Improving LLM Reasoning through Interpretable Role-Playing Steering
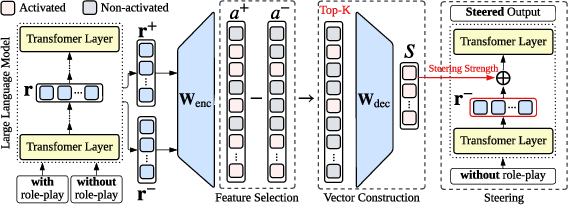
Abstract: Role-playing has emerged as an effective technique for enhancing the reasoning capabilities of LLMs. However, existing methods primarily rely on prompt engineering, which often lacks stability and interpretability. In this paper, we introduce Sparse Autoencoder Role-Playing Steering (SRPS), a novel framework that identifies and manipulates internal model features associated with role-playing behavior. Our approach extracts latent representations from role-play prompts, selects the most relevant features based on activation patterns, and constructs a steering vector that can be injected into the model's residual stream with controllable intensity. Our method enables fine-grained control over role-specific behavior and offers insights into how role information influences internal model activations. Extensive experiments across various reasoning benchmarks and model sizes demonstrate consistent performance gains. Notably, in the zero-shot chain-of-thought (CoT) setting, the accuracy of Llama3.1-8B on CSQA improves from 31.86% to 39.80%, while Gemma2-9B on SVAMP increases from 37.50% to 45.10%. These results highlight the potential of SRPS to enhance reasoning ability in LLMs, providing better interpretability and stability compared to traditional prompt-based role-playing.

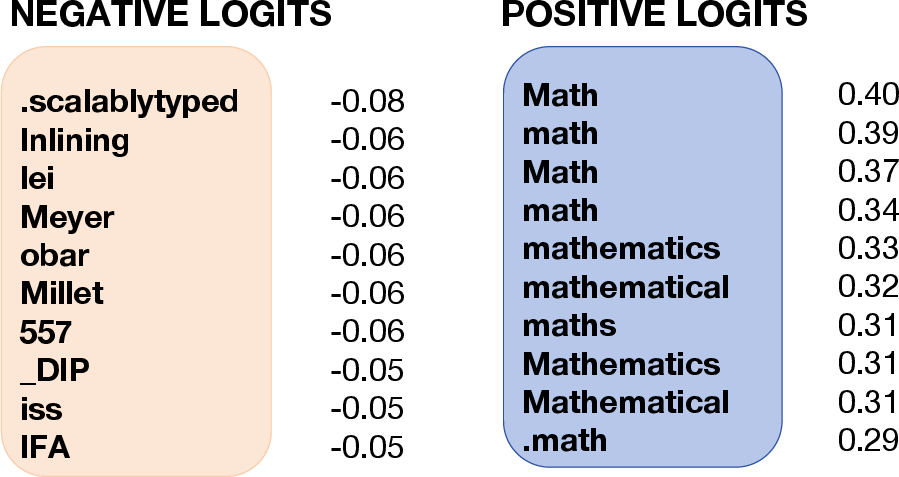

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of gaps, uncertainties, and unexplored directions that remain after this paper. Each point is framed to be actionable for future research.
- External validity to larger, more capable models: The method is only tested on 2B–9B models; its effectiveness, stability, and safety on ≥70B LLMs and newer architectures remain unknown.
- Domain coverage is narrow: Evaluation is limited to arithmetic (GSM8K, SVAMP) and commonsense (CSQA); performance on logical reasoning, scientific QA, programming, formal proofs, legal/medical tasks, and multi-modal reasoning is unexamined.
- Cross-lingual generalization: All experiments are in English; it is unclear whether SRPS works across languages, particularly for non-Latin scripts and translation-heavy tasks.
- Task- and dataset-specific steering vectors: Steering vectors are constructed using N=1,000 training sample pairs per dataset; their portability across datasets, roles, and tasks (including unseen tasks) is not tested.
- Cross-model transferability: The paper does not examine whether steering vectors (or feature indices) learned on one model can transfer to another (e.g., from Gemma2-9B to Llama3.1-8B) or how to align SAE latents across models.
- Baseline breadth: SRPS is not compared against the strongest prompt-based role-play frameworks, activation steering baselines (e.g., in-context vectors), ReFT, or lightweight fine-tuning/LoRA; relative merit to state-of-the-art is unresolved.
- Stability quantification: Claims of improved stability are not backed by systematic variance analyses (e.g., performance distributions across prompt perturbations, seeds, temperature settings, or input noise) for both prompting and SRPS.
- Layer choice and injection strategy: The method fixes a single SAE layer and injects at “last token at layer l”; there is no systematic ablation of which layer(s), token positions, or multi-layer/multi-token injection schedules yield the best trade-offs.
- Scaling factor selection: The steering intensity λ is tunable but lacks an input-adaptive or principled selection method; sensitivity analyses and automatic calibration strategies are not provided.
- Feature selection hyperparameters: The threshold θ and balance parameter β (for s_i) are introduced without comprehensive ablations; guidance for robust, model-agnostic tuning is missing.
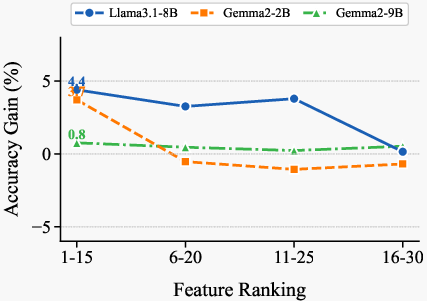
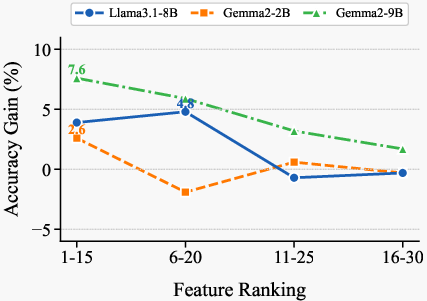
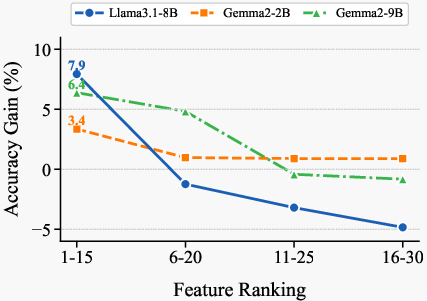
- Number of features k: k=15 is taken from prior work; thorough exploration of k across models and tasks (including adaptive k selection) is not conducted.
- Negative feature steering: The method focuses on positively shifting role-relevant features; it does not examine whether suppressing negatively-differential features (or adding negative steering) improves reasoning.
- Causal mechanism testing: Interpretability relies on Neuronpedia descriptions and logit associations; causal tests (knock-in/knock-out of individual latents, counterfactual steering) to demonstrate that specific features cause performance gains are absent.
- Reasoning–role disentanglement: The study does not isolate the contributions of role cues versus CoT cues (e.g., “Let’s think step by step”); an ablation to derive vectors from only role prompts vs only CoT phrases is needed.
- Side-effect auditing: The impact of SRPS on non-reasoning capabilities (e.g., helpfulness, truthfulness, fluency, calibration) and task-irrelevant domains is not evaluated; potential capability regressions remain unknown.
- Safety and alignment risks: Injecting vectors in residual streams could bypass refusal mechanisms or amplify undesirable behaviors/persona biases; systematic safety, toxicity, and refusal evaluations are missing.
- Runtime and deployment overhead: The cost of extracting activations, running SAEs, and steering at inference (latency, memory, throughput) is not quantified; guidance for production deployment is lacking.
- Robustness to adversarial or noisy inputs: How SRPS behaves under mis-specified roles, adversarial prompts, typos, formatting noise, or long-context settings is untested.
- Multi-role composition: Combining multiple roles (e.g., “teacher + scientist”) and resolving conflicts between their steering vectors is not explored.
- Automatic role discovery: The approach depends on curated role prompts; methods to discover or learn role vectors unsupervisedly (from corpora or behaviors) are not investigated.
- Token filtering assumptions: Averaging activations excludes stop words/punctuation/BOS; the sensitivity of SRPS to this choice and whether it discards useful signal is not analyzed.
- Output-quality metrics: Beyond accuracy, the paper does not assess reasoning-path quality (faithfulness, completeness, error typology), verbosity, or adherence to role-specific style criteria.
- Generalization across CoT regimes: While zero-/one-/few-shot CoT are tested, the reasons for observed gains/losses (e.g., when prompting degrades performance) are not dissected; guidance for selecting regimes is missing.
- Quantization/compression compatibility: The interaction of steering with quantized models, speculative decoding, or memory-saving techniques is unknown.
- Reproducibility details: Precise injection layer(s), λ, θ, β, and selection protocols for each model/task are not fully specified for replicability; code and configurations for automatic feature ranking are needed.
Collections
Sign up for free to add this paper to one or more collections.