- The paper introduces a technique to extract steering vectors that enable control over specific reasoning behaviors in LLMs.
- It employs the Difference of Means method to identify and manipulate reasoning patterns such as backtracking, uncertainty, and example testing.
- Experimental results on DeepSeek-R1-Distill models confirm the causal impact of steering vectors in modulating model reasoning.
Steering Reasoning in Thinking LLMs
This paper (2506.18167) introduces a method for controlling the reasoning processes of thinking LLMs by identifying and manipulating specific reasoning behaviors using steering vectors. The approach focuses on DeepSeek-R1-Distill models and demonstrates the ability to modulate behaviors such as expressing uncertainty, generating examples for hypothesis validation, and backtracking in reasoning chains. By extracting and applying steering vectors, the authors provide a practical method for steering reasoning processes in a controlled and interpretable manner.
Methodology
The methodology involves several key steps, including identifying reasoning behaviors, extracting steering vectors, and evaluating their causal impact.
Identifying Reasoning Behaviors
The authors first identified a set of reasoning behaviors exhibited by thinking models, including:
- Initialization: Rephrasing the task and articulating initial thoughts.
- Deduction: Deriving conclusions based on current approach and assumptions.
- Knowledge Augmentation: Incorporating external knowledge to refine reasoning.
- Example Testing: Generating examples or scenarios to validate hypotheses.
- Uncertainty Estimation: Explicitly stating confidence or uncertainty.
- Backtracking: Abandoning the current approach and exploring alternatives.
These behaviors were identified through an examination of reasoning chains generated by DeepSeek-R1 and GPT-4o.
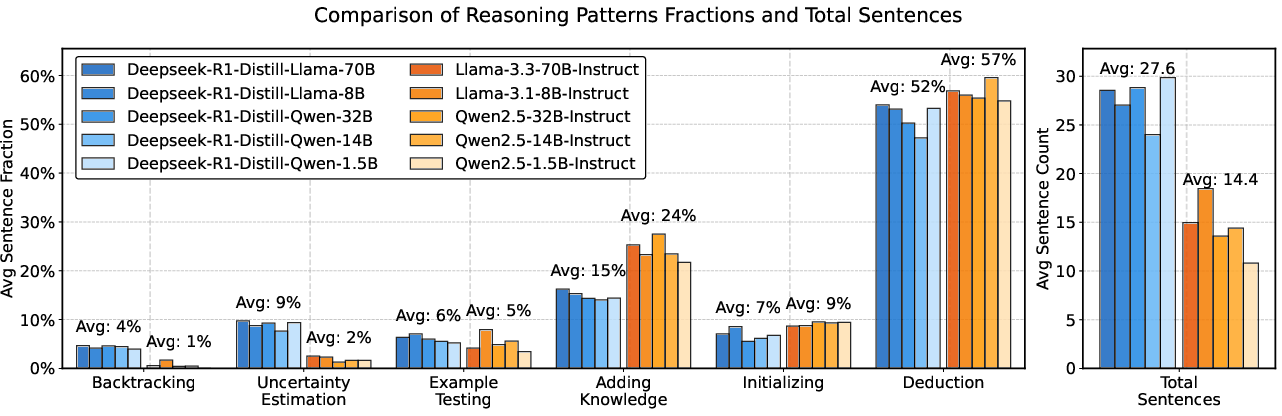
Figure 1: Comparison of behavioral patterns between DeepSeek-R1-Distill models and baseline models, showing differences in the frequency of reasoning behaviors.
Steering vectors were extracted using the Difference of Means method. Contrastive datasets were constructed to represent the presence or absence of a specific reasoning behavior. The Difference of Means vector was then computed as the difference in mean activations between these datasets:
u=∣D+∣1pi∈D+∑a(pi)−∣D−∣1pj∈D−∑a(pj)
where D+ and D− represent datasets with and without the behavior, respectively, and a(pi) represents the activations of the model components.
Locating Causally Relevant Activations
To extract robust steering vectors, the authors identified the activations where these vectors are linearly represented within the model, focusing on the residual stream activations. This process involved two steps: identifying relevant token positions and determining causally relevant layers. Attribution patching was employed to evaluate which layers contribute causally to the behavior in question.
The patching effect is approximated as:
ΔL≈(uℓc)T⋅∂aℓ∂L(xclean∣do(aℓ=aclean)),
where uℓc=(aℓpatched−aℓ).
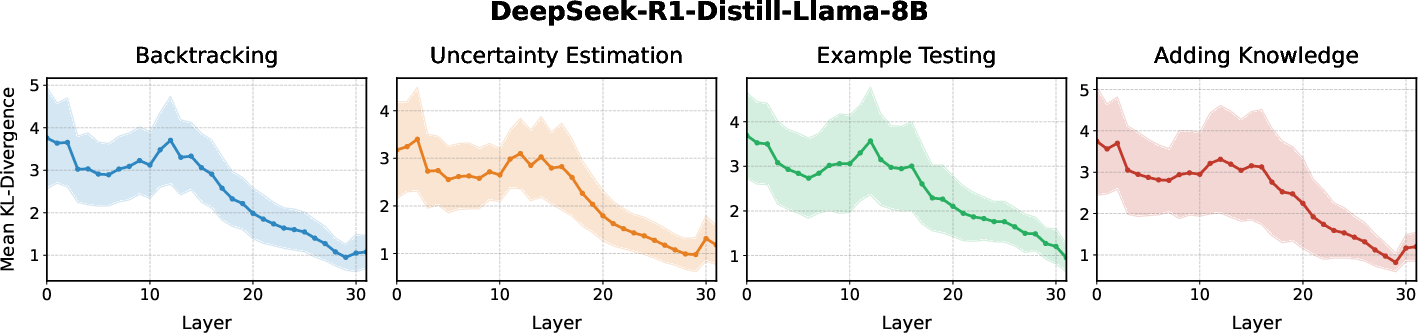
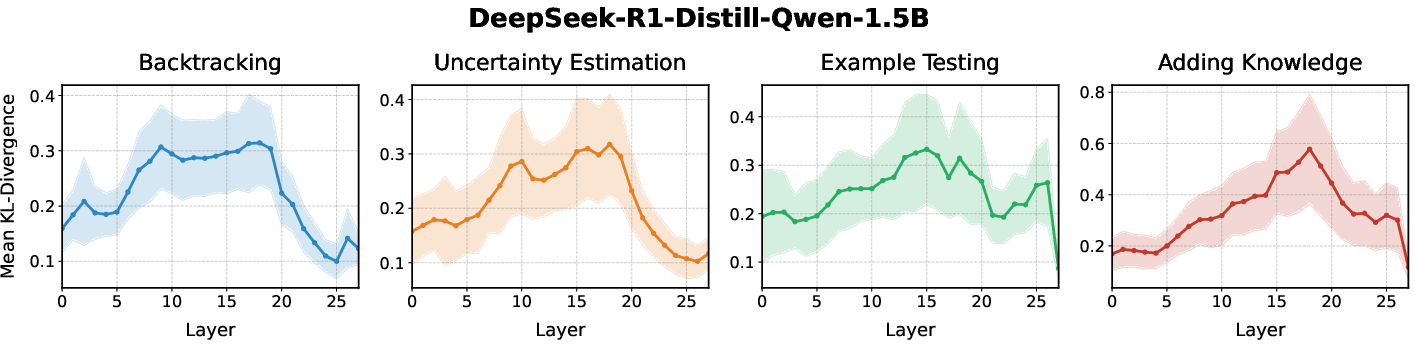
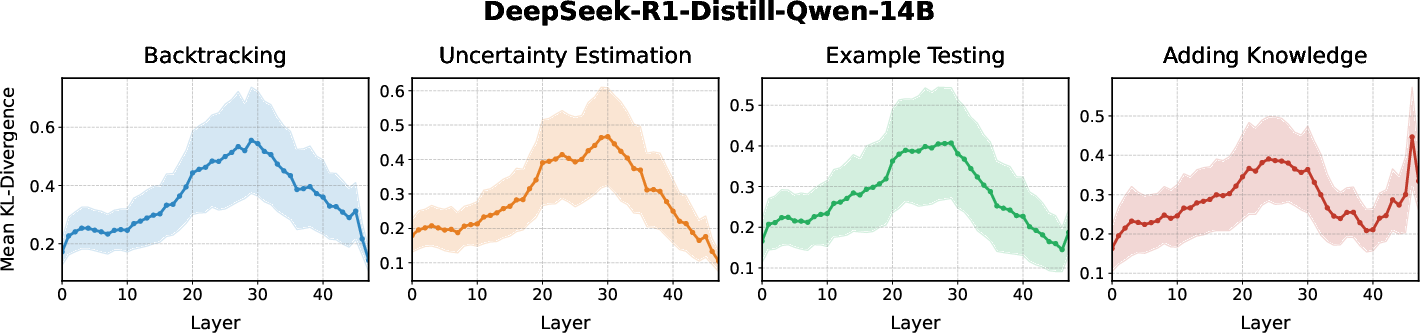
Figure 2: Causal impact of candidate steering vectors across model layers, measured by KL-divergence.
Evaluating Steering Vectors
The effectiveness of the extracted steering vectors was evaluated by applying them to the selected layers and observing their influence on the model's reasoning process. Steering was implemented by adding or subtracting the extracted steering vectors to the residual stream activations at inference time. This intervention allowed for the modulation of behaviors such as backtracking, uncertainty estimation, and example testing.
Results
The results demonstrate that the extracted vectors effectively control the model's reasoning patterns. Positive steering increases behaviors such as backtracking and uncertainty estimation, while negative steering reduces them. These effects are consistent across different DeepSeek-R1-Distill models, reinforcing the hypothesis that thinking LLMs encode these reasoning mechanisms as linear directions in their activation space.

Figure 3: Steering on DeepSeek-R1's backtracking feature vector changes the model's behavior.
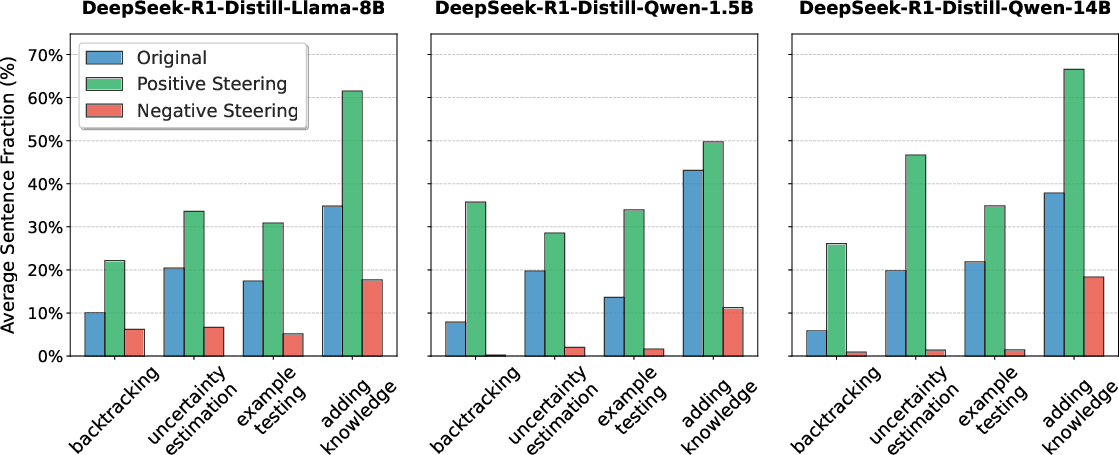
Figure 4: Effect of applying the steering vector for each reasoning behavior across different distill models, showing changes in the fraction of tokens exhibiting each behavior.
The paper references previous work on steering and interpreting LLMs by identifying meaningful directions or features within their internal representation spaces. These include methods for extracting latent steering vectors, activation engineering, and contrastive activation addition. The authors also discuss related work focusing on leveraging internal representations for reasoning and chain-of-thought.
Conclusion
The paper concludes by highlighting the effectiveness of the proposed steering approach for controlling reasoning behaviors in thinking LLMs. The ability to adjust specific aspects of the reasoning process through steering vectors opens new possibilities for adapting these models to different tasks and requirements.
The authors note limitations of their work, including potential inaccuracies in the automated annotation process and the need to generalize findings to other models. Future research directions include developing more robust annotation methods and extending the research to a broader range of models.