- The paper introduces model stitching to map residual streams using affine transformations, enabling effective feature transfer across language models.
- It demonstrates that transferring sparse autoencoders as initializations significantly reduces training FLOPs while preserving performance.
- Feature-level analyses reveal distinct transfer efficiencies for semantic and structural features, supporting universality hypotheses.
Overview of "Transferring Features Across LLMs With Model Stitching" (2506.06609)
The paper introduces a novel approach to transferring features across LLMs through model stitching, utilizing affine mappings between residual streams. This method offers a cost-effective solution to transfer Sparse Autoencoders (SAEs) and other linear components between models of different sizes, demonstrating significant savings in computational resources. The authors explore the universality of representation spaces across models and apply feature-level analyses to quantify transfer efficiency between semantic and structural features.
Introduction
Stitching between LLMs enables the transfer of linear features using affine transformations within residual streams. Models exhibiting similar feature spaces allow SAEs trained on smaller models to serve as effective initializations for larger ones, resulting in substantial savings in training FLOPs. The approach also facilitates transferring probes and steering vectors, preserving ground truth performance in various scenarios.
LLM Stitching
Affine transformations $\mathcal{T_{\uparrow},\mathcal{T_{\downarrow}}$ map residual streams of different models, achieving near-preservation of feature representational fidelity. This stitching process leverages universality within model families and demonstrates compatibility with weak linear representation hypotheses.
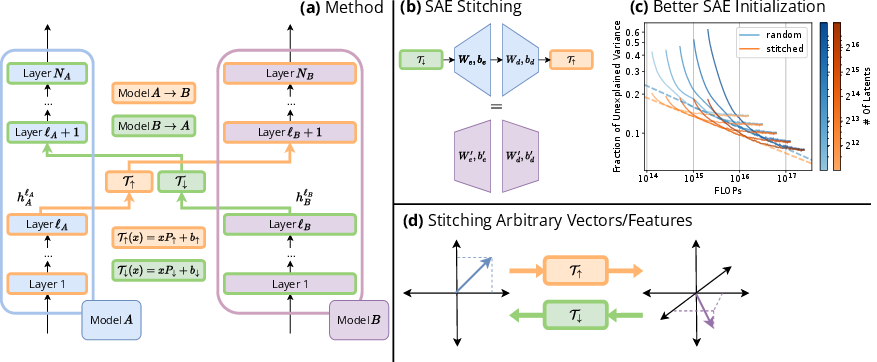
Figure 1: Overview of the main methodologies. (a) We train two affine mappings T concurrently to map between the residual streams of two LLMs.
Transferring SAEs
The paper details a three-step procedure to transfer SAEs from one model to another using the learned transformation mappings. These mappings ensure that transferred SAEs can be employed as initializations for larger models, accelerating their convergence to high explained variance levels and allowing efficient training by leveraging pretrained features.
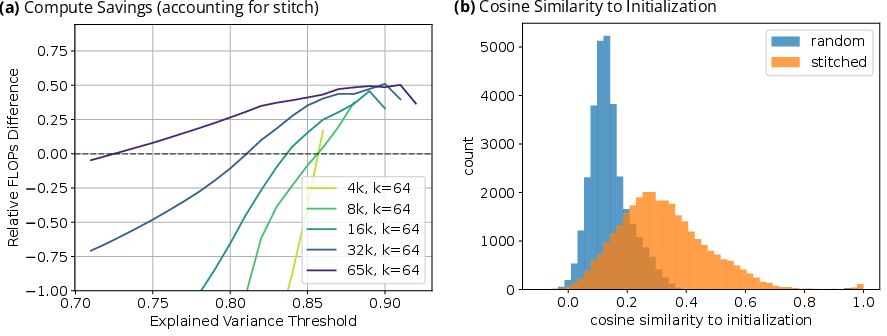
Figure 2: In the Pythia model pair, transferred SAE initialization adjusted by the stitch FLOP count reaches explained variance thresholds in less FLOPs.
Downstream Applications
The stitching approach enables zero-shot transfer of probes and steering vectors without the need for retraining. Testing across various datasets confirms preserved performance, with steering vectors effectively altering model behavior in specific tasks.
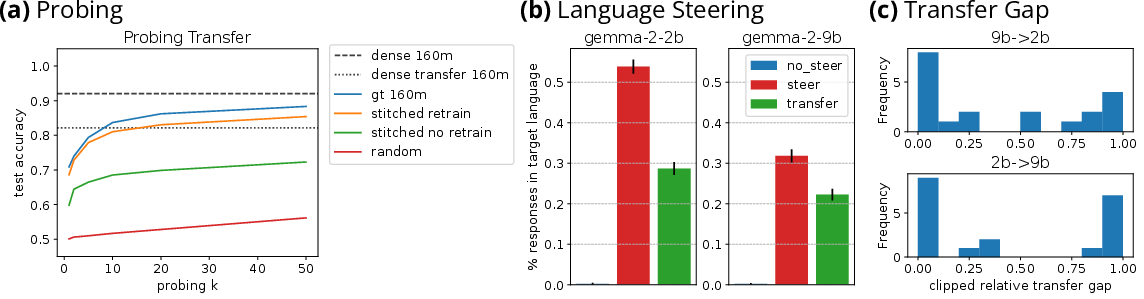
Figure 3: Evaluations of transferred probes stitching from pythia-70m-deduped to pythia-160m-deduped averaged over 8 binary classification datasets.
Feature Analysis
Feature transferability is influenced by categorical distinctions between semantic and structural features. Structural features tend to transfer with higher fidelity, while semantic features exhibit polarization in their transfer efficiency. Universal features like entropy and attention deactivation retain their functional roles post-transfer.
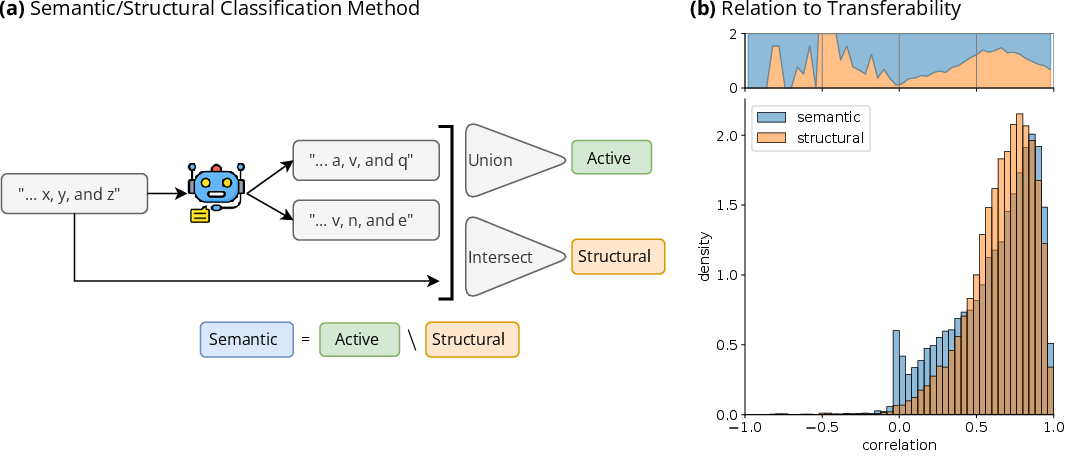
Figure 4: An overview of the feature analysis pipeline for a simple example where 2 augmentations are generated.
Conclusion
This work establishes model stitching as a viable technique for feature transfer across models, demonstrating substantial computational savings and supporting universality hypotheses. By enriching initialization processes with transferred SAEs and extending applications to probes and steering vectors, the study suggests promising directions for efficiently training components of LLMs.
The potential applications, limitations, and future exploration avenues for cross-family model compatibility and token-specific steering suggest numerous opportunities for enhancement of model interpretability and training efficiency.