- The paper introduces SAM-GS, a gradient surgery method that mitigates magnitude-based gradient conflicts to enhance convergence in multi-task deep learning.
- It utilizes gradient similarity measures and momentum regularization to optimize gradient aggregation, as evidenced by robust performance on benchmarks.
- The method improves learning stability and task efficiency, paving the way for further research on convergence guarantees and hyperparameter influences.
Gradient Similarity Surgery in Multi-Task Deep Learning
The paper "Gradient Similarity Surgery in Multi-Task Deep Learning" introduces a novel gradient surgery method, Similarity-Aware Momentum Gradient Surgery (SAM-GS), designed to tackle conflicting gradients in multi-task deep learning (MTDL). This method aims to optimize the convergence and learning stability of models handling multiple tasks simultaneously.
Multi-Task Learning and Challenges
Multi-task learning (MTL) architectures are designed to train a single model on multiple tasks by sharing representations and leveraging commonalities among tasks. Despite the efficiency offered by such frameworks, MTDL faces significant challenges due to conflicting gradients which occur when gradients for different tasks diverge in direction or magnitude. These conflicts can lead to suboptimal convergence and inefficiencies in learning.
Conflicting Gradients
Conflicting gradients can be categorized as angle-based or magnitude-based conflicts. Angle-based conflicts arise when gradients point in opposing directions, while magnitude-based conflicts occur when the gradient magnitudes vary substantially across tasks. The SAM-GS method addresses these challenges by employing a gradient similarity measure to modulate optimization dynamics and guide convergence.
Gradient Surgery Methods
Various methods have been proposed to resolve gradient conflicts. Task similarity methods cluster tasks based on compatibility, whereas loss balancing techniques adjust task loss weights dynamically. Gradient surgery methods modify the gradient aggregation process, offering direct solutions for gradient conflicts across multiple tasks.
SAM-GS Methodology
SAM-GS uses a gradient magnitude similarity measure to detect and resolve magnitude-based gradient conflicts. By dynamically adjusting the momentum based on task gradient similarity, SAM-GS optimizes the gradient aggregation process (Figure 1).
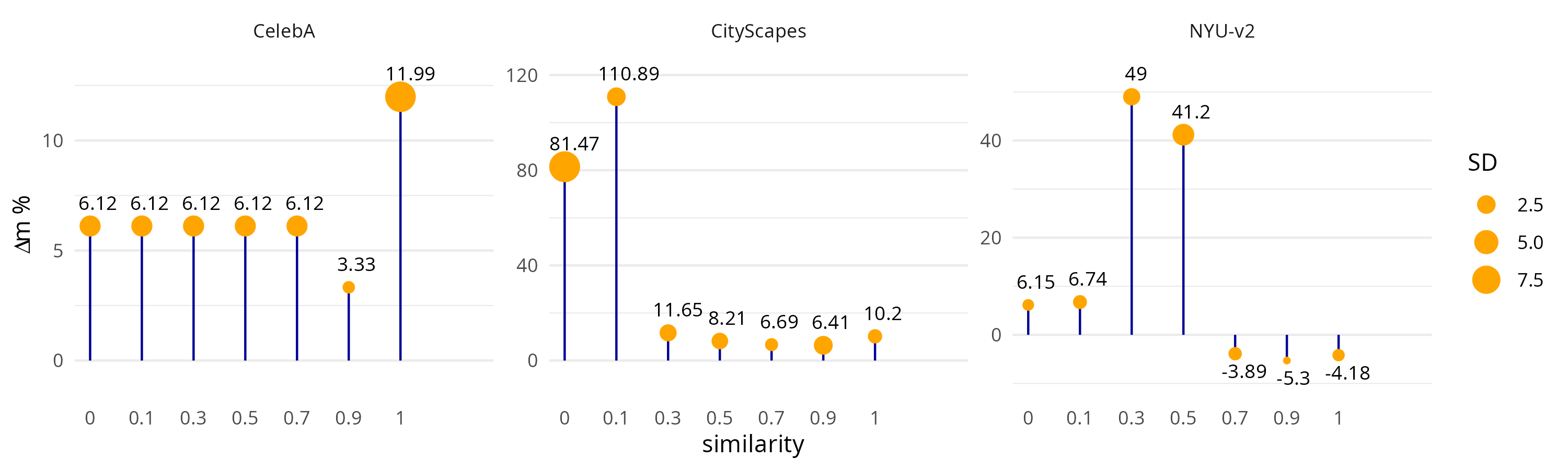
Figure 1: Ablation study over gamma. The plot shows the performance, in terms of Delta m \%, of SAM-GS across three supervised learning settings with gamma values of {0,0.1,0.3,0.5,0.7,0.9,1}.
SAM-GS introduces momentum regularization, which conservatively updates gradients when differences between task gradients are high, thus avoiding undue influence of any single task on model updates. This method also ensures faster learning when gradient similarity is high, leveraging task synergies effectively.
Computational Experiments and Benchmarks
SAM-GS has been rigorously tested against synthetic problems and various multi-task learning benchmarks. Synthetic problems showcase SAM-GS's ability to navigate complex optimization landscapes, revealing the benefits of its adaptive gradient aggregation strategy (Figure 2).
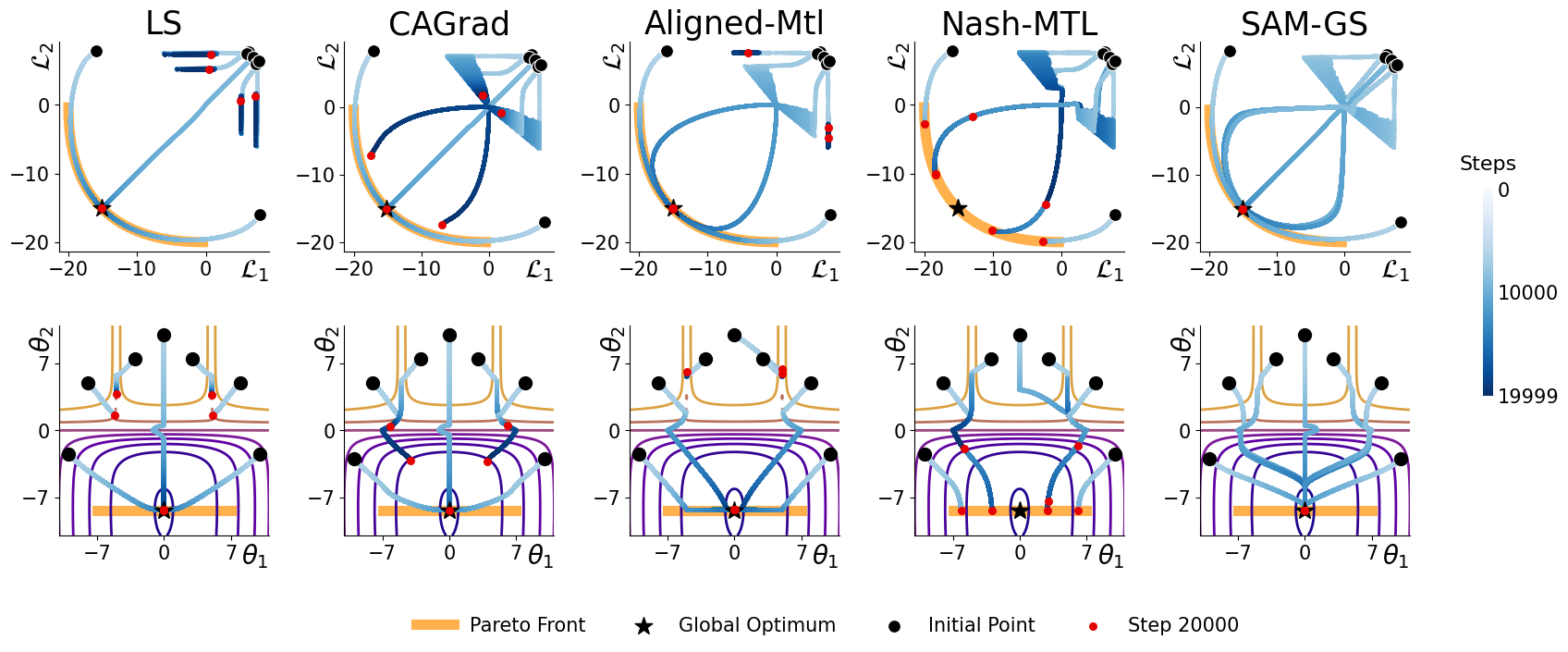
Figure 2: Trajectories for different methods starting from 7 different initial points: Linear Sum (LS) approach using Adam \cite{kingma2014adam}.
The empirical evaluation across benchmarks like CelebA, NYU-v2, and CityScapes demonstrates the robust performance of SAM-GS, with results indicative of its competitive advantage over state-of-the-art methods in handling conflicting gradients (Table 1).
| Method |
CelebA Δm% |
NYU-V2 Δm% |
CityScapes Δm% |
| STL |
- |
- |
- |
| SAM-GS |
3.33 |
-5.3 |
6.41 |
These results validate the effectiveness of SAM-GS in improving convergence and enhancing task efficiency across diverse MTL scenarios.
Conclusion
The Similarity-Aware Momentum Gradient Surgery method presents a strategic innovation in addressing conflicting gradients in multi-task deep learning. By integrating gradient similarity measures into the optimization process, SAM-GS significantly enhances learning stability and efficiency. The favorable results across synthetic and real-world benchmarks highlight its potential for broader applications within AI, fostering effective multi-task model training across various domains.
Future research could focus on theoretical convergence guarantees and richer exploration of hyperparameter effects, enhancing SAM-GS further for broader applicability in MTDL contexts.