- The paper presents a novel framework that enables infinite-length video generation from a single image using discretized camera motion control and autoregressive techniques.
- It introduces a masked video diffusion transformer that enhances structural consistency, reduces memory overhead, and mitigates artifacts through advanced sampling strategies like AAM and TTS-SDE.
- The model outperforms baselines in instruction-following and visual quality while leveraging adversarial distillation and caching to accelerate inference.
Yume: An Interactive World Generation Model
Introduction and Motivation
Yume presents a comprehensive framework for interactive, high-fidelity world generation, enabling users to explore dynamic environments synthesized from a single input image via continuous keyboard control. The model addresses the limitations of prior video diffusion approaches in terms of controllability, visual realism, and scalability to complex real-world scenes. Yume’s architecture is designed to support infinite-length, autoregressive video generation, with a focus on robust camera motion control, artifact mitigation, and efficient inference.

Figure 1: Yume enables streaming, interactive world generation from an input image, supporting continuous keyboard-driven exploration.
Core Components and Methodology
Yume’s system is structured around four principal innovations: quantized camera motion control, a masked video diffusion transformer (MVDT) architecture, advanced sampling strategies, and model acceleration via adversarial distillation and caching.
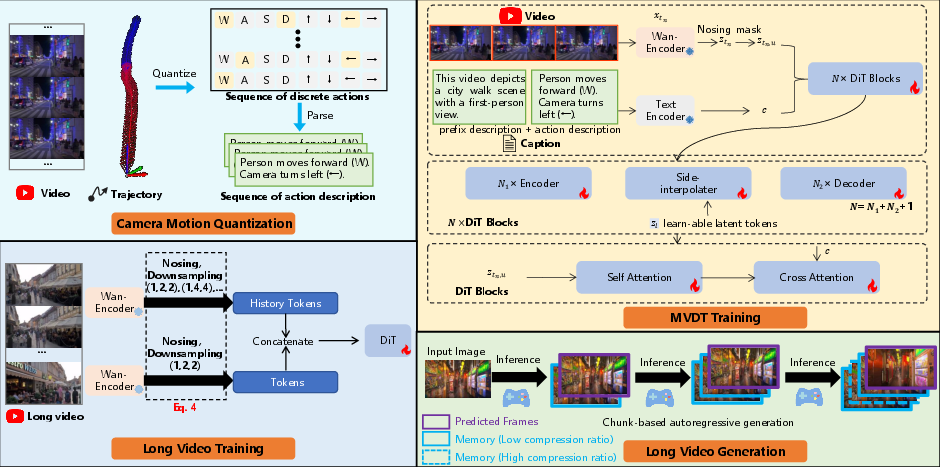
Figure 2: The four core components of Yume: camera motion quantization, model architecture, long video training, and generation.
Quantized Camera Motion (QCM)
Traditional video diffusion models rely on dense, per-frame camera pose matrices, which are difficult to annotate and often result in unstable or unintuitive control. Yume introduces a quantization scheme that discretizes camera trajectories into a finite set of canonical actions (e.g., move forward, turn left, tilt up), each mapped to a relative transformation. This quantization is performed by matching the actual relative transformation between frames to the closest canonical action, as formalized in Algorithm 1 of the paper. The resulting action sequence is then injected as a textual condition, enabling precise, low-latency keyboard-based control without additional learnable modules.

Figure 3: Example vocabulary for translational motion, mapping discrete actions to natural language descriptions.

Figure 4: Example vocabulary for rotational motion, supporting intuitive camera orientation control.
Yume’s backbone is a DiT-based video diffusion model augmented with masked representation learning. The MVDT architecture applies stochastic masking to input video tokens, focusing computation on visible regions and interpolating masked content via a side-interpolator. This design improves structural consistency across frames and reduces memory/computation overhead. The model is trained end-to-end, with masking applied only during training to encourage robust feature learning.
To support infinite-length, temporally coherent video, Yume employs a chunk-based autoregressive generation strategy. Historical frames are compressed using a hierarchical Patchify module (with increasing spatiotemporal compression for older frames), and concatenated with newly generated segments. This approach, inspired by FramePack, preserves high-resolution context for recent frames while maintaining long-term consistency.
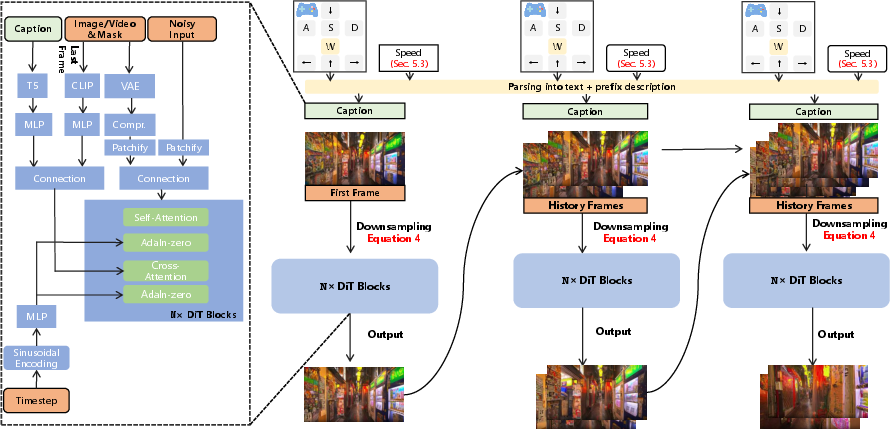
Figure 5: Long-form video generation method, leveraging hierarchical compression and autoregressive chunking.
Advanced Sampler: AAM and TTS-SDE
Yume introduces two key sampling innovations:
Model Acceleration: Adversarial Distillation and Caching
Yume addresses the high computational cost of diffusion-based video generation by jointly optimizing adversarial distillation and cache acceleration:
- Adversarial Distillation: The denoising process is distilled into fewer steps using a GAN-based loss, preserving visual quality while reducing inference time. The discriminator is adapted from OSV for memory efficiency.
- Cache Acceleration: Intermediate residuals from selected DiT blocks are cached and reused across denoising steps, with block importance determined via MSE-based ablation. Central blocks are identified as least critical and targeted for caching, yielding significant speedups with minimal quality loss.
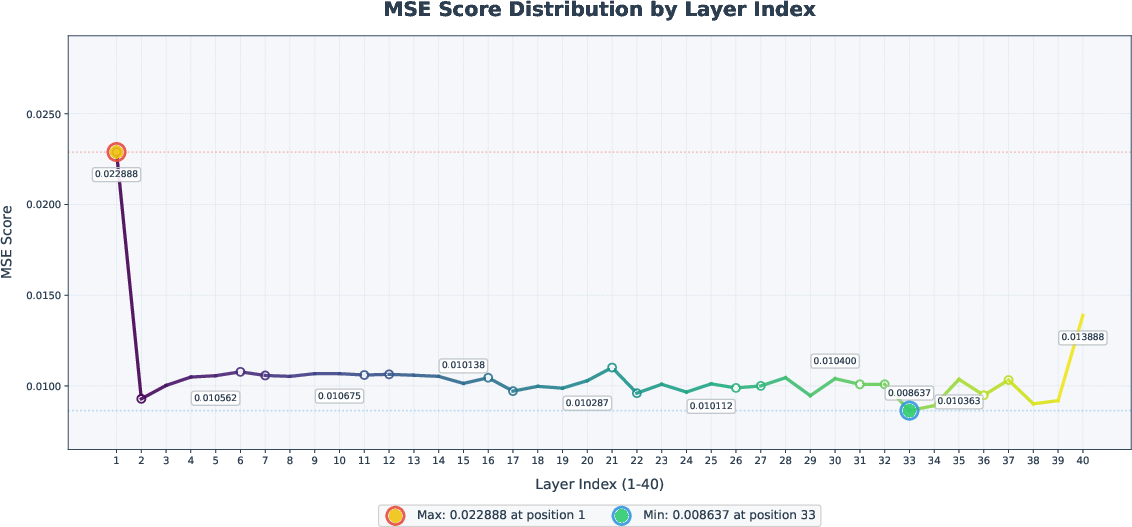
Figure 7: Significance of individual DiT blocks, guiding the selection of cacheable layers for acceleration.
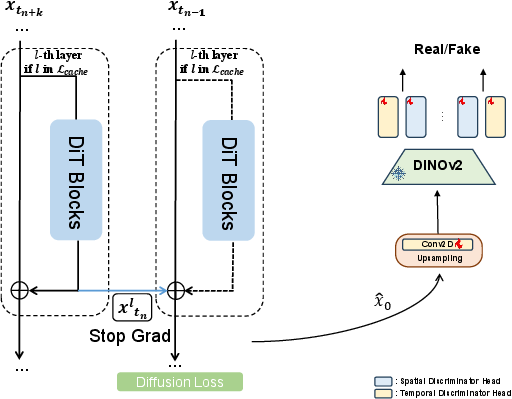
Figure 8: Acceleration method design, illustrating the integration of adversarial distillation and caching.
Experimental Results
Visual Quality and Controllability
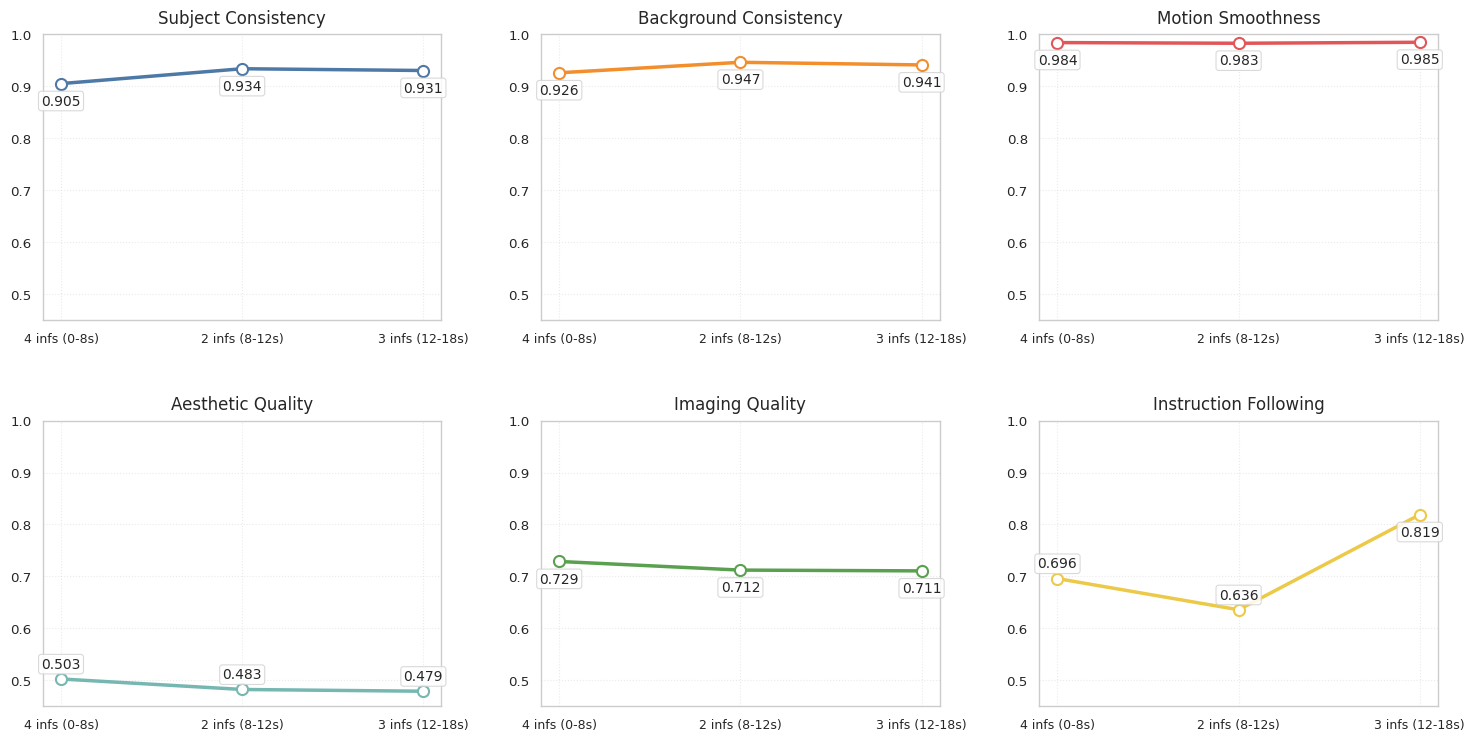
Yume is evaluated on the Yume-Bench, a custom benchmark for interactive video generation with complex camera motions. Compared to state-of-the-art baselines (Wan-2.1, MatrixGame), Yume achieves a substantial improvement in instruction-following (0.657 vs. 0.271 for MatrixGame), while maintaining or exceeding performance in subject/background consistency, motion smoothness, and aesthetic quality.

Figure 9: Yume demonstrates superior visual quality and precise adherence to keyboard control in both real-world and synthetic scenarios.
Long-Video Stability
Yume maintains high subject and background consistency over 18-second sequences, with only minor degradation observed during abrupt motion transitions. Instruction-following recovers rapidly after transitions, indicating robust temporal modeling.

Figure 10: AAM improves structural details in urban and architectural scenes, reducing artifacts and enhancing realism.
Ablation and Acceleration
- TTS-SDE yields the highest instruction-following (0.743), with a slight trade-off in background consistency and imaging quality.
- Distilled models (14 steps vs. 50) achieve a 3.7x speedup with minimal loss in visual metrics, though instruction-following is somewhat reduced.
- Cache acceleration further reduces inference time by targeting non-critical DiT blocks.
Practical Implications and Future Directions
Yume’s architecture enables a range of applications, including real-time world exploration, world editing (via integration with image editing models such as GPT-4o), and adaptation to both real and synthetic domains. The quantized camera motion paradigm offers a scalable solution for interactive control, while the MVDT and advanced sampling strategies set a new standard for artifact-free, temporally coherent video generation.
The release of code, models, and data facilitates reproducibility and further research. However, challenges remain in scaling to higher resolutions, improving runtime efficiency, and extending control to object-level interactions and neural signal inputs.
Conclusion
Yume establishes a robust foundation for interactive, infinite-length world generation from static images, combining discrete camera motion control, masked video diffusion, advanced artifact mitigation, and efficient inference. The model demonstrates strong numerical results in both visual quality and controllability, outperforming prior baselines in complex, real-world scenarios. Future work will focus on enhancing visual fidelity, expanding interaction modalities, and further optimizing inference for real-time deployment.