Rethinking Reasoning in LLMs: Neuro-Symbolic Local RetoMaton Beyond ICL and CoT
Abstract: Prompt-based reasoning strategies such as Chain-of-Thought (CoT) and In-Context Learning (ICL) have become widely used for eliciting reasoning capabilities in LLMs. However, these methods rely on fragile, implicit mechanisms often yielding inconsistent outputs across seeds, formats, or minor prompt variations making them fundamentally unreliable for tasks requiring stable, interpretable reasoning. In contrast, automata-based neuro-symbolic frameworks like RetoMaton offer a more structured and trustworthy alternative by grounding retrieval in symbolic memory with deterministic transitions. In this work, we extend RetoMaton by replacing its global datastore with a local, task-adaptive Weighted Finite Automaton (WFA), constructed directly from external domain corpora. This local automaton structure promotes robust, context-aware retrieval while preserving symbolic traceability and low inference overhead. Unlike prompting, which entangles context and memory in opaque ways, our approach leverages the explicit structure of WFAs to provide verifiable and modular retrieval behavior, making it better suited for domain transfer and interoperability. We evaluate this local RetoMaton variant on two pretrained LLMs LLaMA-3.2-1B and Gemma-3-1B-PT across three reasoning tasks: TriviaQA (reading comprehension), GSM8K (multi-step math), and MMLU (domain knowledge). Compared to the base model and prompting-based methods, augmenting these setups with local RetoMaton consistently improves performance while enabling transparent and reproducible retrieval dynamics. Our results highlight a promising shift toward trustworthy, symbolic reasoning in modern LLMs via lightweight, automaton-guided memory.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at a better way to help LLMs—the kinds of AI that write and answer questions—think more clearly and consistently. Instead of relying only on “prompt tricks” like Chain-of-Thought (CoT) and In-Context Learning (ICL), the authors add a small, smart memory system called a Local RetoMaton. This memory is built from the most relevant information for the task and guides the model step-by-step, like following a map, so its reasoning is more stable and easier to understand.
What questions does the paper ask?
The paper focuses on three simple questions:
- Can we make LLMs reason more reliably than just using prompts like CoT and ICL?
- Can we give LLMs a small, organized memory that helps them pick the right information at the right time?
- Will this memory make models more accurate on tasks like reading comprehension, math problems, and general knowledge?
How does it work? (Simple explanation of the method)
Think of the LLM as a student taking a test:
- With CoT and ICL, you’re giving the student hints in the question itself. That can work, but it’s fragile—small changes in the hints can confuse the student.
- The Local RetoMaton is like giving the student a tiny, well-organized notebook made only from helpful notes for the current subject. The student looks up examples and follows a clear path of steps (like a recipe) to find the correct answer.
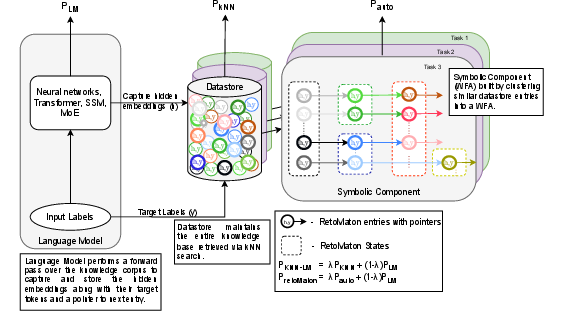
Here’s what the Local RetoMaton is made of:
- A “symbolic memory” built from text that’s directly related to the task. For example, for trivia questions, it uses the evidence documents linked to those questions; for math problems, it uses math-related text.
- An automaton (a kind of simple machine or roadmap). Picture intersections (states) connected by roads (transitions). Each road has a “weight” (how useful it is), and the model follows the best path through this map to find the next word or step.
- A nearest-neighbor lookup (like finding the most similar notes in your notebook). The model checks which past examples are closest to what it’s currently trying to do and uses them to guide its next move.
Key idea: The model’s own internal signals (its “embeddings,” like coordinates on a map) are clustered into states. These states and their connections form a small, task-specific roadmap. As the model generates text, it follows this roadmap, making its reasoning traceable and reproducible.
What did they test?
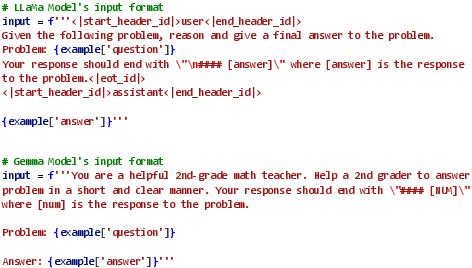
They tried this on two compact LLMs (both around 1 billion parameters):
- LLaMA-3.2-1B
- Gemma-3-1B-PT
And on three types of tasks:
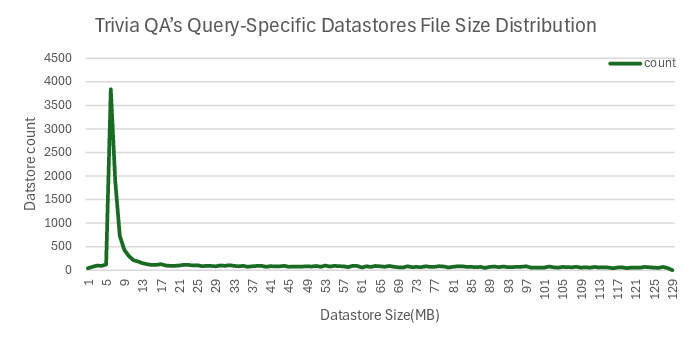
- TriviaQA: Reading comprehension (answering trivia questions based on evidence)
- GSM8K: Multi-step grade-school math problems
- MMLU: General knowledge questions across many subjects
They compared:
- The base model with normal prompting (ICL/CoT)
- A Global RetoMaton (memory built from a broad source like Wikipedia)
- A Domain-Aligned RetoMaton (memory tuned to the topic, like math text for math tasks)
- The Local RetoMaton (memory built from the exact task data or evidence)
Main findings and why they matter
- The Local RetoMaton consistently improved accuracy over just prompting and over the global/domain versions.
- Average gains: about 4.48% with LLaMA and 2.78% with Gemma across the three tasks.
- It made the model’s reasoning more transparent. You can trace which “paths” in the memory the model followed to produce each step, making it easier to understand and debug.
- It was more robust. Small changes to prompts didn’t break the reasoning as easily because the model was guided by a stable, structured memory.
- It was efficient. Since the local memory is smaller and focused, it’s faster to use and doesn’t require fine-tuning the model’s weights.
- It reduced “noise” in retrieval. Using nearby, relevant notes (local memory) led to better-calibrated predictions than searching everything (global memory).
In short: The Local RetoMaton helps LLMs be more accurate and more trustworthy, especially on tasks that need careful, step-by-step reasoning.
What’s the impact?
- More reliable AI: Models can reason in a way that’s easier to verify, which is important for math, science, and fact-based tasks.
- Better for smaller models: This approach can boost compact models without expensive retraining, making AI more accessible.
- Easy to adapt: You can swap in new, task-specific memory without changing the model itself, which helps with domain transfer (moving between subjects).
- More transparency: Being able to trace the model’s “thinking path” means better debugging, safety, and trust.
Looking ahead, the authors suggest testing this with larger models, more tasks (like fact checking and summarization), and different architectures. Their main message: combining neural networks with simple, rule-like structures (neuro-symbolic AI) can make AI reasoning clearer, stronger, and more dependable.
Collections
Sign up for free to add this paper to one or more collections.