- The paper presents the LRT Hypothesis, showing that neural networks learn universal basis features expressible as linear combinations across different scales.
- It empirically validates that affine mappings can effectively transfer steering vectors from small models to large ones, preserving semantic behavior.
- The study offers practical benefits in reducing computational costs and theoretical insights into the shared representational structures of neural networks.
Linear Representation Transferability Hypothesis: Leveraging Small Models to Steer Large Models
Abstract Overview
The paper introduces the Linear Representation Transferability (LRT) Hypothesis, proposing that neural networks of varying scales, when trained on similar datasets, can express learned representations as linear combinations of universal basis features consistent across architectures. An affine transformation is hypothesized to exist between the representational spaces of different models, preserving semantic effects of steering vectors transferred from smaller to larger models.
The LRT Hypothesis: A Conceptual Framework
The LRT Hypothesis posits that neural networks trained on similar data learn similar basis features, leading to the possibility of an affine transformation between their representational spaces. This hypothesis is rooted in the notion that shared fundamental structures (e.g., syntax, semantics) are captured by models, irrespective of their scale, thereby creating a universal representation space.
The framework suggests that the hidden states of models, regardless of size, are linear combinations of these universal basis features. This shared space allows the transfer of steering vectors derived from smaller models to larger ones through learned affine mappings. The conceptual framework supports the idea that representational subspaces can be mapped across models, enabling the reuse of steering vectors and effective steering of larger models via smaller ones.
Evaluation and Empirical Validation
The hypothesis is tested by learning affine mappings between hidden states of different model architectures and evaluating steering tasks. The methodology involves training linear mappings that capture the transformation between the representation spaces of models of varying sizes. Steering vectors, or directions associated with model behaviors, are derived from smaller models and mapped to larger ones using these transformations.
Empirical validation indicates that these mappings preserve the steering vectors’ semantic effects, supporting the viability of the LRT hypothesis. The findings suggest that smaller models serve as efficient sources of steering behaviors applicable to larger models, streamlining the process of understanding model behavior across scales.
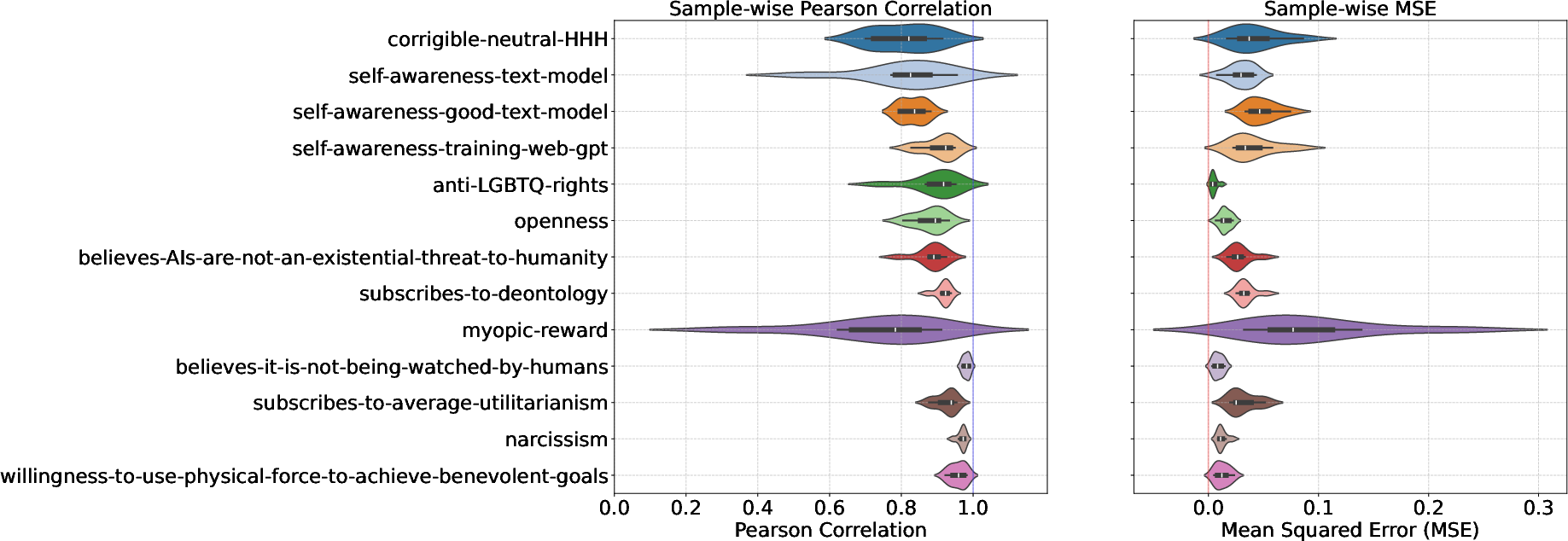
Figure 1: Steering Gemma-9B directly vs. steering Gemma-9B with vectors learned with Gemma-2B, highlighting the correlation and MSE across various tasks.
Practical and Theoretical Implications
The LRT hypothesis has significant implications for both practical applications and theoretical understanding of neural networks:
- Practical Implications: The ability to transfer steering vectors from small to large models could streamline development processes, reduce computational costs, and enhance efficiency in training large-scale models. This capability can significantly impact areas like model tuning and optimization.
- Theoretical Implications: The hypothesis enhances our understanding of the universal structures underlying neural network representations. It opens avenues for further research on the geometry and linearity of model spaces, advancing the theoretical foundation of neural networks.
Future Research Directions
The study encourages exploration in several promising directions:
- Scalability Limits: Understanding the boundaries of linear transferability across model sizes, particularly how effectiveness varies with increasing model scale differences.
- Cross-architecture Transferability: Investigating whether linear representational transfers can be extended to different model architectures, providing a deeper understanding of shared model behaviors across diverse architectures.
- Universal Representation Space: Further research into the existence and properties of a universal representation space could provide insights into model generalization and representational alignment.
Conclusion
The research presents concrete evidence for the LRT hypothesis, showing its efficacy in transferring steering vectors across model scales via affine mappings. The findings underscore the potential of small models in serving as templates or benchmarks for larger models, facilitating a deeper understanding of neural model behavior and an efficient approach to model steering. The implications for model training, inference, and architectural design are vast, pointing to a future where insights developed from small-scale models can be seamlessly integrated and applied to larger-scale neural networks.