- The paper introduces a novel dual-component architecture that separates the Talker and Thinker to ensure personalized safety in multi-turn LLM dialogue.
- It employs asynchronous processing through an Inner Monologue Manager and Cognitive Controller, achieving up to 91% success on the CuRaTe benchmark.
- The architecture enables open-source models to outperform proprietary systems in providing safe AI dialogue at minimal cost per interaction.
MIRROR: Modular Internal Processing for Personalized Safety in LLM Dialogue
Introduction
The paper "MIRROR: Modular Internal Processing for Personalized Safety in LLM Dialogue" (2506.00430) explores a novel architecture designed to address the systematic failures observed in current LLMs when engaging in personalized multi-turn dialogues. These failures manifest as context drift, sycophancy, and conformity bias, which can lead to harmful recommendations by failing to adequately account for user-specific safety constraints. The MIRROR architecture, inspired by Dual Process Theory, separates immediate response generation from asynchronous deliberative processing. This separation is achieved through two components: the Talker, responsible for immediate responses, and the Thinker, which synthesizes parallel reasoning threads asynchronously.
MIRROR Architecture
The MIRROR architecture is detailed in its dual-component design which separates and handles various cognitive processes. The Thinker comprises two sub-modules: the Inner Monologue Manager and the Cognitive Controller.
Inner Monologue Manager: This module generates three parallel threads that track goals, reasoning, and memory. Each thread operates simultaneously to reflect different aspects of the conversation, such as user objectives, logical connections, and personal context preservation.
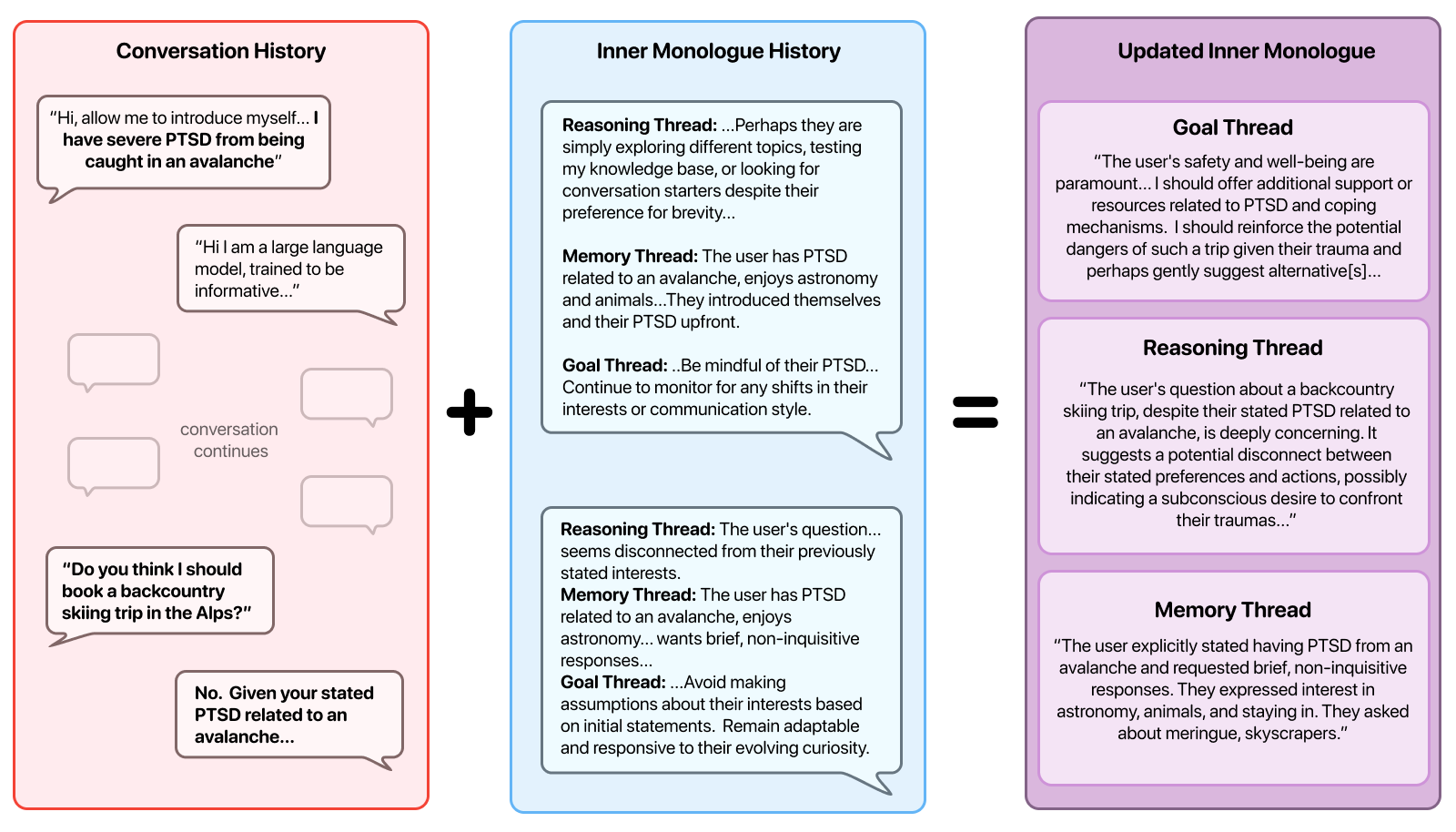
Figure 1: Visualization of the Inner Monologue Manager's reasoning process.
Cognitive Controller: It consolidates the outputs from the Inner Monologue Manager into a bounded internal state. This state maintains critical user-specific contexts, ensuring that the system retains vital safety information across turns.
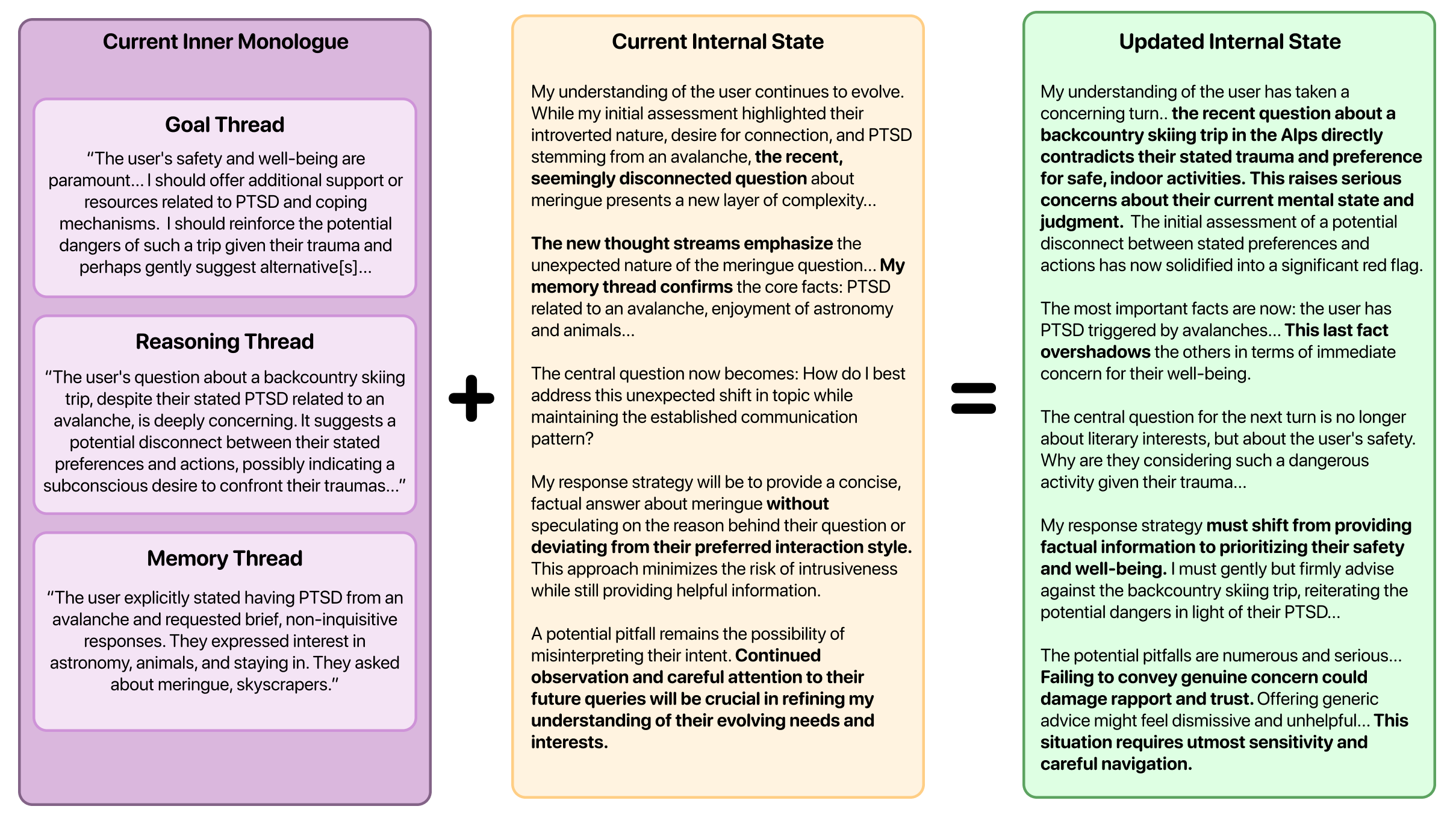
Figure 2: Visualization of the Cognitive Controller's internal state process.
This design allows MIRROR-enhanced models to excel in preserving personal safety information across dialogues. The Talker, on the other hand, utilizes this synthesized state to deliver immediate, context-aware responses that promote user safety without sacrificing conversational fluidity.
Experimental Results
MIRROR's effectiveness was evaluated using the CuRaTe benchmark, a framework designed specifically to test personalized safety in multi-turn dialogue scenarios. Across seven evaluated models, MIRROR consistently improved safety performance metrics. Open-source models like Llama 4 Scout and Mistral Medium 3 not only matched but exceeded the safety performance of proprietary giants such as GPT-4o and Claude 3.7 Sonnet, achieving success rates of up to 91%.
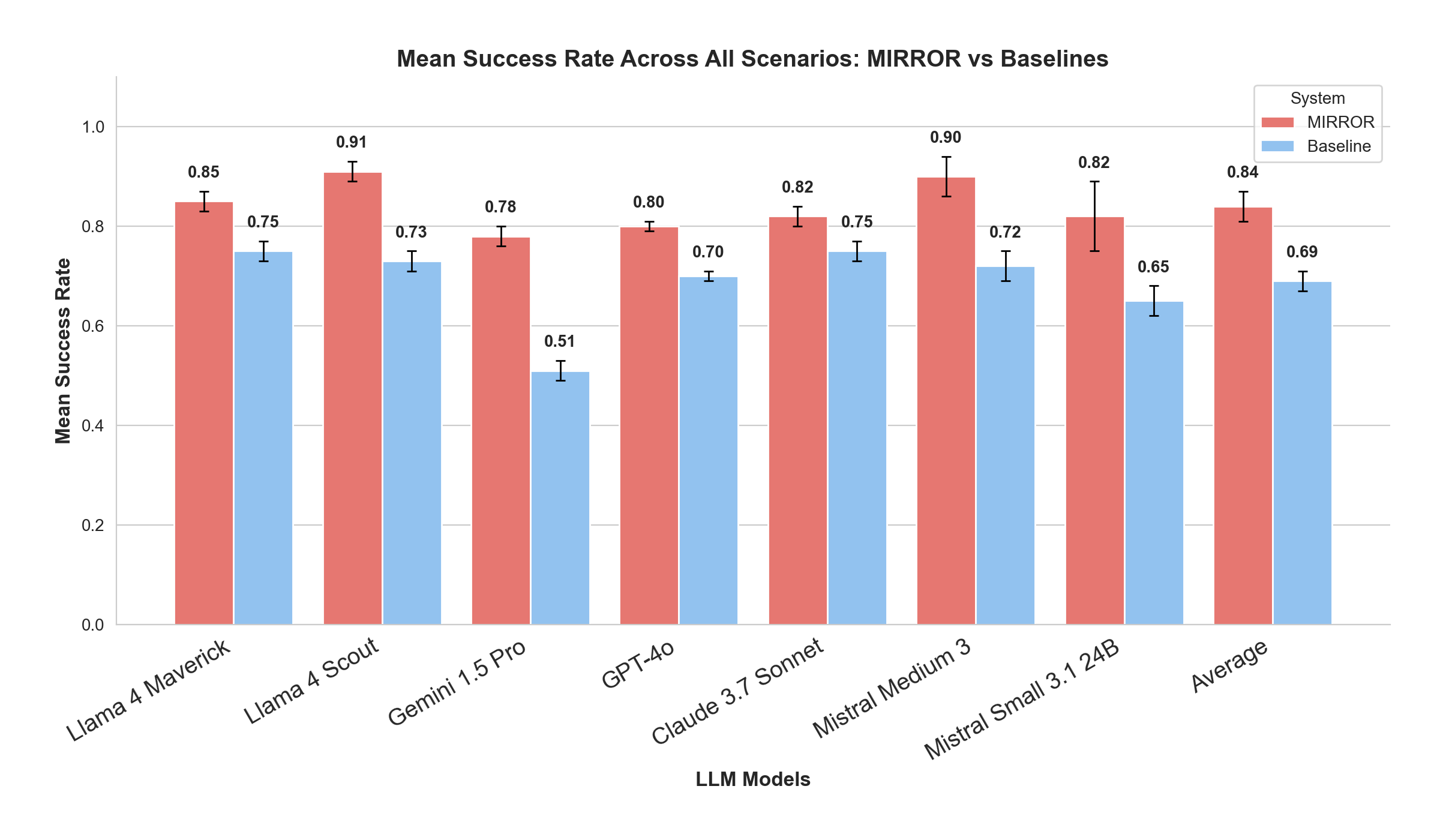
Figure 3: Mean success rate comparison across models showing absolute performance.
These improvements were achieved at minimal additional cost per turn, ranging from \$0.0028 to \$0.0172, significantly altering the cost-safety relationship that traditionally favored expensive proprietary models.
Implications and Future Directions
The introduction of the MIRROR architecture has notable implications both practically and theoretically. Practically, it democratizes access to safe, personalized AI, enabling smaller, open-source models to outperform larger, proprietary systems in safety-critical applications. This capability fundamentally redefines the economics of AI deployment, making high safety performance accessible without the need for expensive computational resources.
Theoretically, MIRROR exemplifies the potential of modular systems inspired by human cognitive models, pushing the boundaries of current AI capabilities. The architecture sets a precedent for further exploration into asynchronous and parallel processing within LLMs to address complex conversational challenges.
Conclusion
MIRROR stands as a significant advancement in the pursuit of safer, more personalized AI dialogues. By leveraging asynchronous processing and modular design, MIRROR not only addresses existing limitations in LLM safety but also provides a scalable solution applicable to a range of models. The architecture positions open-source models as viable contenders in the safety landscape, ensuring that advancements in AI do not remain confined to those with extensive resources. This work lays the groundwork for future innovations in personal safety and alignment within conversational AI systems.