- The paper introduces activation steering by computing steering vectors from contrastive prompt pairs to link informal reasoning with formal proof steps.
- It demonstrates a significant performance boost, with a 66.4% pass rate on miniF2F compared to 48.2% for the base model, using computationally efficient forward passes.
- The method offers enhanced mechanistic interpretability and a parameter-free alternative to resource-intensive fine-tuning techniques.
Motivation and Context
The challenge of formalizing and verifying mathematical proofs—particularly those stated in informal language—remains substantial within automated theorem proving (ATP). Transformer-based LLMs offer substantial promise in automating proof search and synthesis, but the practical gap between informal problem statements and formal proof steps restricts their utility. Prior approaches predominantly relied on supervised fine-tuning or augmentation with natural language reasoning, leaving open questions regarding the internal representations of informal cues and their influence on proof construction.
This paper ("Steering LLMs for Formal Theorem Proving" (2502.15507)) introduces an inference-time intervention—activation steering—for guiding proof synthesis in LLMs, providing mechanistic interpretability by linking informal context to internal activations. The method leverages linear representations in the model's residual stream to steer reasoning, avoiding costly weight fine-tuning and enhancing performance on key theorem proving benchmarks.
Methodology: Steering via Activation Space
The central contribution is the construction and application of steering vectors—directional perturbations in activation space—derived from contrastive prompt pairs. Each pair consists of a formal proof step with and without explicit natural-language reasoning. These are processed through the model, extracting per-layer residual activations.
Steering vectors are defined as the difference-of-means between the activations induced by the natural-language-augmented and the purely formal prompts, isolating a direction correlated with informal reasoning.
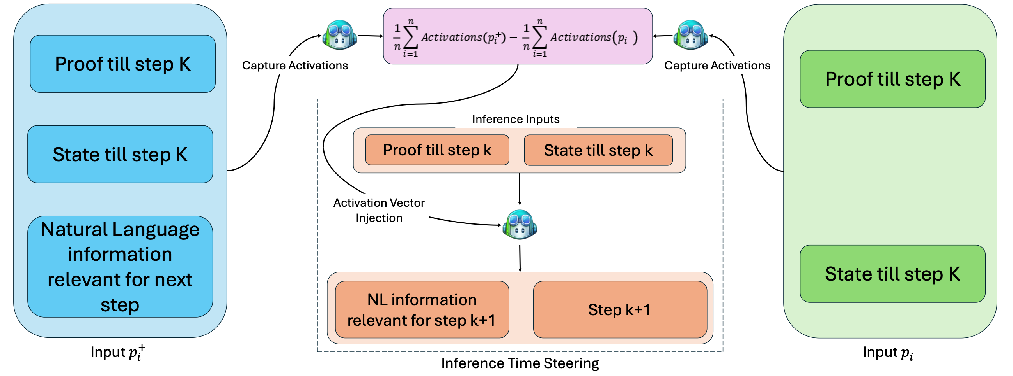
Figure 1: Steering Vectors are computed as difference of means for p+ (with NL context) and p (formal-only), yielding a direction in the activation space strongly associated with reasoning.
An activation similarity analysis identifies optimal intervention layers—typically deep transformer layers where representations induced by informal reasoning diverge maximally, exhibiting valleys in cosine similarity. At inference, steering vectors are injected at selected layers with a tunable scaling parameter α, nudging model activations toward the "informal reasoning" direction while maintaining semantic stability in unrelated aspects.
The approach requires only forward passes for vector construction, yielding computational efficiency advantages over parameter adaptation techniques (e.g., LoRA fine-tuning).
Experimental Evaluation
Steering was evaluated across multiple theorem-proving LLMs (Llemma-7B, InternLM2-7B, InternLM2.5-StepProver), with steering vectors constructed from Lean-STaR contrastive pairs. Benchmarks include miniF2F and PutnamBench, focusing on Olympiad-level mathematical reasoning spanning algebra, geometry, and combinatorics.
Decoding strategies comprised best-first search and parallel sampling to mitigate variance and probe robustness to reasoning shifts induced by activation steering.
Strong empirical results are demonstrated:
- InternLM2.5-StepProver with steering achieves 66.4% pass rate on miniF2F under sampling decoding, compared to 48.2% for the base model.
- Steering yields consistent improvements across all search budgets, with relative gains growing at higher expansion budgets.
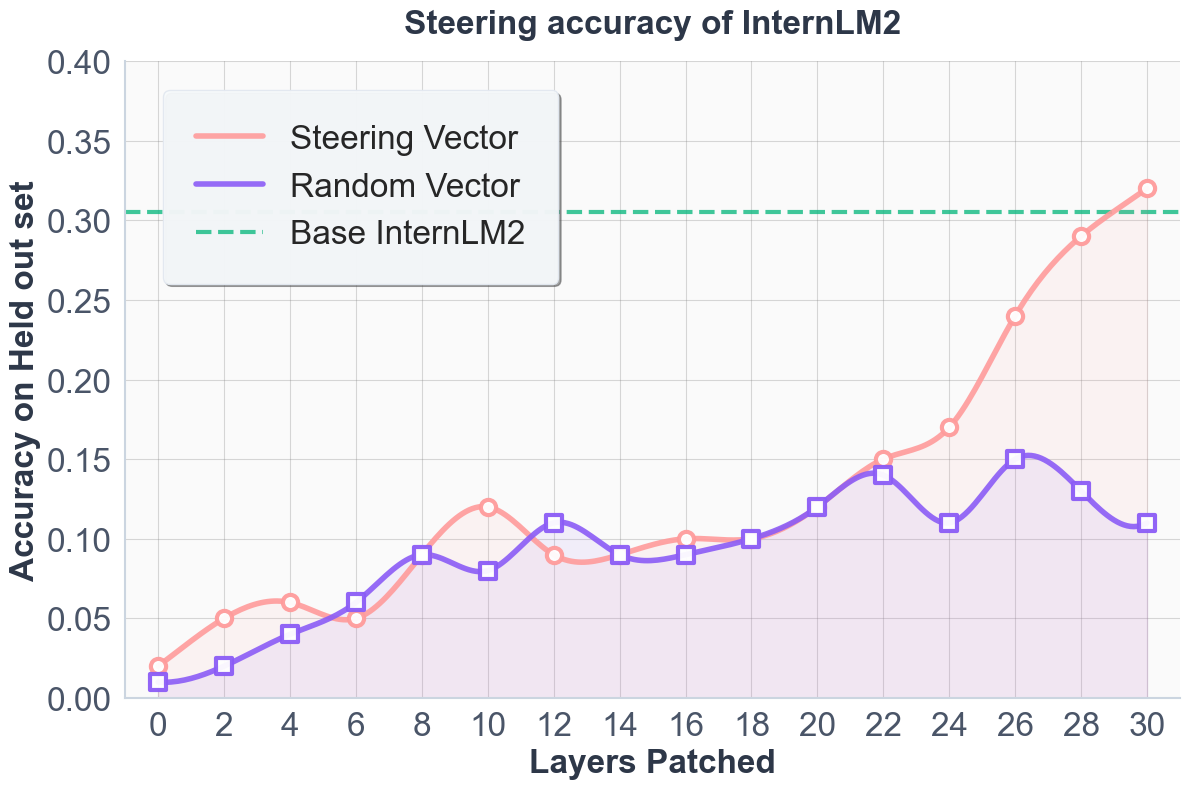
Figure 2: Pass rates at 2×32×600 for InternLM2.5-StepProver on miniF2F, showing marked improvement from layer-wise steering.
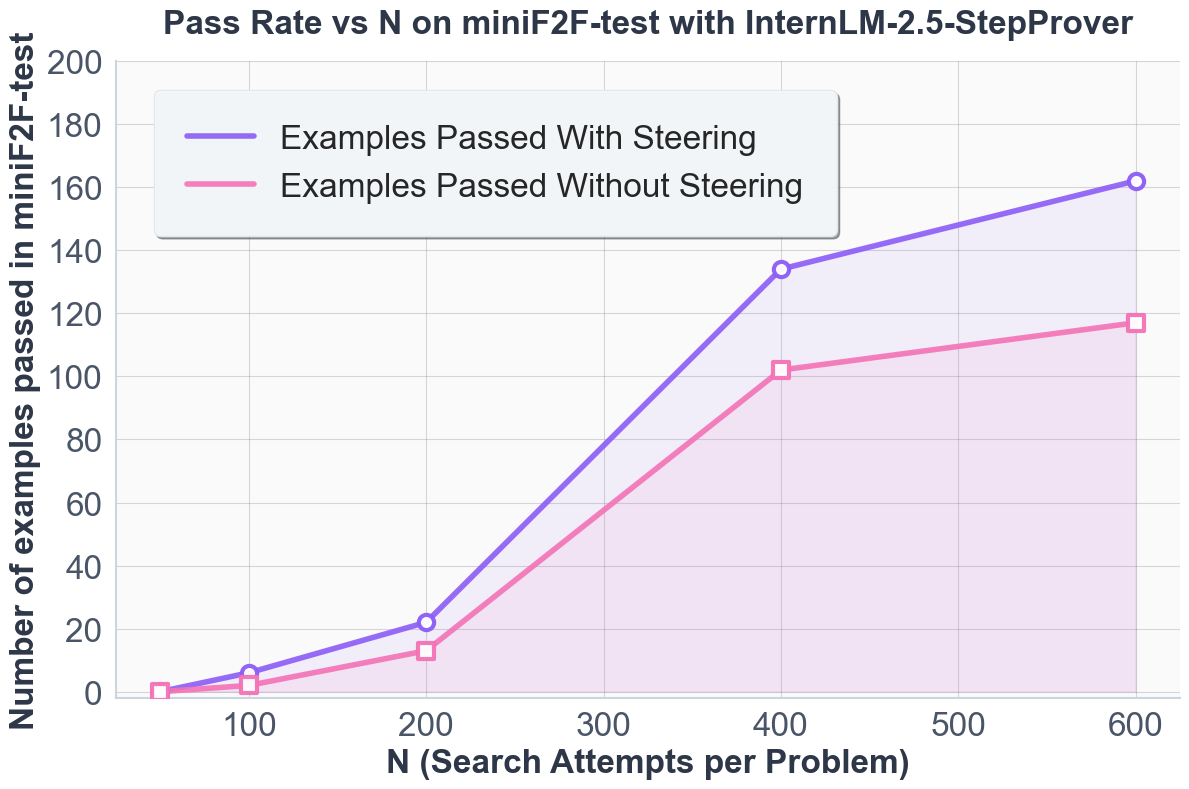
Figure 3: Pass rates on miniF2F as a function of search budget, confirming robustness and scalability of steering-induced gains.
Layer sensitivity experiments confirm that steering later transformer layers produces maximal performance improvements—consistent with the hypothesis that deep layers encode high-level reasoning circuits responsive to informal guidance.
Comparison to Parameter-Efficient Adaptation
The activation steering method was directly compared to LoRA fine-tuning with InternLM2. LoRA with high rank can surpass steering in absolute terms but requires extensive training resources. Steering achieves competitive results immediately, with no change to model parameters, highlighting its parameter efficiency.
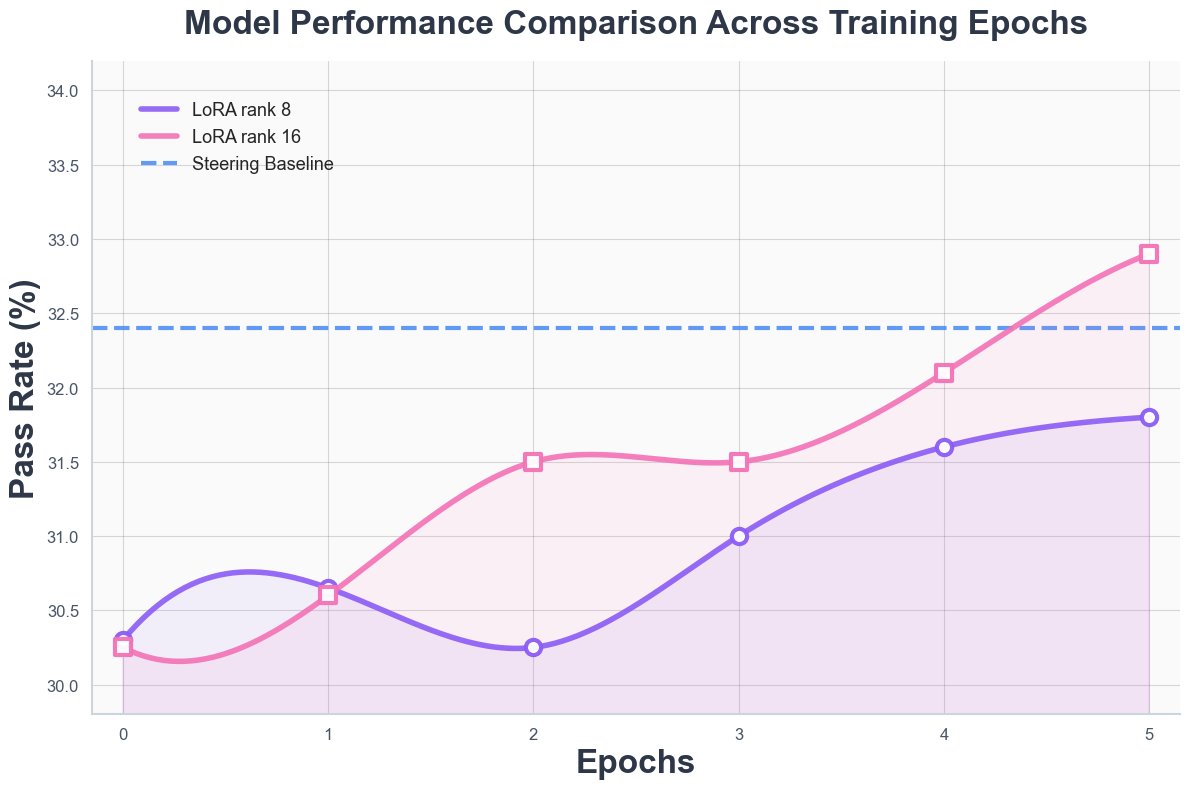
Figure 4: Comparison between steering and LoRA fine-tuning, illustrating the trade-offs between resource requirements and performance.
Problem Coverage: Steering-Induced Diversity
Steering vectors expand the set of solved problems, enabling the model to discover new proofs previously inaccessible.
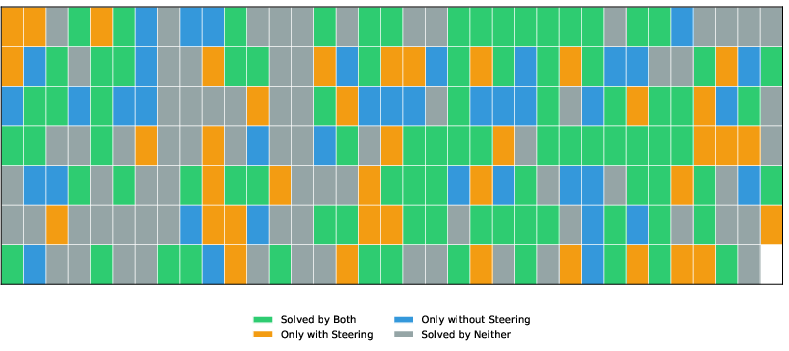
Figure 5: Comparison between problems solved with and without steering, illustrating a substantial increase in coverage and diversity.
The expansion is accompanied by an increase in failure cases—analyzed as arising from inductive biases encoded in the steering vector which may align poorly with some theorem classes. Characterizing these biases is crucial for extending steering to broader proof distributions.
Qualitative Analysis and Mechanistic Interpretability
Activation steering improves the model's proof-writing discipline by injecting high-level natural language reasoning steps, grounding tactic selection and facilitating canonical algebraic manipulations. Detailed proof diffs reveal that steering encourages use of idiomatic tactics (e.g., mul_eq_zero) and logical continuity matching mathematical practice, especially in case analysis and constraint propagation.
Curiously, steering sometimes yields correct proof steps even when the injected natural-language reasoning is partially incorrect, suggesting a nontrivial interaction between reasoning direction and generation confidence. This observation invites further inquiry into the relationship between instruction quality and proof validity.
Transferability experiments reveal that steering vectors may encapsulate reasoning patterns generalizable across formal systems (e.g., Lean to Coq), underscoring their capacity to encode system-independent mathematical strategies.
Implications and Future Directions
Practically, activation steering enables parameter-free performance improvements in formal theorem proving, lowering computational and engineering barriers to upgrading reasoning capabilities in LLMs. The approach is immediately compatible with existing LLM architectures, requiring only residual stream access and prompt construction.
Theoretically, the results strengthen the evidence for linear representation of high-level features in activation space, offering a principled lens into mechanistic interpretability. Steering vectors can serve as tractable proxies for tracing the passage from informal thoughts to formal steps within the model, opening avenues in controllable reasoning, implicit evaluation, and universality in mathematical feature encoding.
Future directions include formalizing and controlling the inductive biases embedded in steering vectors, optimizing vector construction for transferability across languages and proof systems, and extending the method to multi-property and multi-behavior steering.
Conclusion
Activation steering in LLMs, as instantiated for formal theorem proving, realizes consistent and substantial improvements in proof synthesis by harnessing semantically meaningful directions in activation space. The method decouples performance enhancement from parameter updates, provides mechanistic interpretability, and exhibits robust generalization and transferability properties. The findings underscore the sufficiency of activation interventions for guiding complex reasoning tasks and offer a promising framework for enhancing competitive mathematical problem solving in neural models.