- The paper introduces a compositional latent space and hierarchical attention mechanism that enable independent manipulation and semantic coherence in 3D mesh part generation.
- The model leverages a newly curated, part-annotated dataset to achieve high-fidelity reconstruction of both visible and inferred (invisible) structures.
- By eliminating explicit segmentation, PartCrafter sets a new benchmark for efficient and accurate structured 3D scene generation.
The paper "PartCrafter: Structured 3D Mesh Generation via Compositional Latent Diffusion Transformers" (2506.05573) introduces a novel approach for synthesizing structured 3D meshes from single RGB images. PartCrafter distinguishes itself by generating semantically meaningful and geometrically distinct 3D meshes without the need for pre-segmented inputs, deviating from the prevalent two-stage pipelines.
Methodology
PartCrafter leverages a pretrained 3D mesh diffusion transformer (DiT) framework, which it enhances with two key innovations: a compositional latent space and a hierarchical attention mechanism. The compositional latent space associates each 3D part with disentangled latent tokens, enabling independent manipulation of parts. The hierarchical attention mechanism facilitates global coherence while preserving part-level details by allowing information flow both within and across parts.
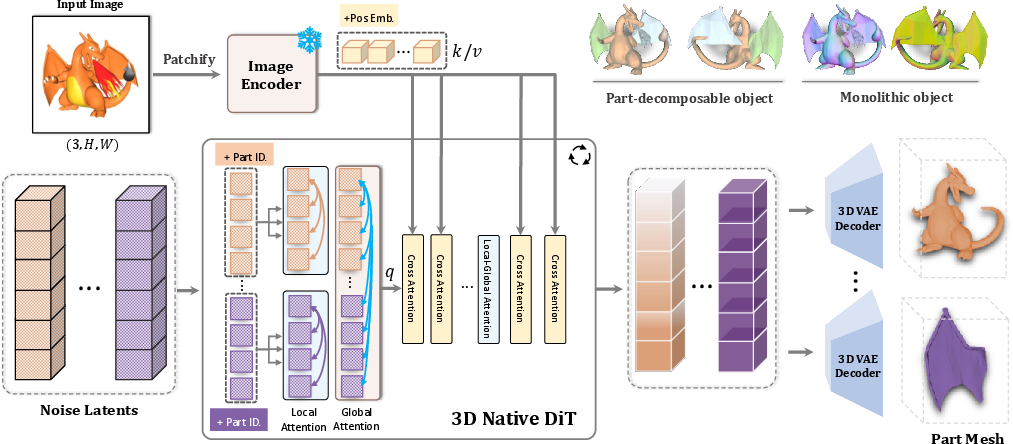
Figure 1: Architecture of PartCrafter. Our model utilizes local-global attention to capture both part-level and global features. Part ID embeddings and incorporation of the image condition into both local and global features ensure the independence and semantic coherence of the generated parts.
To train PartCrafter, the authors curated a new dataset with part-level annotations derived from 3D object repositories such as Objaverse, ShapeNet, and the Amazon Berkeley Objects dataset. This dataset supports the learning of part-aware generative priors which are essential for high-fidelity 3D synthesis.
Experimental Results
PartCrafter demonstrates superior performance in generating decomposable 3D meshes compared to existing models that rely on image segmentation followed by reconstruction. The experimental results indicate that PartCrafter outperforms these approaches in generating both individual parts and complex scenes, even for components not visible in the input images.

Figure 2: Qualitative Results on 3D Part-Level Object Generation. We present visualization results of HoloPart showcasing PartCrafter's ability to infer invisible structures.
The model's ability to accurately reconstruct 3D parts and scenes from images presents it as a universal model for scene reconstruction, achieving higher fidelity and efficiency than two-stage methods.
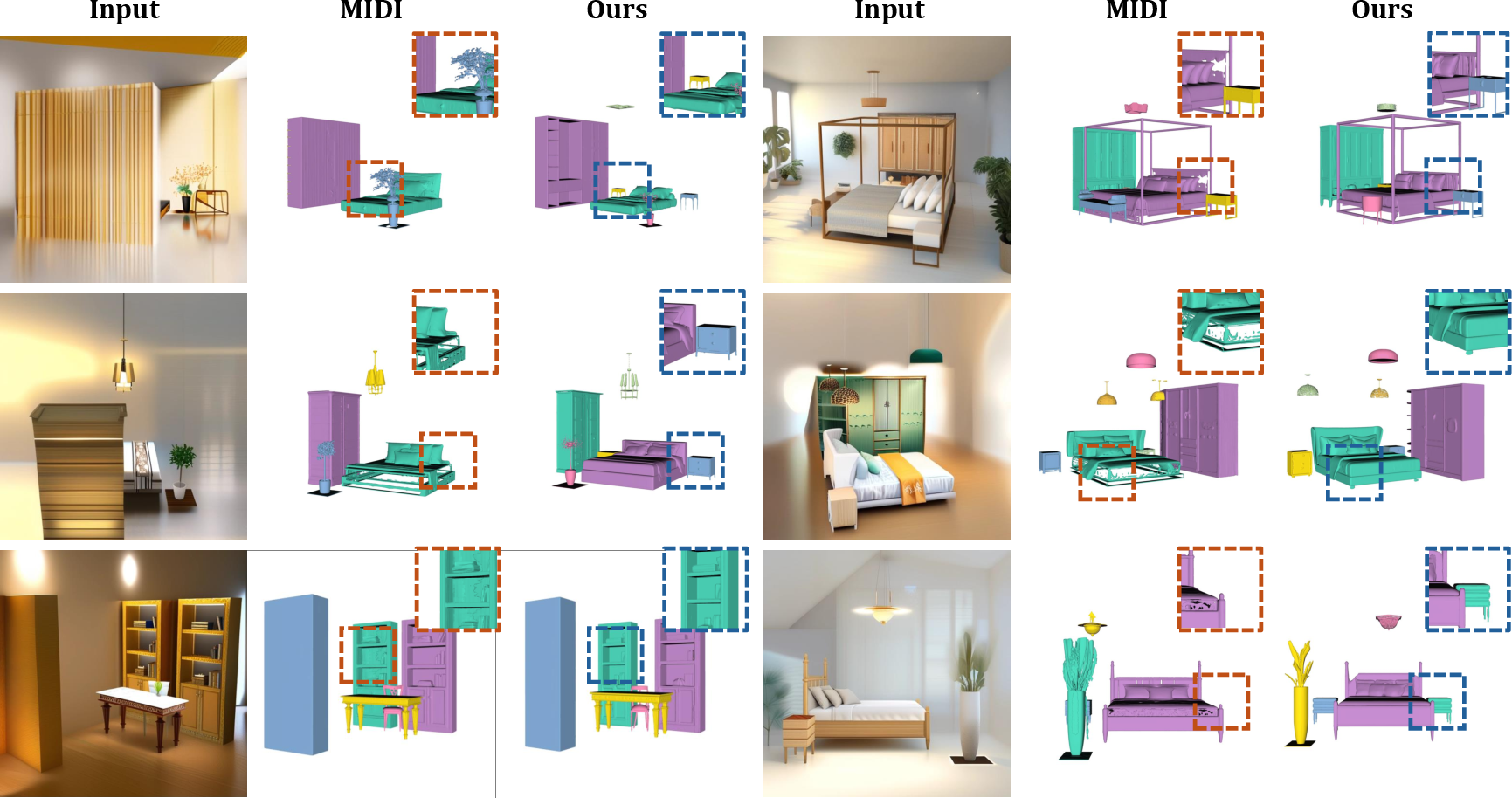
Figure 3: Qualitative Results on 3D Scene Generation. The results depict PartCrafter's proficiency in handling complex multi-object scenes without explicit segmentation.
Implications and Future Prospects
PartCrafter significantly advances the field of 3D generation by eliminating the dependency on explicit segmentation, thus simplifying the pipeline and reducing computational overhead. It opens avenues for applications in texture mapping, animation, and physical simulation, where high-quality part decomposition is critical.
Looking ahead, the methodology could benefit from scaling up the training dataset and refining architectural components to further improve the quality of generated meshes. Future works may also explore integrating texture generation directly within the PartCrafter pipeline, thereby enhancing its applicability in more diverse scenarios.
Conclusion
PartCrafter sets a new benchmark for structured 3D generation, achieving impressive results on both object and scene-level tasks. By adopting a compositional latent space and a novel attention mechanism, it paves the way for more efficient and flexible 3D mesh generation without the constraints of traditional segmentation methods. This contribution holds substantial promise for improving generative models' applicability in both research and industry-focused tasks.