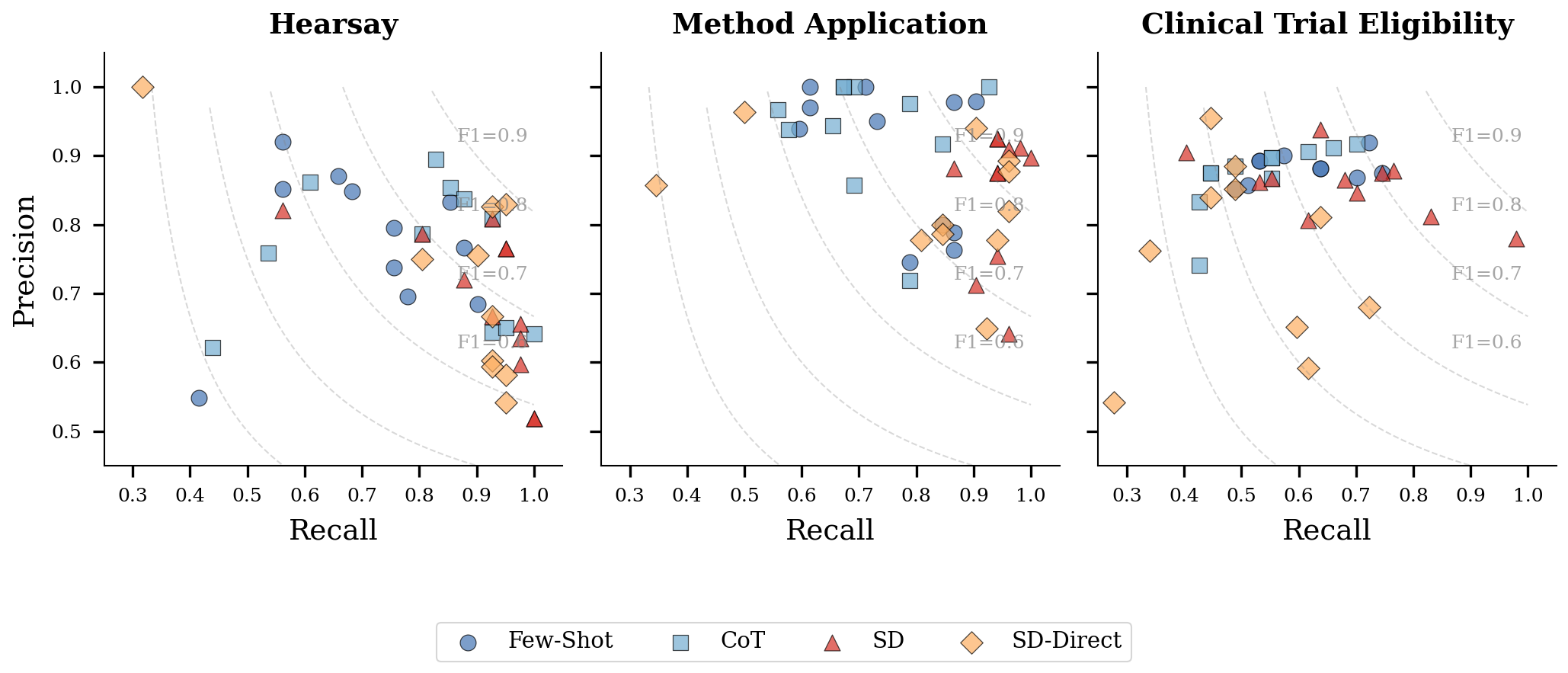
- The structured decomposition approach (split into steps and verify with rules) performs better than standard few-shot prompting overall. “Few-shot prompting” is when you just give the LLM a handful of examples and ask it to generalize.
- Symbolic verification (the rule engine step) adds real value beyond just better prompting. In other words, it’s not only about structuring the prompts; it’s the formal rule check that boosts reliability.
- This method works across different domains: legal hearsay decisions, scientific method-to-task application, and clinical trial eligibility reasoning all improved.
- The system produces an audit trail. Every extracted “fact” and decision is stored in the ABox, so experts can inspect how the text was interpreted and why the final decision was made. This is important for accountability.
- Limits: The approach is designed for tasks where clear rules exist and can fully determine the outcome. When the “boundary” is statistical (e.g., diagnosing a condition with overlapping symptoms and no fixed rule), this method does not help. The authors tested such a case (URTI diagnosis) and found that logical rules were not enough; pattern-based methods worked better there.
Implications and Impact
This research suggests a practical path to more trustworthy AI in rule-heavy areas:
- In law: More consistent decisions about evidence (like hearsay), with explanations you can audit.
- In science: Clearer identification of whether a method is actually used for a task, not just mentioned nearby.
- In medicine: Better checking of who qualifies for trials based on inclusion/exclusion criteria.
Because the approach uses semantic web standards (OWL and SWRL), it plugs into existing tools for viewing, querying (SPARQL), and extending knowledge bases. That means it can be reused, shared, and scaled more easily than custom, one-off logic formats.
In short: Let the LLM handle messy text; let the rule engine handle strict logic. Together, they produce results that are both flexible and trustworthy—exactly what’s needed when decisions must be clear, auditable, and correct.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a concise list of concrete knowledge gaps and limitations that remain open for future work to address:
- Scalability of OWL/SWRL reasoning at corpus scale: benchmark memory, latency, and incremental reasoning on large ABoxes; assess streaming/partitioned inference strategies.
- Open-world vs. closed-world tension: systematically compare SWRL-only reasoning to SHACL/closed-world validation; study how absence, negation, and defaults should be modeled; quantify when complementary predicates help or harm.
- Conflict handling in the ABox: define detection and resolution policies when LLMs assert both a predicate and its complement; explore integrity constraints, paraconsistent reasoning, and assertion confidence scoring.
- Robustness to paraphrase and adversarial phrasing: measure stability of outcomes under controlled rewordings across all domains; develop paraphrase-invariant extraction prompts.
- Stepwise error decomposition: report precision/recall for entity identification and assertion extraction separately; quantify error propagation and identify dominant failure modes per task.
- Evidence grounding and explanation faithfulness: anchor assertions to exact text spans (character offsets) and evaluate whether provided explanations faithfully justify the extracted ABox facts.
- Human-in-the-loop workflows: design and evaluate review interfaces, active-learning loops, and correction propagation to improve ABox quality and reduce expert burden.
- Ontology engineering effort and coverage: measure time/expertise to author TBox/SWRL rules; provide methods to assess rule completeness/coverage and to suggest missing predicates/rules.
- Integration with domain ontologies and standards: demonstrate end-to-end alignment with SNOMED CT, UMLS, OBO, or LegalRuleML; evaluate mapping quality and impact on reasoning.
- Synonymy and terminological variation: formalize how lexical resources (e.g., UMLS, WordNet) or embeddings are incorporated to handle clinical/legal synonymy; ablate their contributions.
- Defeasible and exception-heavy rules: many legal/clinical rules are non-monotonic; evaluate integrations with Defeasible Logic, ASP, argumentation frameworks, or probabilistic rules beyond SWRL.
- Temporal and numeric constraints: assess handling of time windows, sequences, and thresholds (e.g., “within 6 months”); test adequacy of SWRL built-ins versus specialized temporal reasoners.
- Beyond binary tasks: empirically validate multi-label/hierarchical classifications and compositional rule sets the ontology claims to support.
- Task suitability diagnostics: develop automated criteria/tests to determine whether a new task has a rule-expressible boundary and formalisable predicates before ontology investment.
- Stronger baselines and alternatives: compare against ReAct, PAL/code execution, self-consistency, retrieval-augmented prompting, NL2FOL+SMT, and SHACL-based validation.
- Model-related factors: report the 11 models used, sizes, licensing, and settings; analyze variance across models, temperature sensitivity, and open vs. closed models for reproducibility.
- Statistical power and significance: expand beyond small test sets (n≈94) and few-shot exemplars; provide power analyses, significance test details, and corrections for multiple comparisons.
- Multilingual generalization: test ontology population and SWRL reasoning on non-English corpora and cross-lingual settings; evaluate translation vs. native processing.
- Abstention and uncertainty: introduce “unknown/insufficient information” outcomes rather than defaulting to negative when predicates are missing; calibrate selective prediction.
- Cost and latency: quantify token costs and end-to-end runtimes for multi-step extraction plus reasoning; evaluate throughput and cost-performance trade-offs.
- Provenance and auditability: model assertion provenance (e.g., PROV-O) linking individuals and properties to source documents, spans, and LLM versions for verifiable audits.
- Privacy and security: address PHI handling and data governance for clinical text, especially when using external LLM APIs.
- Tooling/DevEx: standardize ontology annotations for prompt generation, create CI for ontology consistency, and provide reusable templates for new domains.
- Reasoner choice and DL-safety: compare Pellet vs. HermiT/FaCT++ and rule engines for SWRL support, DL-safety, and performance; document trade-offs and best practices.
- Learning with reasoner feedback: explore fine-tuning or iterative training where the reasoner’s outcomes supervise the extractor (e.g., self-training, RL from rule violations).
- Hybrid decision-making for partial-rule domains: combine symbolic guarantees with learned classifiers when rules are necessary but not sufficient; design principled fusion methods.
- Complementary predicates at scale: rigorously evaluate when they reduce bias/false positives across domains, and provide criteria for when to include them.
- SHACL-based validation: investigate SHACL shapes for closed-world quality checks and constraint validation as a complement or alternative to SWRL.
- Ontology evolution and versioning: study the impact of TBox changes on prompts and ABox stability; provide migration/versioning tools and backward-compatibility strategies.
Glossary
- ABox: The assertional component of an OWL ontology containing individuals and their property assertions. "translating unstructured text into ABox assertions according to expert-authored TBox specifications"
- Answer Set Programming: A declarative logic programming paradigm for non-monotonic reasoning. "where Answer Set Programming combined with graph knowledge bases enables enhanced collaborative reasoning capabilities"
- antecedent: The “if” part of a rule consisting of conditions that must hold for the rule to fire. "A SWRL rule takes the form: antecedent → consequent, where both antecedent and consequent are conjunctions of atoms."
- Chain of Logic prompting: A prompting method that separates rule-based reasoning into independent logical steps and recomposes them. "Servantez et al. introduced the Chain of Logic prompting method"
- Chain-of-Thought (CoT) prompting: A technique that elicits intermediate reasoning steps to improve multi-step inference. "Chain-of-Thought (CoT) prompting elicits intermediate reasoning steps"
- Closed-world assumption (CWA): The assumption that facts not known to be true are considered false. "This contrasts with databases and many logic programming systems that use the closed-world assumption (CWA)."
- Complementary predicates: Paired predicates encoding both positive and negative conditions to enforce explicit decisions. "A design pattern we investigate is the use of complementary predicates, paired assertions representing opposing determinations."
- Controlled natural language: A restricted subset of natural language designed to be machine-interpretable and unambiguous. "the InsurLE framework by Cummins et al. uses controlled natural language to codify insurance contracts"
- Description Logic: A family of formal knowledge representation languages underlying OWL. "This separation, rooted in Description Logic theory, maps naturally to our framework's distinction between task definitions (TBox) and extracted entities/predicates (ABox)."
- Entailment: A logical relation where a statement necessarily follows from given premises. "Entailment and Contradiction modeled as disjoint subclasses of EligibilityStatement."
- FaCT++: A Description Logic reasoner for OWL ontologies. "Several OWL reasoners are available, including Pellet, HermiT, and FaCT++."
- Federal Rules of Evidence: U.S. federal rules governing admissibility of evidence in court. "requires classifying whether a piece of evidence constitutes inadmissible hearsay under Rule 801 of the Federal Rules of Evidence."
- First-order logic (FOL): A formal logic with quantification over individuals used to represent and reason about statements. "translate natural language inputs into first-order logic representations"
- Hearsay: An out-of-court statement offered to prove the truth of the matter asserted (a legal evidentiary category). "defining Hearsay as a subclass of Statement captures the taxonomic relationship"
- HermiT: An OWL reasoner supporting classification, consistency checking, and expressivity. "Several OWL reasoners are available, including Pellet, HermiT, and FaCT++."
- Horn-like rules: Logic rules resembling Horn clauses, enabling rule-based inference over ontologies. "SWRL extends OWL with Horn-like rules, enabling inference patterns beyond OWL's native expressivity."
- Knowledge graph population: The process of extracting entities and relations from text to fill a knowledge base. "Knowledge graph population involves extracting entities and relations from text to populate a knowledge base"
- NL2FOL: A pipeline that translates natural language to first-order logic via structured steps and solver integration. "The work by Lalwani et al. on NL2FOL demonstrates a structured, step-by-step pipeline"
- Neural-Symbolic Integration: An approach that combines neural networks’ interpretive power with symbolic systems’ formal guarantees. "\keywords{LLMs \and Explainable AI \and Neural-Symbolic Integration \and Semantic Web}"
- NLI4CT: A dataset for natural language inference in clinical trial contexts. "We derive this benchmark from the NLI4CT dataset"
- Object property: An OWL construct representing binary relationships between individuals. "Object properties capture relationships between entities, with domain and range restrictions constraining valid assertions."
- Ontology alignment: The task of mapping semantically related entities across different ontologies. "Ontology alignment, mapping concepts between different ontologies, has similarly benefited from LLM capabilities."
- Ontology population: Adding individuals and assertions to an ontology according to its schema. "LLMs serve as ontology population engines, translating unstructured text into ABox assertions"
- Open texture: The inherent vagueness of many domain concepts that require interpretive flexibility. "accommodating the ``open texture'' inherent in many domain concepts"
- Open-world assumption (OWA): The assumption that lack of knowledge does not imply falsity in reasoning. "OWL reasoning operates under the open-world assumption (OWA): the absence of a statement does not imply its negation."
- owlready2: A Python library for working with OWL ontologies and reasoners. "We use the Pellet reasoner, which integrates with the owlready2 library used in our implementation."
- OWL 2: The W3C standard ontology language for defining classes, properties, and axioms. "We argue that OWL 2 ontologies with SWRL rules provide the right abstraction for this integration."
- Pellet: An OWL DL reasoner with support for SWRL rules and consistency checking. "We use the Pellet reasoner, which integrates with the owlready2 library"
- Prolog: A logic programming language commonly used for symbolic reasoning and rule execution. "a self-driven Prolog-based CoT mechanism"
- Protégé: A widely used ontology editor for building and maintaining OWL ontologies. "Task specifications become editable in tools such as Protégé"
- ReAct: A prompting paradigm that interleaves reasoning with tool use or actions. "ReAct interleaves reasoning and acting"
- Satisfiability Modulo Theory (SMT): A framework for deciding satisfiability of logical formulas with respect to background theories. "use Satisfiability Modulo Theory (SMT) solvers to reason about the logical validity of natural language statements."
- SciERC: A dataset of scientific abstracts annotated with entities and relations. "We derive this benchmark from the SciERC dataset"
- Semantic Web: A set of standards and technologies for machine-readable web data and reasoning. "grounded in semantic web standards"
- SPARQL: A query language for RDF and graph-structured data. "SPARQL queries can retrieve these assertions systematically"
- SWRL: The Semantic Web Rule Language that extends OWL with rule-based inference. "SWRL extends OWL with Horn-like rules, enabling inference patterns beyond OWL's native expressivity."
- TBox: The terminological component of an ontology defining classes, properties, and their relationships. "OWL ontologies consist of two components: the TBox (terminological box) defines classes, properties, and their relationships; the ABox (assertional box) contains individuals and their property assertions."
- Theory of Mind: Mechanisms modeling agents’ beliefs and intentions to enhance reasoning. "augmenting such systems with Theory of Mind mechanisms and structured critique yields synergistic improvements in reasoning quality"
Practical Applications
Immediate Applications
The paper’s structured decomposition (LLMs for ontology population + OWL/SWRL reasoning + inspectable ABox) enables deployable, auditable pipelines for rule-governed decisions over natural language. The following use cases can be implemented with today’s LLMs and standard semantic web tooling (Protégé, OWLReady2, Pellet/HermiT/FaCT++).
- Legal e-discovery hearsay filter
- Sector: Legal
- What it does: Flag and justify potential hearsay in depositions/filings by extracting statements and purposes from text, then applying SWRL hearsay rules with deterministic inference.
- Tools/workflow: Protégé-authored evidence ontology + SWRL; LLM API for entity/assertion extraction; Pellet reasoner; review dashboard showing ABox assertions and SPARQL queries.
- Assumptions/dependencies: Availability of jurisdiction-specific hearsay rules; high-quality prompts and definitions; human-in-the-loop validation for edge cases.
- Litigation admissibility precheck
- Sector: Legal, RegTech
- What it does: Screen evidence against admissibility rules (e.g., hearsay exceptions, authentication, purpose) with auditable traces.
- Tools/workflow: Modular OWL ontologies encoding evidence rules; document processing pipeline; SPARQL-based compliance reports.
- Assumptions/dependencies: Expert-authored TBox and SWRL for local court rules; scope limited to rule-expressible criteria.
- Clinical trial patient prescreening
- Sector: Healthcare
- What it does: Match free-text EHR notes or intake forms to trial inclusion/exclusion criteria; produce explainable eligibility determinations.
- Tools/workflow: Trial protocol ontology; LLM extraction from clinical notes; SWRL entailment rules; ABox audit log for regulatory review.
- Assumptions/dependencies: Access to EHRs and proper de-identification; medical terminology normalization; expert-crafted criteria rules.
- Coverage and claims rules checking
- Sector: Insurance
- What it does: Apply coverage definitions and exclusions to claims narratives and policies; generate explainable accept/deny flags.
- Tools/workflow: OWL/SWRL encoding of policy rules; LLM-driven extraction of incident facts; compliance dashboard.
- Assumptions/dependencies: Up-to-date policy ontologies; careful handling of ambiguous policy language; human oversight for high-stakes outcomes.
- Scientific method–task knowledge graph construction
- Sector: Academia, Software (Scholarly tech)
- What it does: Populate a KG of which computational methods are applied to which tasks from abstracts/papers; filter out non-applicative mentions.
- Tools/workflow: SciERC-like ontology (Method, Task, FunctionalRelation); batch PDF/abstract ingestion; SPARQL exploration for SLRs and meta-analyses.
- Assumptions/dependencies: Domain-specific definitions of “application”; access to corpora; handling of implicit/ellipsis-heavy prose.
- Systematic review triage and evidence mapping
- Sector: Healthcare, Academia
- What it does: Triage papers by rule-defined inclusion criteria (population/intervention/outcome, etc.) using explainable, queryable ABox traces.
- Tools/workflow: PICO ontology; SWRL inclusion rules; LLM extraction; curator UI to audit justifications and assertions.
- Assumptions/dependencies: Clear, rule-expressible screening criteria; curator feedback loop to refine entity/assertion specs.
- Regulatory compliance scanning for policies and reports
- Sector: Finance, Energy, Enterprise Compliance
- What it does: Check narratives (e.g., ESG reports, financial disclosures) against rule-based obligations (e.g., required statements, prohibited claims) with audit trails.
- Tools/workflow: Sector-specific compliance ontologies; LLM extraction from documents; SWRL rules; SPARQL compliance dashboards.
- Assumptions/dependencies: Codification of obligations into SWRL; scope limited to rule-expressible checks; change-management for evolving regulations.
- Benefits and public services eligibility triage
- Sector: Government/Policy
- What it does: Prescreen citizen applications (free text) against program eligibility rules; surface missing evidence and contradictions.
- Tools/workflow: Eligibility ontology; LLM extraction from applications; reasoner-based outcomes; human caseworker review of ABox trails.
- Assumptions/dependencies: Transparent, rule-defined eligibility; fairness and bias monitoring; data privacy controls.
- Contract clause classification and policy conformance
- Sector: Legal, Procurement, Enterprise
- What it does: Identify and verify presence/absence of mandatory clauses and red flags in contracts and policies via SWRL-based checks over extracted assertions.
- Tools/workflow: Clause ontology; complementary predicate design for presence/absence; SPARQL summary of conformance gaps.
- Assumptions/dependencies: Consistent clause taxonomies; careful handling of negations and exceptions.
- Explainable safety checklists for SOPs and audits
- Sector: Manufacturing, Aviation, Pharma QA
- What it does: Apply rule-based SOP/QA checklists to free-text logs and incident reports; produce explainable pass/fail with evidence.
- Tools/workflow: SOP ontology; LLM extraction from logs; reasoner inference; audit-ready ABox.
- Assumptions/dependencies: SOPs convertible to rule conditions; variability in log styles may require tuning.
- Protégé + LLM ontology population plugin
- Sector: Software/Tools, Academia
- What it does: A developer tool that reads ontology annotations (entity and assertion specs), prompts an LLM, and writes ABox assertions automatically.
- Tools/workflow: Protégé/OWL API + LLM connectors; Pellet/HermiT; export to SPARQL endpoints.
- Assumptions/dependencies: Stable LLM APIs; permissioning and provenance logging.
- SPARQL audit dashboards for LLM-driven decisions
- Sector: Cross-sector
- What it does: Out-of-the-box dashboards to query extracted entities and rule-based outcomes, enabling transparent review and error localization.
- Tools/workflow: Triplestore (Fuseki/Blazegraph); prebuilt SPARQL queries; CSV/JSON exports for auditors.
- Assumptions/dependencies: Triplestore deployment; governance for storing justifications.
Long-Term Applications
The framework suggests broader, future-facing solutions that need further research, scaling, or standardization (e.g., richer logic, domain libraries, systemic integration).
- End-to-end regulatory-grade decision-support platforms
- Sectors: Healthcare, Finance, Insurance, Government
- Vision: Certified systems for auditable decisions over natural language inputs across complex rulebooks, exceptions, and precedents.
- Dependencies: Formalization of large rule corpora into modular ontologies; rigorous validation, monitoring, and certification pathways; scalable performance on long documents.
- Domain rule libraries and standards for OWL/SWRL
- Sectors: Legal, Clinical, Finance, Safety
- Vision: Community-curated, versioned rule libraries (e.g., evidence law, eligibility, capital requirements) for reuse across organizations.
- Dependencies: Governance, licensing, and version control; alignment across jurisdictions; maintenance processes.
- Human-in-the-loop neuro-symbolic assistants (“Rules copilots”)
- Sectors: Enterprise, Legal, Clinical
- Vision: IDE-like assistants that propose extractions and rule applications, highlight doubts, and learn from corrections to refine specs and prompts.
- Dependencies: UI/UX for ABox-level feedback; active learning loops; provenance and rollback.
- Automated rule induction and maintenance from text
- Sectors: Cross-sector
- Vision: LLMs draft candidate SWRL rules and ontology updates from changes in statutes/guidelines, with expert review and formal verification.
- Dependencies: Robust pattern mining; safeguards against hallucinated rules; traceability from text to logic.
- Hybrid reasoning beyond SWRL: defaults, exceptions, and CWA bridging
- Sectors: Legal, Medicine
- Vision: Integrations combining OWL/SWRL with non-monotonic/dialectical frameworks (e.g., Defeasible Logic, ASP) and SHACL/closed-world checks for richer exception handling.
- Dependencies: Research on soundness/termination; toolchain interoperability; performance/scale testing.
- Multilingual and cross-jurisdictional rule application
- Sectors: Government, Legal, Global Pharma
- Vision: Ontology population across languages, plus alignment/mapping of rules across jurisdictions with consistent, auditable outcomes.
- Dependencies: Reliable multilingual LLMs; ontology alignment pipelines; cultural/legal variance modeling.
- Real-time document copilots with auditable reasoning
- Sectors: Productivity Software, Enterprise
- Vision: Editors that explain rule conformance as users write (contracts, policies, protocols), producing ABox traces as living documentation.
- Dependencies: Low-latency LLMs; incremental reasoning; strong privacy and on-device options.
- Integration with enterprise KGs and RAG for context-enriched reasoning
- Sectors: Enterprise IT
- Vision: Use retrieval over corporate KGs/documents to enrich extraction, then apply rules for decisions with complete context.
- Dependencies: Robust RAG pipelines; KG quality; consistent entity resolution into ontology individuals.
- Benchmark ecosystems and certification for rule-governed LLM reasoning
- Sectors: Academia, Standards bodies
- Vision: Shared benchmarks, audit criteria, and conformance tests for neural-symbolic pipelines; best-practice guides for ontology design and prompting.
- Dependencies: Public datasets spanning domains; consensus on metrics for auditability and consistency.
- Advanced complementary predicate patterns and uncertainty handling
- Sectors: Cross-sector
- Vision: Systematic designs to mitigate open-world effects, capture uncertainty, and trigger mandatory human review when evidence is incomplete or contradictory.
- Dependencies: Calibration methods; uncertainty-aware SWRL extensions or hybrid layers; governance policies.
- Agentic multi-step workflows with structured decomposition
- Sectors: Software/Automation, RPA
- Vision: Multi-agent systems that decompose tasks, populate ontologies, query KGs, and apply rules iteratively to orchestrate complex, auditable processes.
- Dependencies: Coordination protocols; provenance standards; failure-handling strategies.
- Privacy-preserving and on-prem neuro-symbolic pipelines
- Sectors: Healthcare, Finance, GovCloud
- Vision: Deploy the entire stack (LLM + reasoner + triplestore) on-prem or in confidential compute, preserving audit trails without data egress.
- Dependencies: High-quality on-prem LLMs; MLOps for semantic pipelines; compliance audits (HIPAA/GDPR/PCI).
- Cross-domain synthesis and multi-label classification with class hierarchies
- Sectors: Academia, Enterprise Knowledge Management
- Vision: Rich inference over hierarchical classes (e.g., evidence subtypes, overlapping compliance categories) using the semantic web’s expressive hierarchies.
- Dependencies: Ontology curation at scale; rule interaction testing; UX for multi-label explanations.
Notes on feasibility across all applications:
- Task suitability: Success depends on rule-expressible decision boundaries and formalisable predicates; tasks dominated by statistical patterns (e.g., diagnoses without deterministic rules) are not good fits.
- Expert-authored ontologies: TBox/SWRL quality governs outcomes; initial authoring and maintenance are non-trivial.
- LLM reliability: Domain-tuned prompting and guardrails are needed; complementary predicate patterns can mitigate bias/OWA gaps.
- Toolchain limits: SWRL expressivity and reasoner performance may constrain extremely complex or massive workloads; careful engineering and potential hybrid logic are needed.
- Governance: High-stakes uses require human oversight, versioning, provenance, and audit compliance.
Collections
Sign up for free to add this paper to one or more collections.