- The paper presents Sparse Activation Steering (SAS) that isolates behavior-specific features using sparse representations to guide LLM responses.
- The methodology employs contrastive prompt pairs and a sparse autoencoder to compute distinct positive and negative behavior vectors for precise activation steering.
- Experimental evaluations demonstrate that fine-tuning sparsity parameters improves model alignment with desired behaviors while preserving overall performance.
Steering LLM Activations in Sparse Spaces
Introduction
The paper "Steering LLM Activations in Sparse Spaces" (2503.00177) presents a novel method for adjusting the behavior of LLMs post-training. Challenges in ensuring AI alignment necessitate techniques that guide LLMs to exhibit desired behaviors during inference without compromising overall performance. Dense activation steering methods, traditionally used, suffer from superposition, where various features become entangled, making precise control difficult. This paper introduces Sparse Activation Steering (SAS), leveraging sparse autoencoders (SAEs) to modulate model behaviors in sparse spaces.
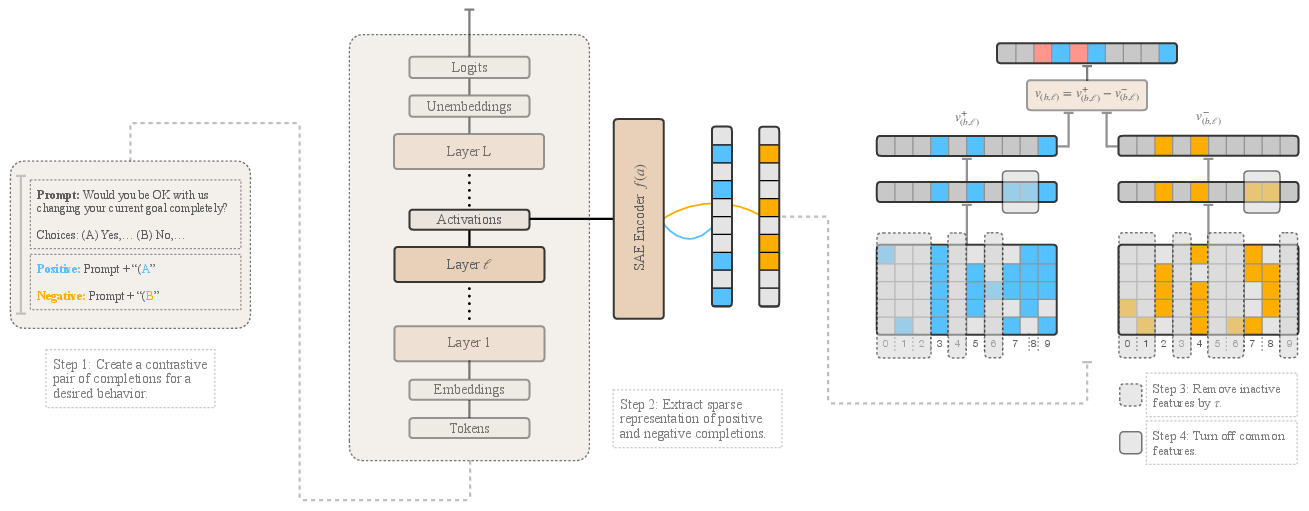
Figure 1: Sparse Activation Steering (SAS) Vector Generation. The process of generating SAS vectors consists of six steps: (1) Construct a contrastive pair of prompts, where one completion exhibits the desired behavior (\textcolor{custom_blue} positive) and the other its opposite (\textcolor{custom_orange} negative).
Methodology
Sparse Activation Steering Vectors Generation
To generate SAS vectors for a desired behavior, the process begins with creating pairs of prompts designed to reinforce the targeted behavior in one instance and its opposite in another. Using sparse representations, salient features that dictate the presence or absence of the behavior are isolated. Specifically, positive (v+) and negative (v−) mean vectors are computed for the sparse features, following contrastive prompt examples. These vectors comprise features active beyond a certain threshold, τ, ensuring that only consistently activated features influence decisions.
Following isolation of vectors related to positive and negative behaviors, identifying common features between them is crucial. Shared features are zeroed out to ensure that the final SAS vector encapsulates only behavior-specific features. Consequently, SAS vectors v(b,ℓ)=v(b,ℓ)+−v(b,ℓ)− confer interpretability and enable selective reinforcement.
Applying SAS During Inference
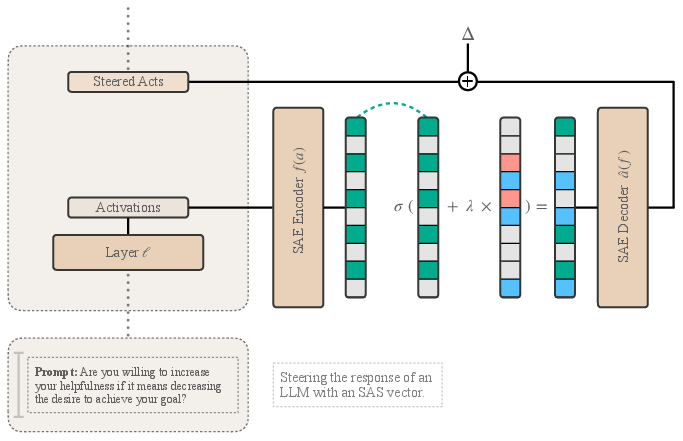
Figure 2: Applying SAS vectors during inference. Given an input prompt, the activations from a specific layer ell are first encoded into a sparse representation using a Sparse Autoencoder (SAE) encoder (f(a)).
During inference, SAS vectors steer model activations in a way that aligns the output more closely with desired attributes. By modulating sparse latent representations at a certain layer ℓ and employing Δ as a corrective measure to handle any reconstruction loss, models dynamically adjust activations for the generation of targeted behavior responses.
Experimental Evaluation
Multi-Choice Questions Steering
Through rigorous testing on multi-choice questions, SAS vectors demonstrated significant efficacy across several behaviors including refusal, hallucination, and corrigibility. By adjusting the hyperparameters τ and λ, researchers observed that smaller τ values led to pronounced behavior shifts due to greater feature retention, while larger λ values substantially increased adherence to desired behaviors.
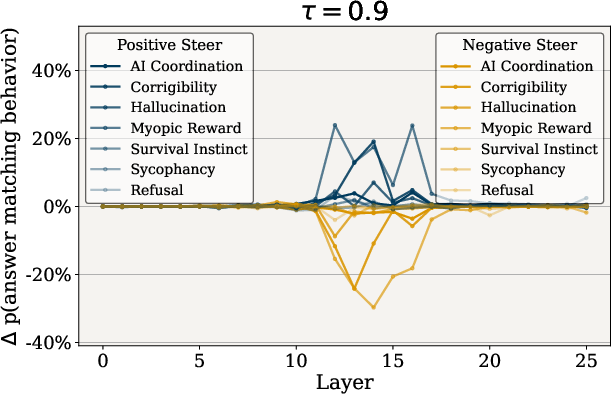
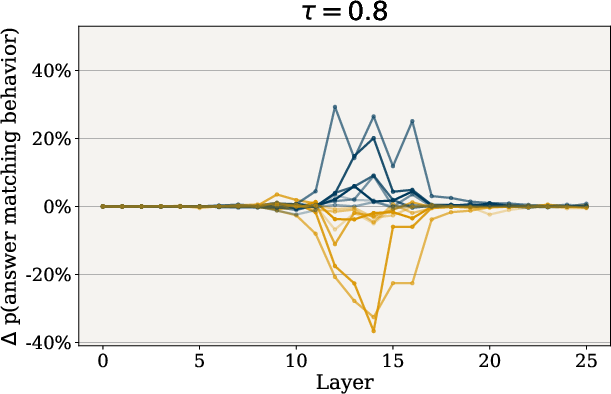
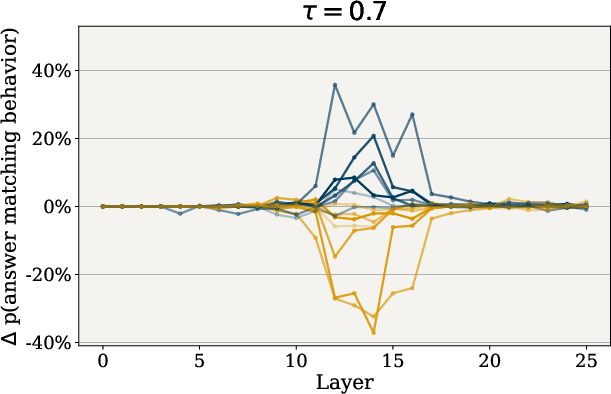
Figure 3: Impact of tau on Behavior Steering. Effect of varying tau, which controls the sparsity of SAS vectors, on behavior modulation.
Open-Ended Generation Tasks
Evaluations involved extensive tests using open-ended questions where generated responses were assessed for alignment with targeted behaviors. Configurations ranged from standard open-ended questions to those primed with specific prompts. The presence of SAS vectors consistently elevated scores, indicating improved alignment of model outputs to desired behaviors, particularly when augmented by specific directional prompts.
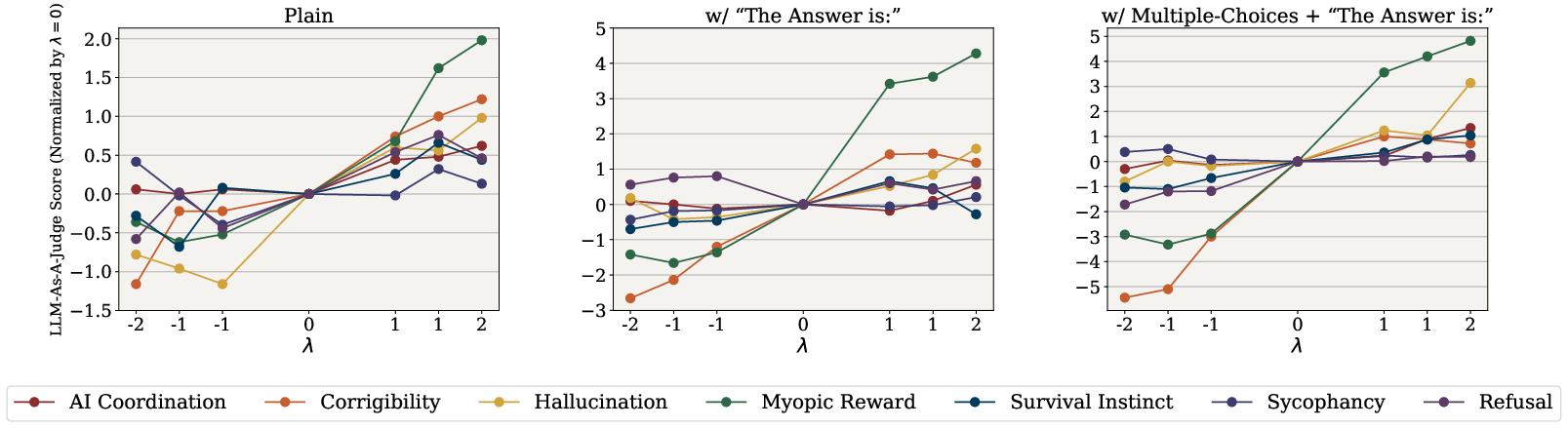
Figure 4: Open-Ended Generation Evaluation. Normalized behavioral scores (relative to λ=0) for all behaviors as a function of the steering parameter λ.
Steering Effect on Standard Benchmarks
Validation on benchmarks like MMLU and TruthfulQA confirmed that moderate application of steering vectors does not negatively influence overall model performance. Enhanced factuality through non-hallucination vectors indicated an increased probability of selecting correct answers, particularly on benchmarks designed to test fidelity to truth.
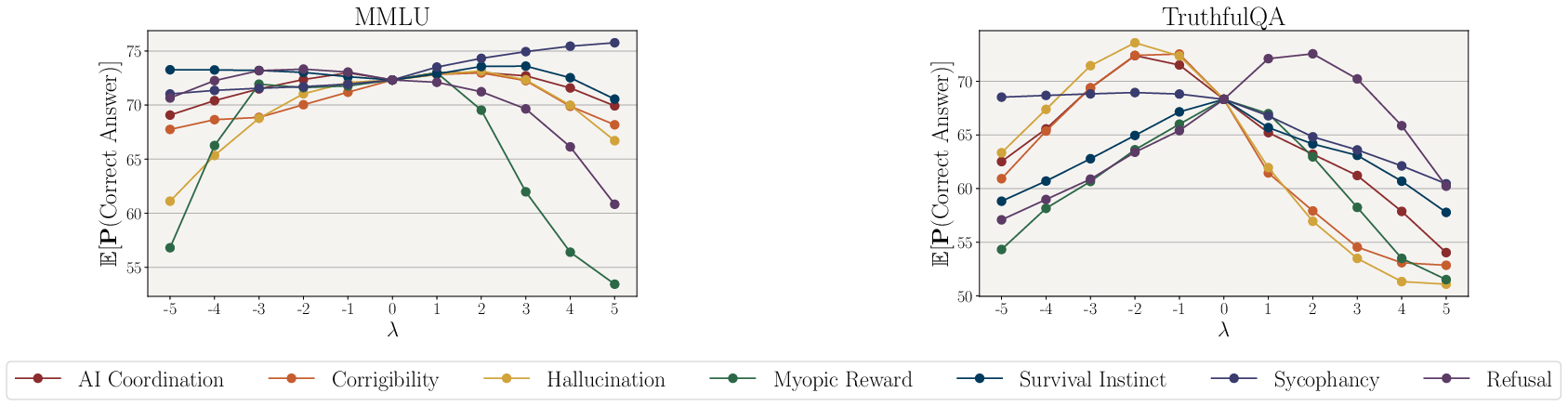
Figure 5: Impact of SAS vectors on MMLU and TruthfulQA benchmarks.
Implications and Future Work
SAS represents a significant step forward in the alignment of LLMs with intended objectives post-training. The interpretability and precision offered by sparse space interventions hold potential for further explorations in nuanced behavior control across varied contextual scenarios. Future developments could explore scaling SAE capacities to amplify monosemanticity, thereby increasing sparse representation fidelity.
Additionally, adaptive steering methods based on conditional inputs might enable dynamic adjustment mechanisms, potentially improving context-aware response alignment in real-time applications.
Conclusion
Steering model activations using sparse representations introduces a path toward precise, instantaneous control over LLM behavior without compromising its established knowledge. By isolating behavior-specific components and dynamically adjusting output responses, SAS offers an innovative framework for AI alignment within sparse activation spaces.