- The paper introduces mean-centring to isolate target behavior by subtracting the overall activation mean from target activations.
- It shows that applying mean-centring in GPT-2 reduces toxic outputs while maintaining coherence.
- The method also enhances genre steering and function vector extraction, demonstrating robust performance across varied tasks.
Improving Activation Steering in LLMs with Mean-Centring
Introduction
The paper "Improving Activation Steering in LLMs with Mean-Centring" addresses a critical challenge in the field of LLMs: the difficulty in finding effective steering vectors due to a lack of understanding about feature representation. The authors propose an innovative technique called mean-centring, which is designed to enhance the process of activation steering by creating more effective steering vectors across various natural language tasks, such as steering away from toxicity and directing story genre.
Mean-Centring as a Method
The central contribution of the paper is the introduction of mean-centring for steering vectors, achieved by averaging activations from a target dataset and subtracting the mean of all training activations. This method effectively isolates the vector associated with the desired behavior from the consistent bias present in activations.
The use of mean-centring is illustrated through both practical implementation and theoretical groundwork. By employing mean-centring, the method allows better distillation of activation vectors that encode target behaviors, thus enhancing task performance when applied to various contexts such as reducing model output toxicity and altering linguistic genre parameters.
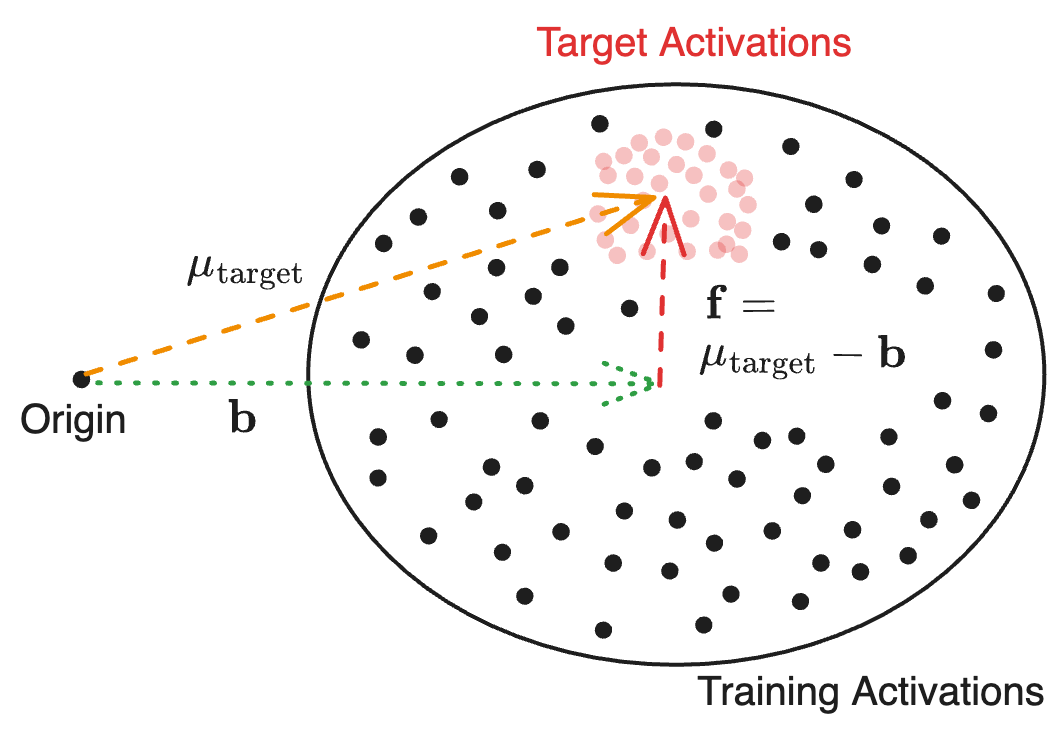
Figure 1: An example of mean-centring illustrated on a set of highly anisotropic activations (i.e. offset from the origin).
Experimental Evaluations
Toxicity Removal
The study conducts experiments on toxicity removal by steering model outputs using the mean-centred method. Using GPT-2 Small, prompts derived from toxic comments are processed with different steering methods. Mean-centring notably demonstrates superior performance in generating non-toxic text compared to non-steered methods and contemporary methods like ActAdd. This empirically validates the advantage of mean-centring for reducing toxic content without compromising model coherence.
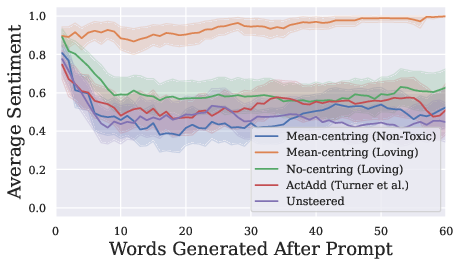
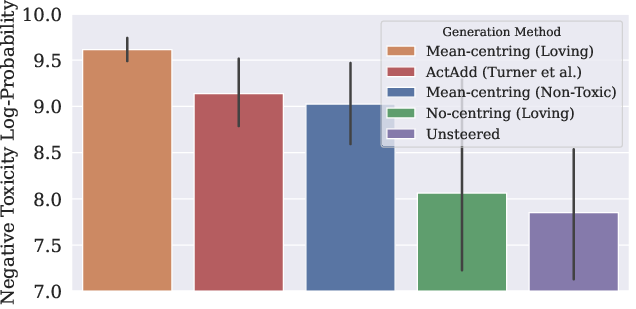
Figure 2: Changes in mean positive sentiment of generated text with each word generated for the different methods (with 95% CI bands).
Genre Steering and Function Vector Extraction
Beyond toxicity control, the paper explores steering story genres and extracting function vectors. By employing mean-centring, generated outputs in story completion tasks more robustly align with desired genres, showcasing the method's efficacy in modifying LLM outputs in nuanced contexts.
Another significant contribution is the improvement in extracting function vectors. By utilizing mean-centring, these vectors now demonstrate enhanced triggering of specific functions, improving task accuracies significantly across several tasks compared to baseline methods.
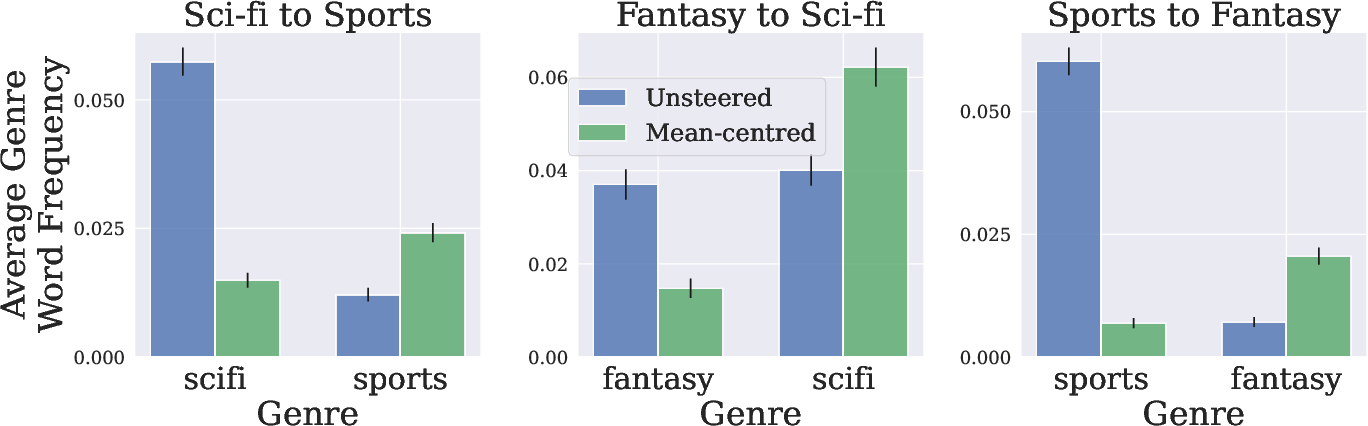
Figure 3: Genre-word frequencies in generated text continuing stories of a given genre. Text generated without steering (Unsteered) is compared to text generated using mean-centring with a target genre's dataset (Mean-centred).
Anisotropy in Contextual Embeddings
The paper underscores the anisotropic nature of LLM activations and its impact on steering. This bias, where activations are offset consistently from the origin, is addressed by mean-centring, which realigns the vector space for more precise representation of target behaviors, thus confirming improvements in steering accuracy and consistency across various layers and model types, including GPT-J and Llama-2.
Conclusion
The research establishes mean-centring as a powerful technique to improve activation steering in LLMs, enhancing the targeting of complex behaviors without explicit counterbalancing concepts. This method not only improves task-specific outcomes but also broadens the scope of application for activation steering, making it a valuable tool for LLM behavioral control efforts. Future work could further refine mean-centring techniques or explore additional contexts where anisotropic properties are significant, potentially leading to even more sophisticated steering methodologies.