- The paper introduces a memory-augmented video generation framework that integrates short-term, spatial, and episodic memory to enhance scene consistency.
- It employs a diffusion transformer architecture with a custom dataset, achieving superior motion plausibility and photo-realistic quality via metrics like PSNR, SSIM, and LPIPS.
- Ablation studies confirm that combining spatial and episodic memory significantly improves view recall consistency and dynamic scene generation.
Overview of "Video World Models with Long-term Spatial Memory"
This paper introduces an innovative approach for improving long-term consistency in video world models through the incorporation of memory mechanisms inspired by human cognitive memory processes. The study addresses the challenge of maintaining scene consistency over extended video sequences, which has been a significant limitation in existing video generation models due to the constraints imposed by limited temporal context windows.

Figure 1: An illustration of memory-augmented video world models with short-term working memory and long-term spatial and episodic memory.
Memory Mechanisms and System Architecture
Memory-Augmented Framework
The core proposition of the paper revolves around the implementation of three distinct forms of memory within the video generation process:
- Short-term Working Memory: Utilizes recent frames to maintain motion continuity and ensures smooth transitions over short sequences.
- Long-term Spatial Memory: Constructed using geometry-grounded representations such as point clouds that capture static 3D structures of the environment, filtered through TSDF-Fusion to discard dynamic components.
- Episodic Memory: Comprises a sparse set of historical reference frames to reinforce visual details and identities for enduring consistency.
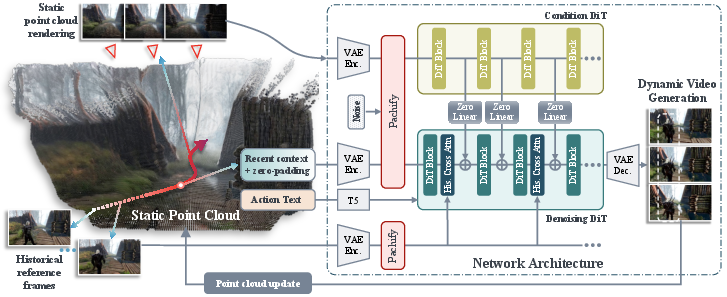
Figure 2: System overview depicting the diffusion transformer (DiT) conditioned on three memory mechanisms for autoregressive video frame generation.
Implementation Details
The system builds on a latent video generation model using a diffusion transformer architecture, DiT, that is enhanced with the proposed memory mechanisms. The autoregressive generation process allows for progressive updates to the spatial memory with each new frame generation, thereby incrementally refining the scene understanding over long sequences.
Dataset Construction and Methodology
Dataset for Training and Evaluation
A custom dataset derived from MiraData is curated to effectively train and evaluate the memory-augmented video models. This dataset involves structured sequences with explicit 3D spatial memories, leveraging tools like Mega-SaM for robust structure and motion recovery.
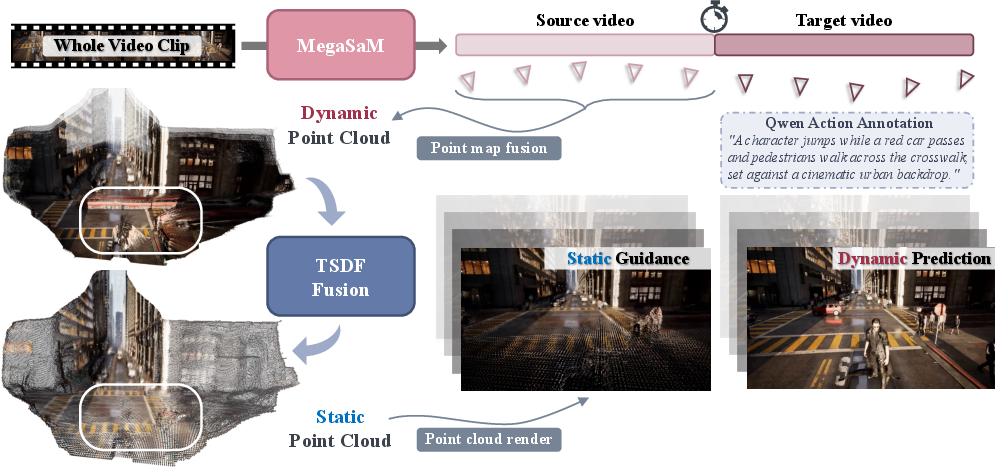
Figure 3: The construction pipeline for creating the training dataset, capturing cameras' intrinsics, extrinsics, and temporal depth maps.
Experimental Setup
The evaluations are designed to rigorously test view recall consistency and camera trajectory accuracy, comparing the proposed system against contemporary baselines. The metrics employed include PSNR, SSIM, LPIPS for image quality, alongside user studies for qualitative assessment.
Quantitative and Qualitative Results
Quantitative results highlight the superiority of the proposed method, particularly in terms of view recall consistency and motion plausibility across dynamic scenes. The system demonstrates enhanced photo-realistic quality and temporal coherence compared to industry benchmarks.

Figure 4: Qualitative comparison showcasing the capability of the proposed model to manage camera pose changes and maintain scene integrity.
Ablation Studies
A comprehensive ablation study elucidates the individual contributions of each memory mechanism, affirming that integrating both spatial and episodic memory significantly bolsters long-term video generation capabilities.
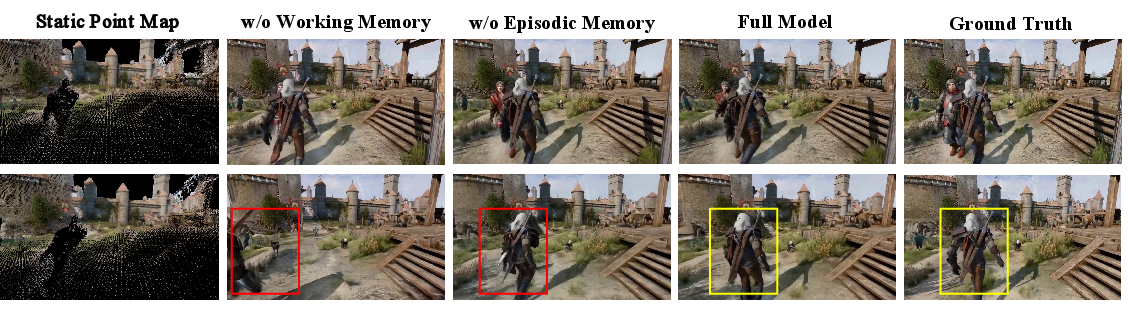
Figure 5: Ablation study results, illustrating the impact of each memory component on generating coherent dynamic motions.
Challenges and Limitations
Limitations
The exploration of limitations reveals challenges such as the difficulty in managing drastic variances in camera trajectories or extreme close-ups, impacting spatial memory reliability.

Figure 6: A visualization of an autoregressive point cloud fusion strategy, critical for maintaining map consistency over time.
Future Prospects
The paper recognizes potential avenues for enhancing memory mechanisms, possibly integrating other context-augmenting strategies like frame packing or employing hybrid techniques for deeper temporal reasoning.
Conclusion
This research represents a substantial step toward achieving long-term scene consistency in video world models. By emulating human-like memory processes, it offers innovative solutions to enhance generative video systems' efficacy in dynamic real-world applications such as interactive simulators or video content creation platforms.