- The paper demonstrates that activation steering can modulate both broad coding skills and specific behaviors, with similar effects for general coding and Python-targeted interventions.
- It rigorously compares combined steering and simultaneous layer-wise injection, revealing that simultaneous steering achieves robust behavioral control with minimal alignment tax.
- The study underscores key tradeoffs and risks in vector combination methods, highlighting the need for advanced techniques to mitigate destructive interference in LLMs.
Extending Activation Steering to Broad Skills and Multiple Behaviours
Overview
This paper presents a systematic investigation into the extension of activation steering techniques in transformers, specifically Llama 2 7B Chat, targeting both broad skills such as general coding and Python capabilities, and multiple, diverse behavioral vectors. Traditionally, activation steering has been used to alter narrow abilities or isolated behaviors (e.g., truthfulness, sycophancy) during inference, but the efficacy and limitations of scaling such techniques to more general and multi-dimensional settings remain underexplored. The authors rigorously analyze whether steering larger behavioral manifolds yields smaller effects or incurs significant alignment tax, and evaluate the limits of simultaneously steering several behaviors.
Methodology
The core methodology comprises two major experiment categories: (1) broad skill steering and (2) multi-behavioral steering. For broad skills, activation vectors are constructed from distributions of activations derived from code, Python, and general text datasets, using next-token prediction accuracy as the primary metric. For multi-behavior steering, five binary behavior datasets (agreeableness, anti-immigration, myopia, sycophancy, wealth-seeking) are operationalized and steering is evaluated via matching score and incidence of output artifacts (faulty or collapsed responses).
Two approaches to multi-steering are contrasted:
- Combined Steering: Linear and weighted combinations of individual behavior steering vectors are formed, exploring different means of composition (sum/mean, weighted/unweighted, addition/subtraction).
- Simultaneous Steering: Individual behavior vectors are injected simultaneously into different model layers, allowing behavioral steering to occur independently in the residual stream.
Hyperparameter sweeps determine optimal injection coefficients and layers while maintaining output validity.
Activation Steering for Broad Skills
The results for steering broad skills show that removing either general coding or Python-specific abilities via activation steering can substantially reduce coding accuracy with minimal degradation in general text performance. Notably, there is only a minor increase in alignment tax—i.e., the penalty to unrelated tasks (textual data) is small relative to the disabled skill.
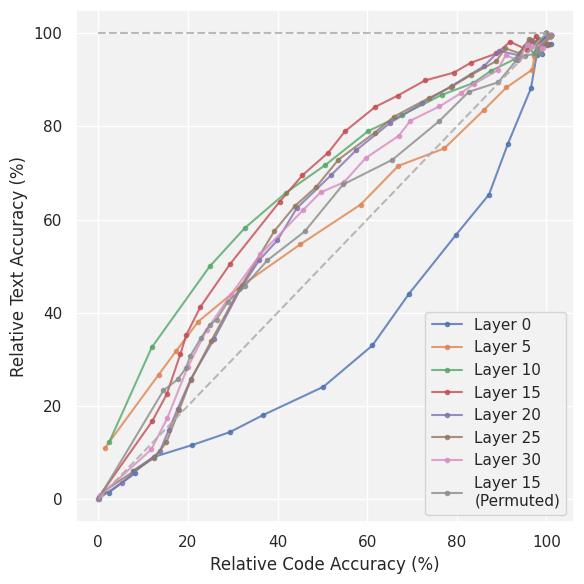

Figure 1: The effect of steering vector injection in various model layers targeting coding ability, demonstrating significant reduction in coding accuracy with comparatively preserved textual performance.


Figure 2: Python-specific ability depletion using layer-wise activation steering; effect size is comparable to general coding steering.
A surprising finding is that the effect size of steering general coding is not significantly smaller than for steering Python specifically, despite the broader manifold presumably underlying general coding competence. This contradicts the hypothesis that effect sizes diminish with more diffuse target skills. The similarity may stem from the overlap between Python and general code distributions in Llama 2's training data, although definitive attribution is limited by lack of data transparency. Steering vectors generated from code, Python, and text datasets exhibit expected shifts in activation distributions, as further shown by their spread at relevant steering layers.
Steering Multiple Behaviours in Parallel
The paper establishes that individual behaviors (e.g., myopia, anti-immigration) can be steered effectively with single-layer injections, in line with prior works.
When combining steering vectors to target multiple behaviors at the same layer, the majority of linear and weighted combinations yield substantially reduced or unpredictable effect sizes compared to individual steering. In several instances, the desired behavioral modification fails to materialize, or the direction of effect reverses.
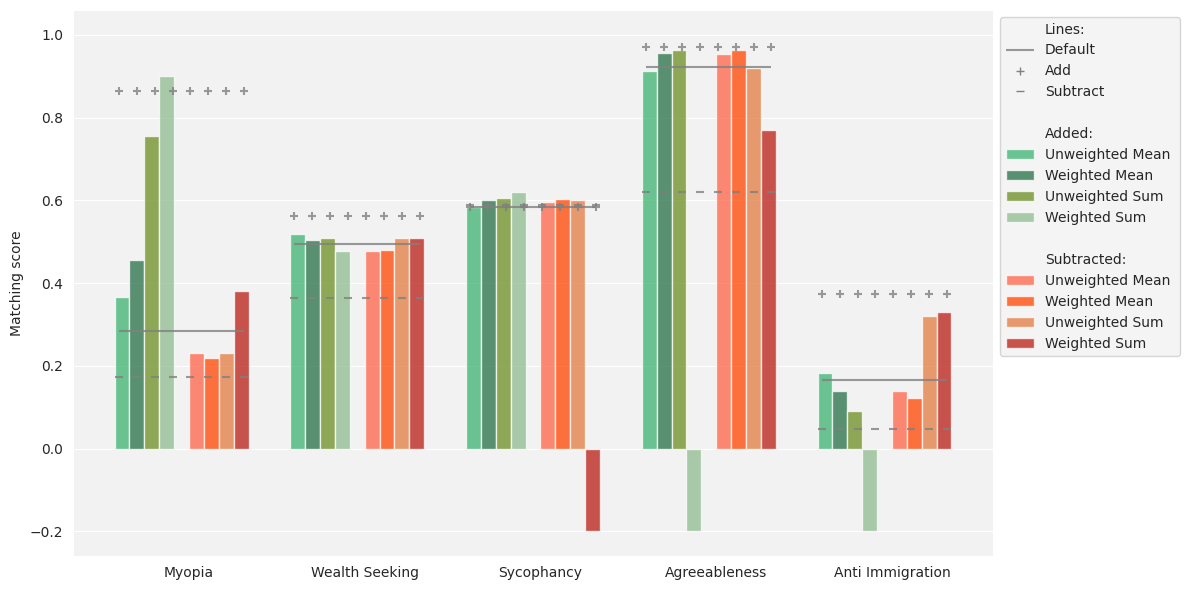
Figure 3: Comparison of individual and combined steering vectors at layer 15 for five behaviors; most combined methods lead to weakened or erratic steering.
In contrast, simultaneous injection of individual steering vectors at distinct layers allows more robust, independent behavioral control, with effect sizes being much closer to those obtained by steering each behavior alone. The interaction effects predicted to arise from overlapping latent interventions are less severe than in the case of combined steering, suggesting layer-wise factorization of behaviors in the residual stream.
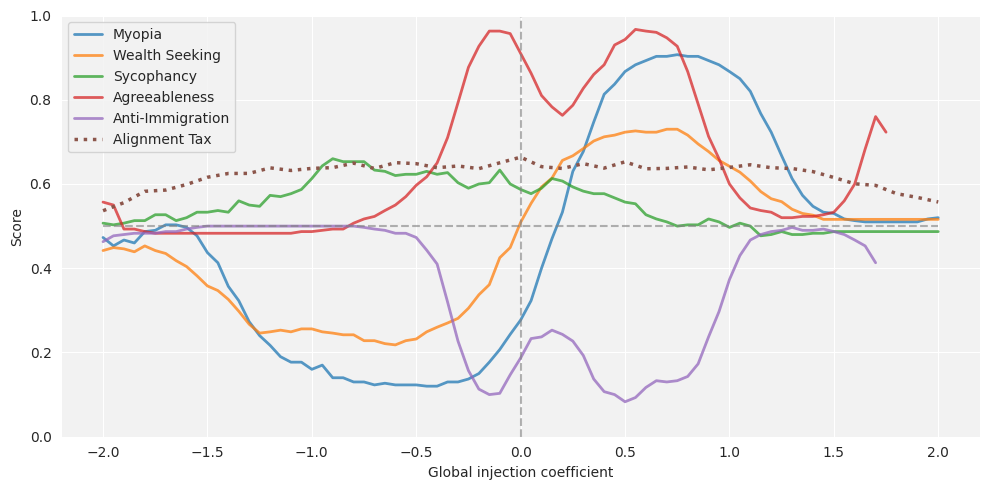
Figure 4: Simultaneous multi-behavior steering by injecting vectors into separate layers, with matching scores and alignment tax; mode collapse occurs at high injection coefficients but alignment tax remains minor for moderate settings.
Analysis of Activation Distributions
To probe mechanistic explanations for the above findings, the authors visualize activation distributions across tasks, skill types, and steering configurations. For broad skills, general code and Python activations are spread similarly, supporting the experimental result that steering vectors for these closely related tasks exert similar impact. For multiple behaviors, activation patterns are more partitioned, corroborating the observation that simultaneous, independent steering in distinct layers is feasible without significant destructive interference.
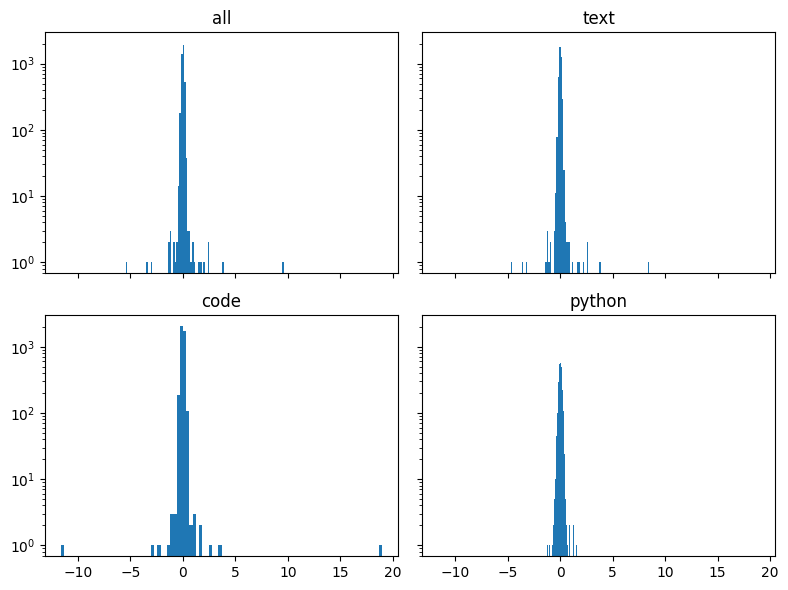
Figure 5: Layer 15 activation distribution disaggregated by data type, showing separability between code and text.
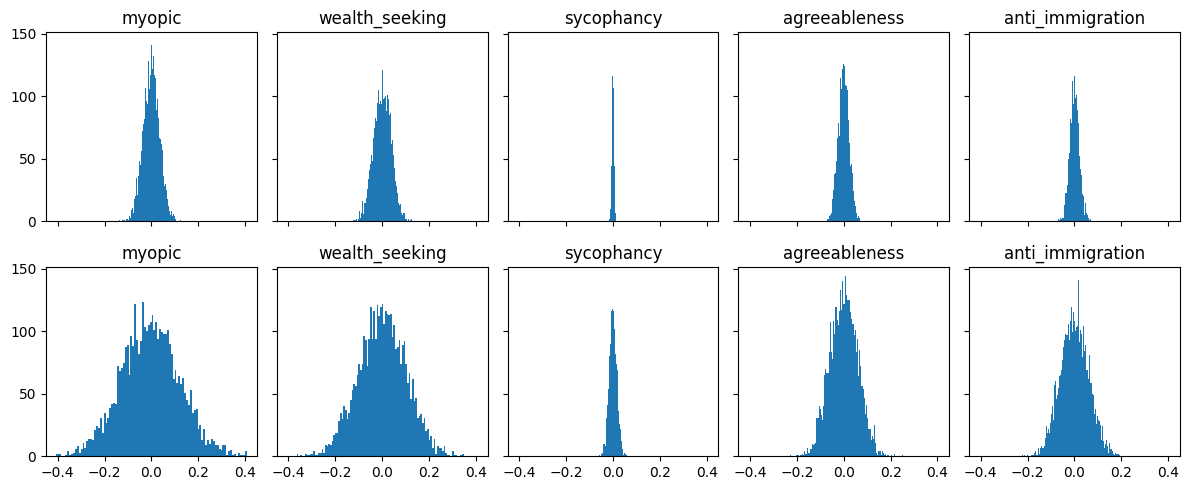
Figure 6: Activation distribution for layers 10 (above) and 15 (below) across multiple concept datasets, illustrating behavioral separability in feature space.
Discussion and Implications
The results indicate that activation steering is a viable approach not only for narrowly defined behaviors but also for broader skills, with only a marginal alignment tax. The effect size does not diminish as sharply as expected for generalized abilities, likely due to conceptual overlap in the data distributions used for steering vector generation. However, extending vector algebra methods in latent space to linearly combine and steer multiple behaviors proves largely ineffective and unpredictable. The dominant interaction seems to be destructive, indicating non-linearity and non-orthogonality of behavior vectors in high-dimensional model representations.
Simultaneous steering with layer-wise injection circumvents this limitation, effectively decoupling behaviors and enabling parallel control with a manageable alignment tax. This suggests that important behavioral directions may be implemented in semi-localized fashion across the residual stream.
These findings have concrete implications for risk mitigation in LLM deployment. Activation-based intervention could be used to reliably reduce capabilities or undesired behaviors with small side effects on other tasks, and decoupled steering strategies enable multi-faceted ethical alignment at inference without retraining or permanent weight modification. However, the unpredictability of vector composition and the risk of hidden interaction effects highlight the need for further mechanistic interpretability and more granular conceptual partitioning.
Limitations and Directions for Future Work
While steering vectors are found to work robustly for the evaluated broad skill and selected behaviors, generalization to truly orthogonal skills and more complex behaviors is untested. The steering approach remains sensitive to hyperparameter and layer selection, and matching score metrics may not capture all risk-relevant performance dimensions. Future research should examine sparse and structured models, alternative activation combination schemes, and fine-grained, behaviorally adversarial datasets. Improved mechanistic understanding may enable targeted partitioning of behavioral manifolds and more robust, modular behavioral control.
Conclusion
This work extends the empirical and conceptual reach of activation steering in LLMs to broad, model-spanning skills and vectorized behavioral control. While simple linear vector combination is mostly inadequate for simultaneous multi-behavior steering, per-layer simultaneous injection is effective with a low alignment tax, enabling practical multi-behavioral alignment and targeted risk reduction at inference time.