- The paper introduces CoPart, a bottom-up diffusion framework that uses part-level geometric and appearance latents for robust 3D generation.
- It employs inter-part and intra-part cross-modality synchronization via transformer attention to ensure semantic coherence and precise texture-shape alignment.
- Quantitative results on the PartVerse dataset demonstrate significant improvements in CLIP and ULIP-T scores, highlighting enhanced part-editing and scene synthesis capabilities.
Contextual Part Latent Diffusion for Robust Part-Based 3D Generation
Motivation and Problem Setting
Contemporary 3D generative models, primarily driven by latent diffusion, have demonstrated notable performance improvements in object synthesis by leveraging large-scale datasets and intrinsic geometric supervision. However, most existing methods operate with a monolithic object-level latent, disregarding the decomposition that is central to both semantic understanding and practical 3D design workflows. This omission restricts generative granularity, inter-part independence, and detailed manipulation capabilities, ultimately manifesting as significant quality degradation on intricate, multi-component objects and limiting practical applicability in asset creation, part-editing, or generative articulation.
The paper "From One to More: Contextual Part Latents for 3D Generation" (2507.08772) introduces CoPart—a bottom-up diffusion framework that encodes and synchronizes part-level geometric and appearance latents to jointly generate high-fidelity 3D objects as an assemblage of coherent parts. The framework is trained on PartVerse, a newly curated, diverse 3D part dataset, supporting applications ranging from targeted part editing to articulated object and scene-level generation.
Architecture and Methodology
CoPart leverages synchronized diffusion across 3D geometric and 2D appearance latent spaces at the part level. Each part is represented by a hybrid latent consisting of (i) geometric tokens from a fine-tuned 3D part VAE, and (ii) image tokens from a high-resolution multi-view image VAE. This dual representation ensures complementary modeling of shape detail and appearance cues while decoupling geometric and semantic information for improved generation fidelity.
A mutual guidance mechanism, inspired and extended from bidirectional diffusion architectures, provides two distinct synchronizations integral to part consistency:
- Inter-Part Synchronization: Transformer self-attention blocks are extended to allow cross-part querying within a modality, ensuring that generated parts are harmonized both semantically and structurally.
- Intra-Part Cross-Modality Synchronization: Cross-attention exchanges information between geometric and image features within each part, maintaining modality coherence and improving texture-shape alignment.
Part-level conditions, including text prompts and bounding box constraints, are encoded using learned mesh latents and wireframe images, further controlling part semantics, spatial arrangement, and eliminating order ambiguity in inference. The global guidance branch regularizes overall object coherence, critical for ensuring assembled parts contribute to a unified, plausible object.
Refinement is performed via a 3D foundation model enhancer, which receives part-geometric voxels and multi-view rendered images, boosting surface detail and facilitating seamless assembly post normalization/inverse normalization.
Dataset: PartVerse
Recognizing the fundamental limitations of prior datasets (e.g., PartNet) in category diversity and textural fidelity, PartVerse is collected by automatic mesh segmentation over Objaverse sources, followed by human annotation and vision-language captioning. It contains 91k parts covering 12k objects across 175 categories, supporting model generalization and granular semantic conditioning.
Experimental Evaluation
CoPart demonstrates salient improvements over state-of-the-art (SOTA) holistic and part-level generators. Quantitative metrics include CLIP-based geometry-text and image-text alignment, as well as ULIP-T scores for multimodal consistency. For part-aware generation (e.g., “a rifle stock”), CoPart achieves:
- CLIP (N-T): 0.1607
- CLIP (I-T): 0.1768
- ULIP-T: 0.1355
These are substantially higher than prior models such as Rodin and Trellis on part-aware tasks, underscoring the advantages of explicit part representation. Notably, the preference in user studies attests to improved decomposability and quality at both whole-object and part levels.
Ablation Analyses
The contributions of global guidance and refinement modules are empirically validated. Removing global guidance compromises appearance coherence across parts (Figure 1), while the enhancement module yields tangible fidelity improvements, particularly when both geometric and image modalities are provided (Figure 2).

Figure 1: Ablation of global guidance, evidencing reduced part coherence and visual appearance fidelity when omitted.
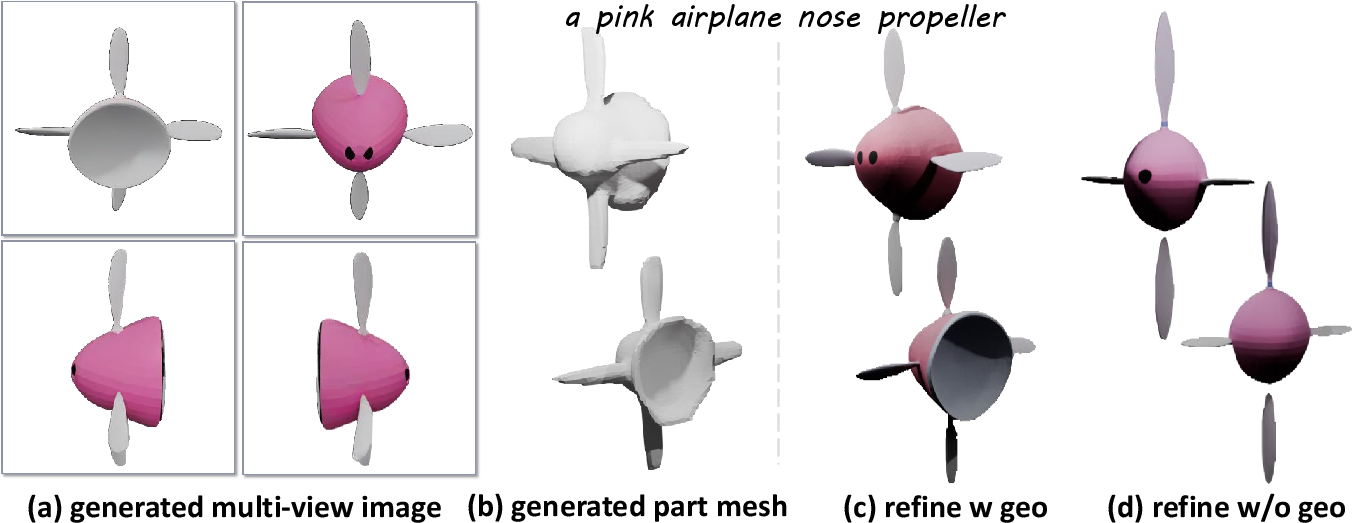
Figure 2: Ablation of refinement module, demonstrating that integrating both part images and geometries is essential for maximal enhancement.
Applications and Implications
CoPart’s part-level latent architecture enables direct, fine-grained editing, robust articulation generation, and mini-scene synthesis without additional retraining. Selective part resampling supports practical asset modification, while box-guided generation allows high control during assembly, facilitating downstream use in CAD, content creation, and interactive design environments. The method naturally extends to longer sequence generation and scalable scene composition.
Theoretically, CoPart provides a paradigm for joint modeling of intra-object relationships and cross-modal cues, crucial for interpretable, compositional generative systems and supporting further advances in multi-object scenes, semantic manipulation, and foundational representation learning.
Future Directions
Open challenges remain in automated optimal bounding box specification, assembly alignment, and scaling to unconstrained part counts, as well as extending the framework for fully unsupervised compositional modeling. Integration with interactive systems and incorporation of physical/functional constraints represent next steps.
Conclusion
CoPart establishes a robust framework for high-quality part-based 3D generation through synchronized contextual latents, mutual guidance, and multi-modal conditioning, outperforming SOTA both quantitatively and in user preference. By introducing PartVerse and enabling direct application to editing and articulation generation, it contributes practical and theoretical advances in generative 3D modeling, with broad implications for asset design, manipulation, and automated scene synthesis.