- The paper introduces a mathematical framework linking cosine similarity to the intrinsic geometry of LLM features.
- It validates the multidimensional linear representation hypothesis through empirical tests on text embeddings and token activations.
- The findings offer practical insights for enhancing model interpretability, safety, and feature extraction methods.
The Origins of Representation Manifolds in LLMs
Introduction
The study of representation manifolds within LLMs is a critical aspect of mechanistic interpretability, focusing on the transformation and mapping of complex embeddings into comprehensible concepts. This investigation is anchored in the Linear Representation Hypothesis (LRH), which proposes that neural representations are sparse linear combinations of nearly orthogonal vectors. These embody various features, enabling a rudimentary understanding of AI's decision-making processes. Recent discourse has extended this hypothesis to consider the representation of features as continuous and multidimensional, presenting them as manifolds rather than discrete points.
The primary contribution of this paper is a mathematical framework that links cosine similarity to feature geometry, providing a tool to interpret the intrinsic geometry of features. This study validates its theories through empirical evaluation on text embeddings and token activations in LLMs, illuminating the relationship between distance in representation space and semantic similarity.
Representation Manifolds as Feature Encodings
The paper postulates the multidimensional linear representation hypothesis as a generalization of LRH. Here, features are described as manifolds, reflecting not just presence or absence but continuous values. These are characterized by subspaces where features manifest as unit vectors, influenced by a non-negative scaling factor representing feature presence. The hypothesis positions manifolds as structures encoding features, connecting concepts through geodesic paths whose intrinsic geometry reflects human conceptual understanding.


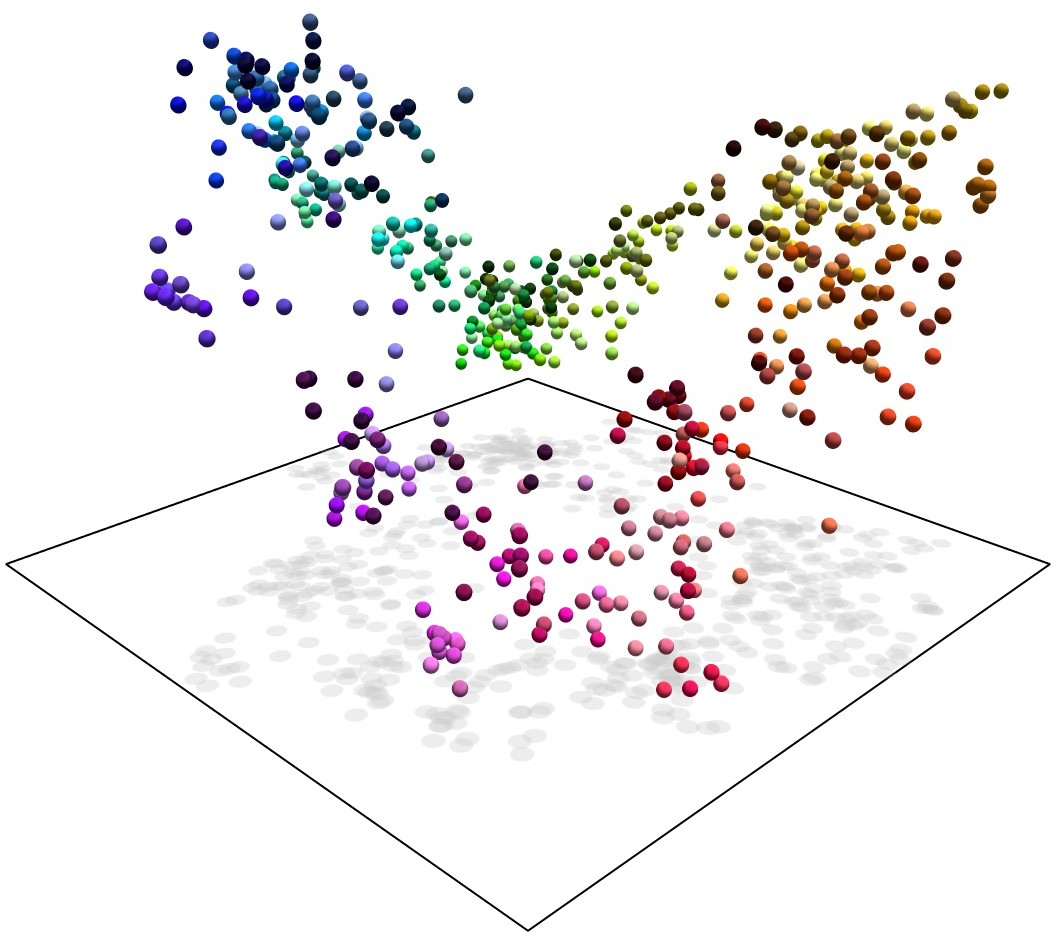
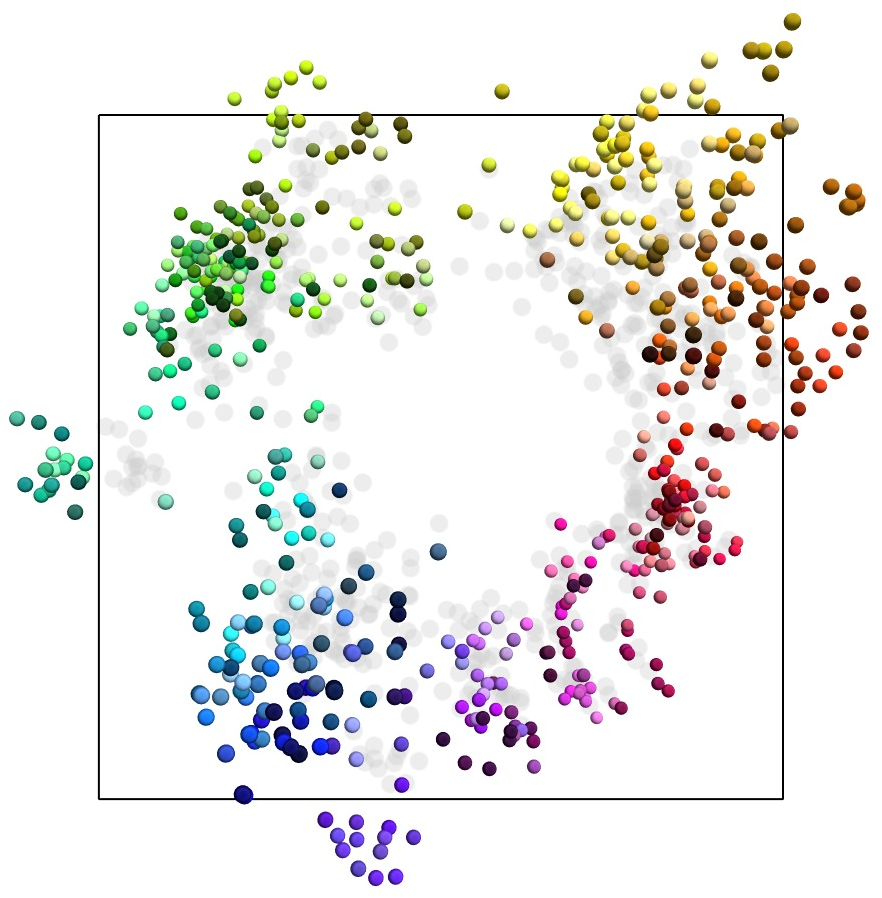

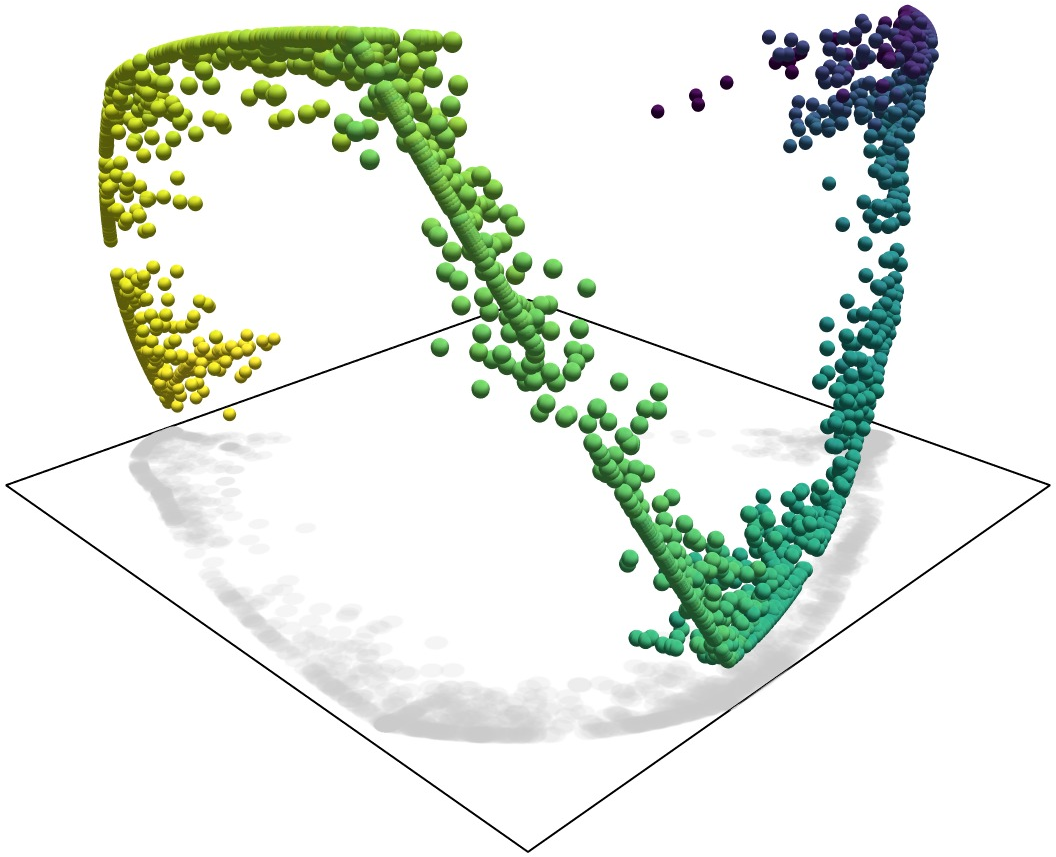
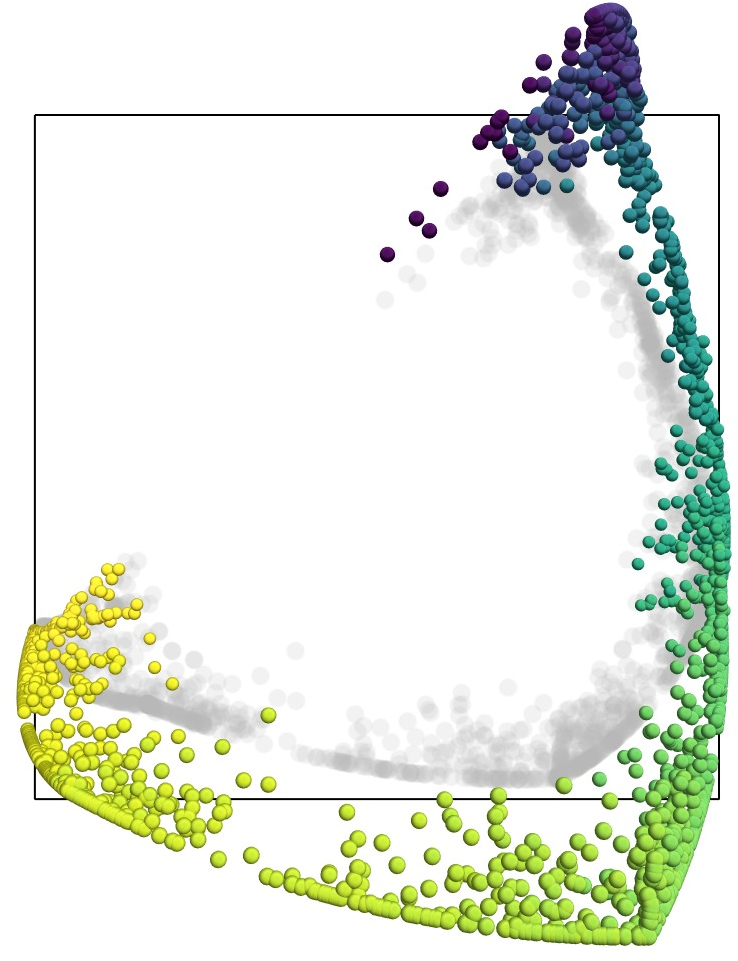

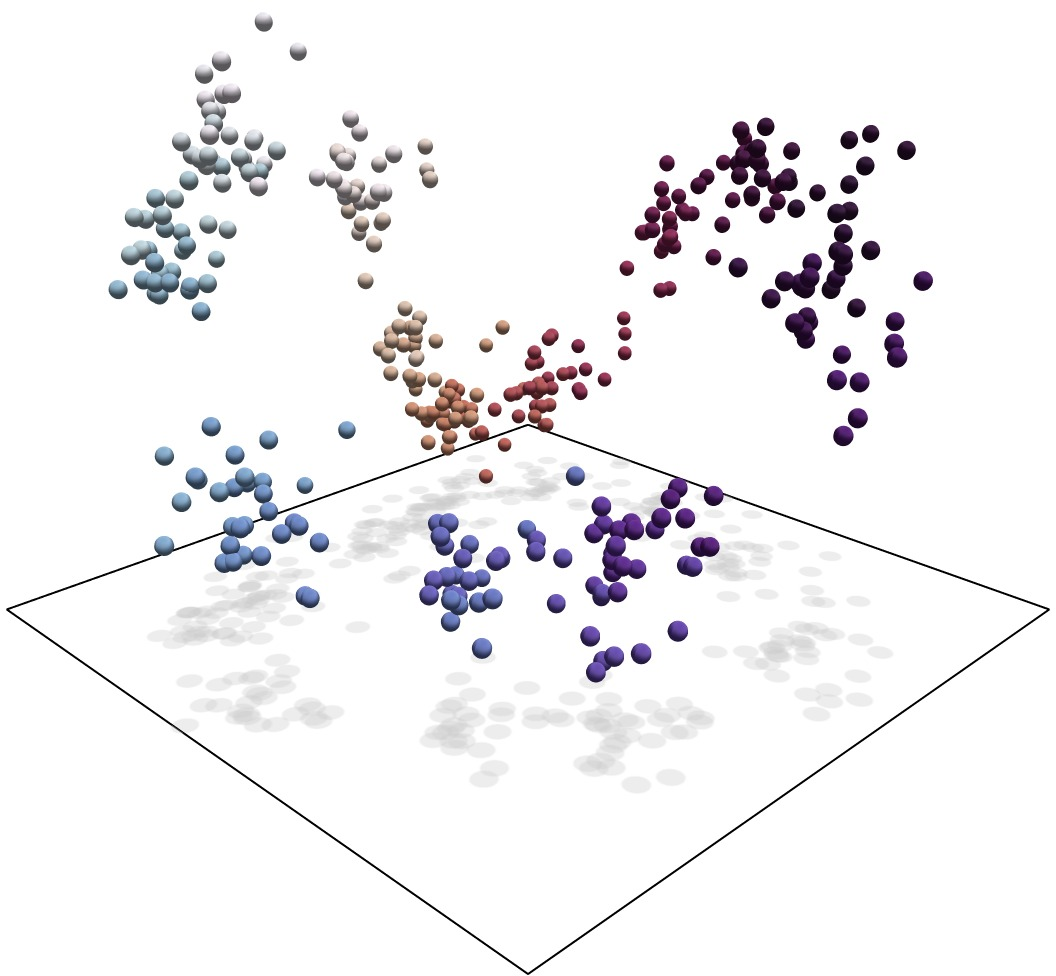
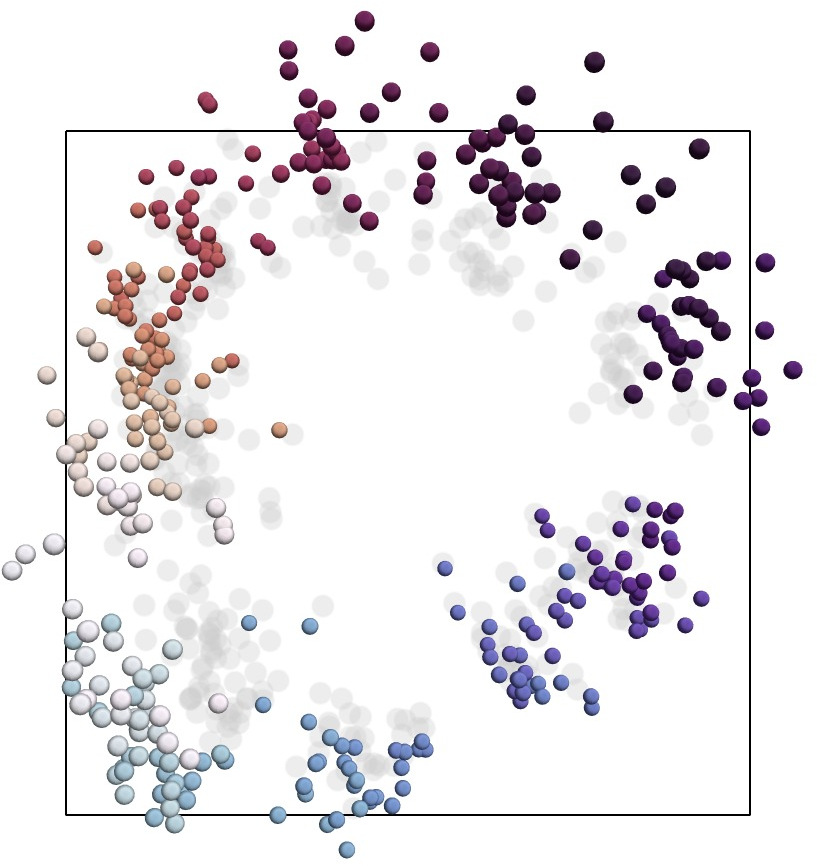
Figure 1: Representation manifolds in LLMs: colours, years and dates. The first and third example show text embeddings obtained from OpenAI's {\tt text-embedding-large-3} model from prompts relating to English names for colours and dates of the year, respectively.
Continuous Correspondence Hypothesis
Central to the paper is the Continuous Correspondence Hypothesis (CCH), which asserts a bijective mapping between the representation vectors in LLMs and the underlying feature space. This hypothesis suggests that the manifold structure in representation space mirrors the feature's geometric form, preserved through homeomorphic transformations. CCH posits that features are mapped onto a unit hypersphere, enabling a seamless translation between feature values and their model representations.



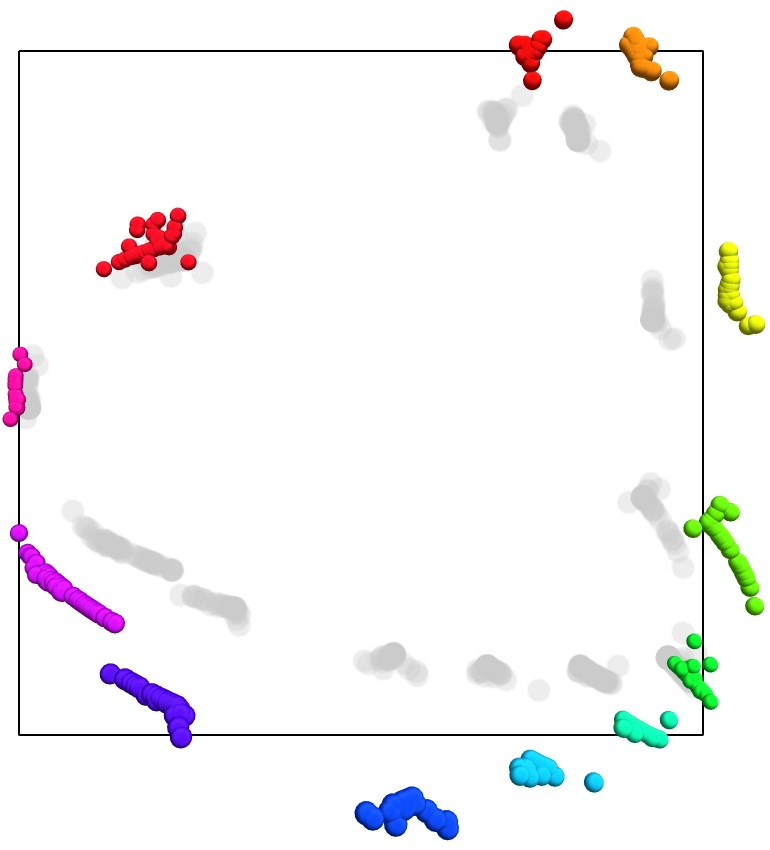


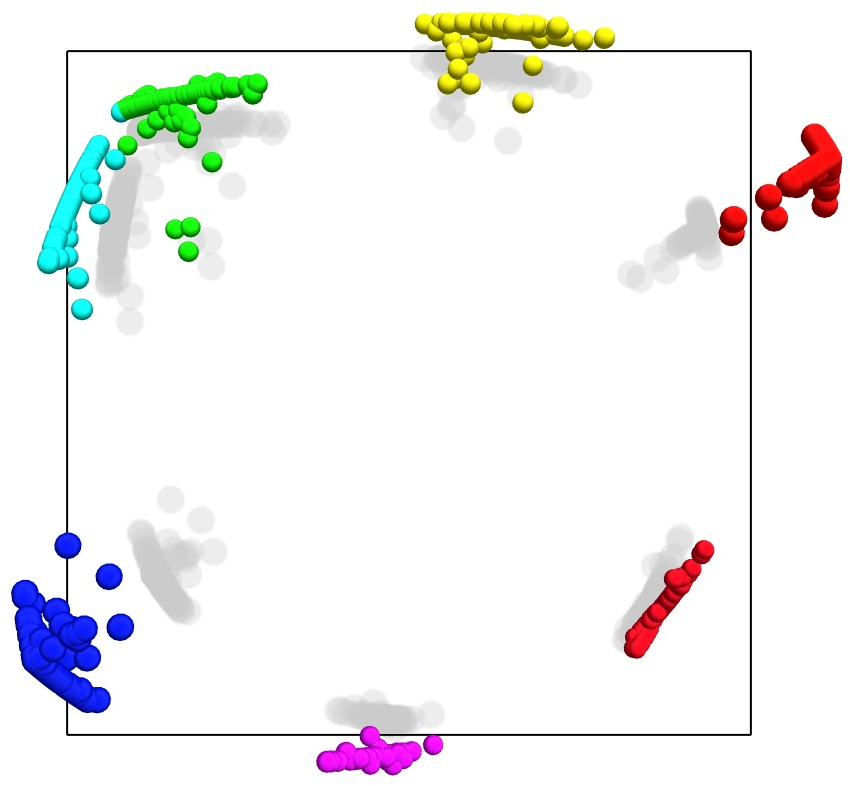
Figure 2: Representation manifolds in token activations from layer 8 of Mistral 7B, processed via an SAE to extract representations of months of the year' anddays of the week', as demonstrated in previous studies.
Geometric Properties and Cosine Similarity
The paper explores the geometric configuration of manifolds, hypothesizing that cosine similarity in representation space correlates inversely with feature distance. This connection allows cosine similarity to act as a proxy for measuring conceptual relatedness, leveraging metric space theories to elucidate feature arrangement and correspondence with human-understandable concepts.
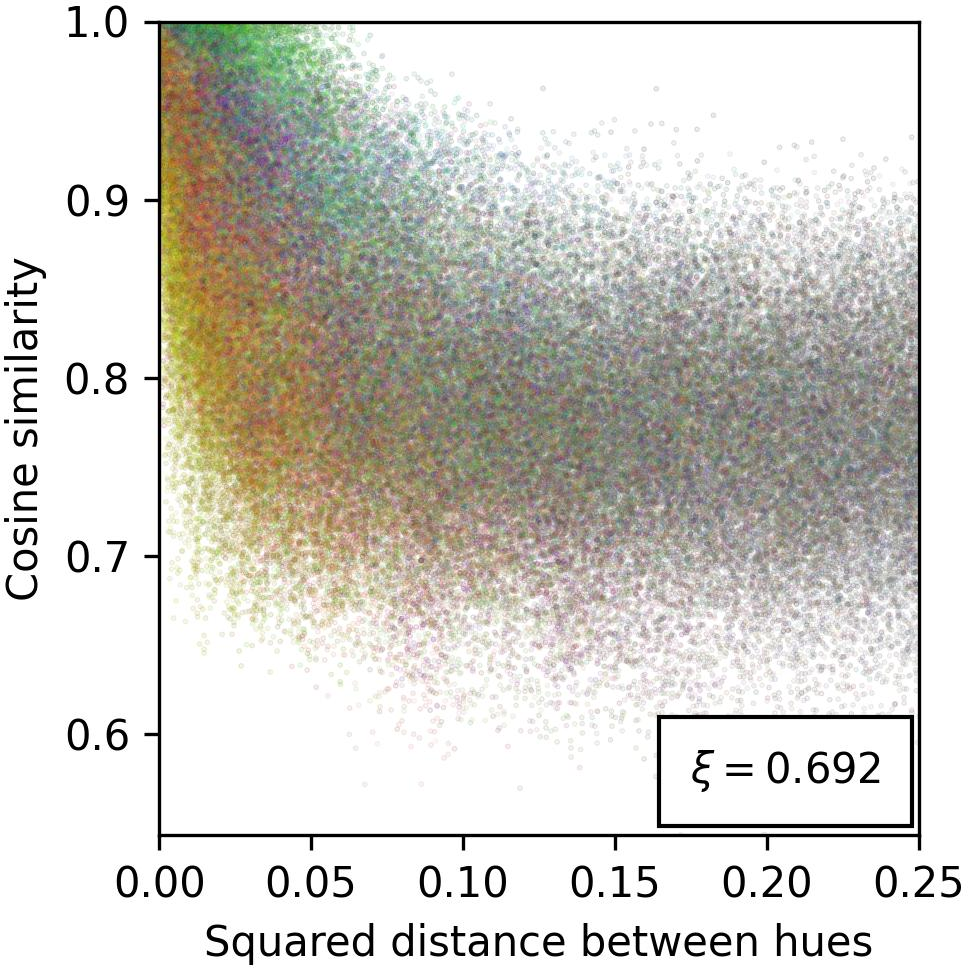
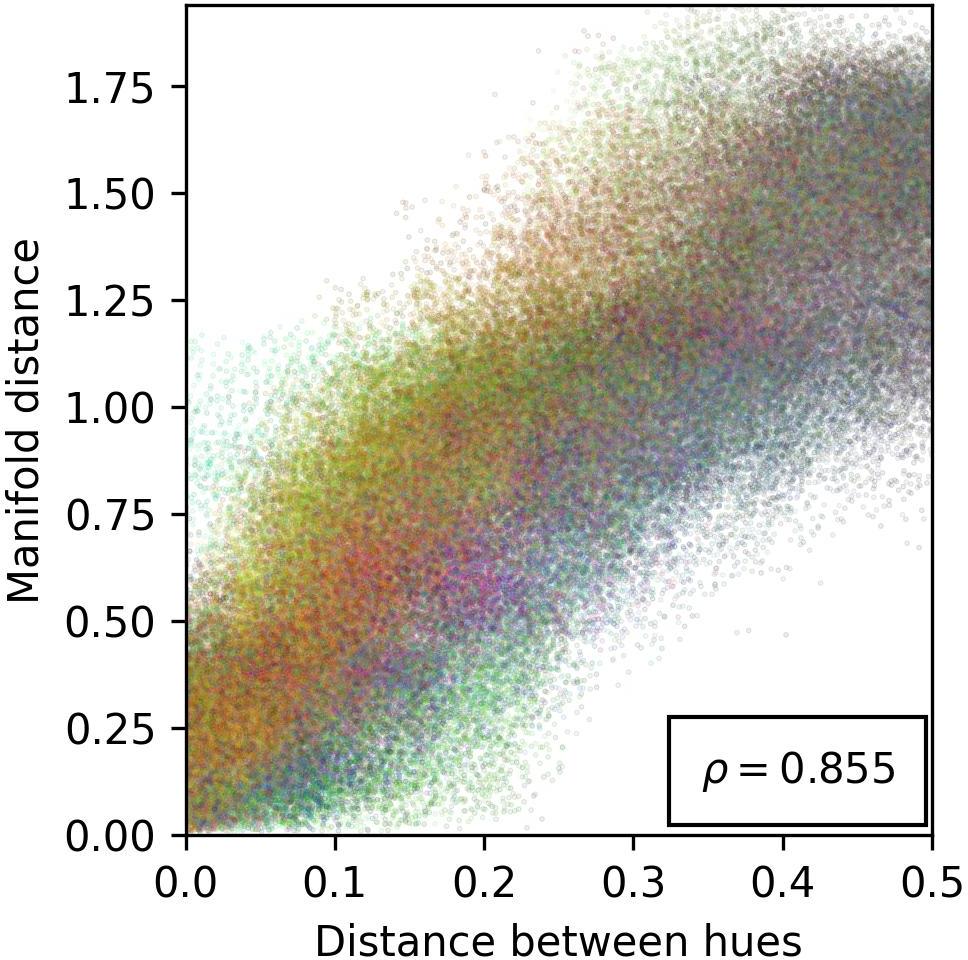
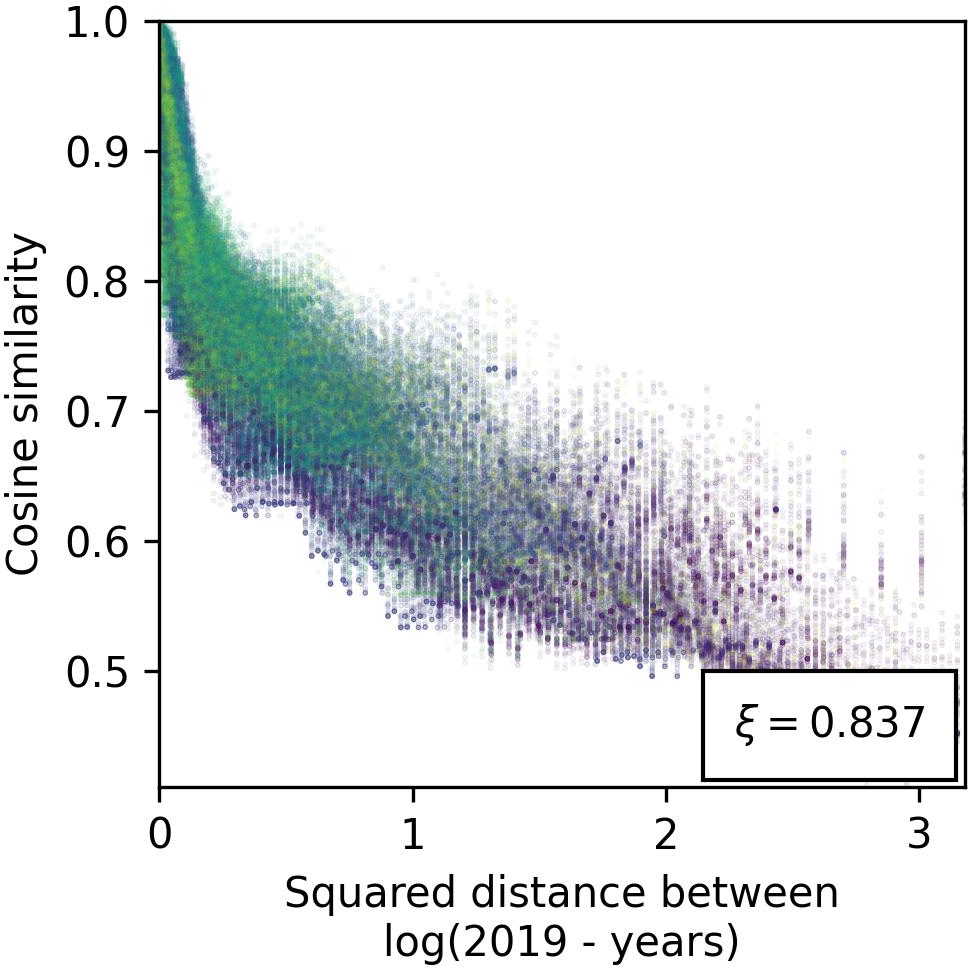
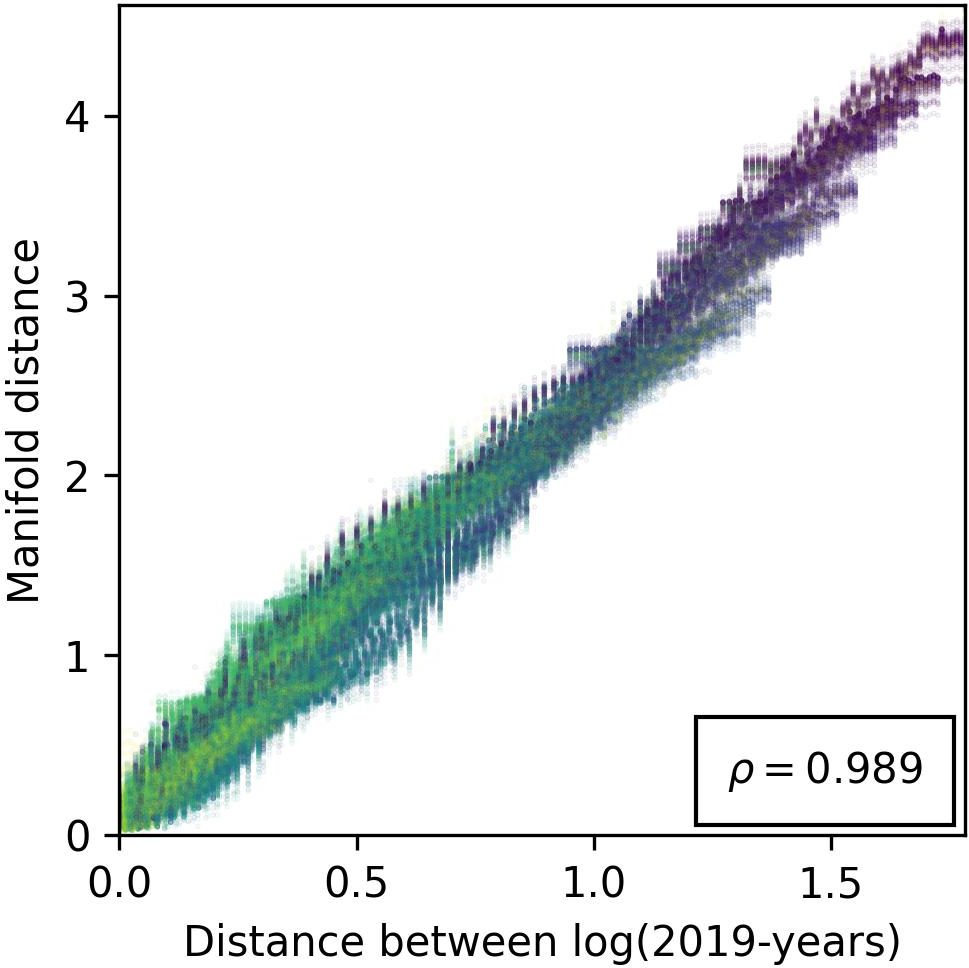
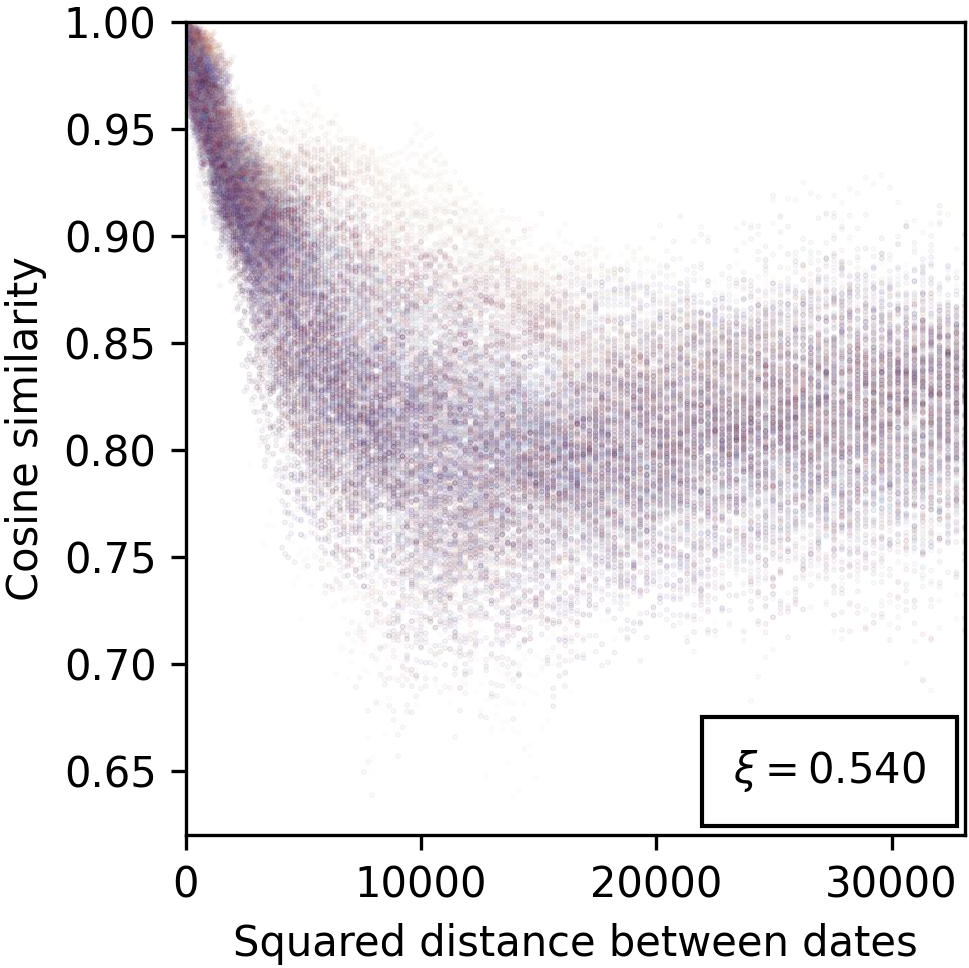
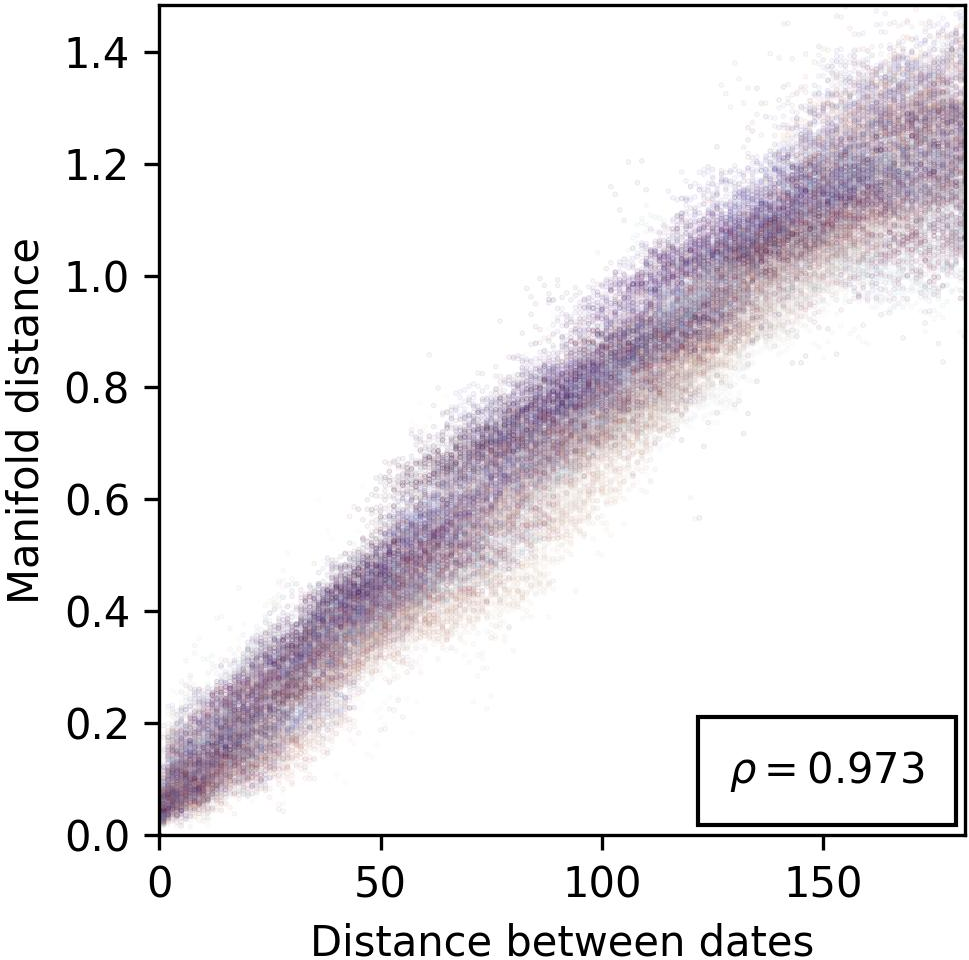
Figure 3: Evidence for the cosine similarity reflecting feature-related distances, providing insights into spatial arrangement of features within model representations.
Practical Implications and Applications
This theoretical framework paves the way for practical applications in AI safety, alignment, and enhanced interpretability. By elucidating the manifold structure of features, the paper provides a foundation for designing model interventions, refining feature extraction methodologies, and advancing sparse autoencoder models for better interpretability of complex systems.
Conclusion
The research effectively bridges the gap between abstract feature modeling and practical AI interpretability frameworks, offering a comprehensive method to decode the manifold nature of representations in LLMs. Such insights not only deepen understanding of LLM internals but also enhance their practical, safe deployment across various applications, suggesting further exploration of metric-based feature representations and their manifold geometries in complex AI systems.
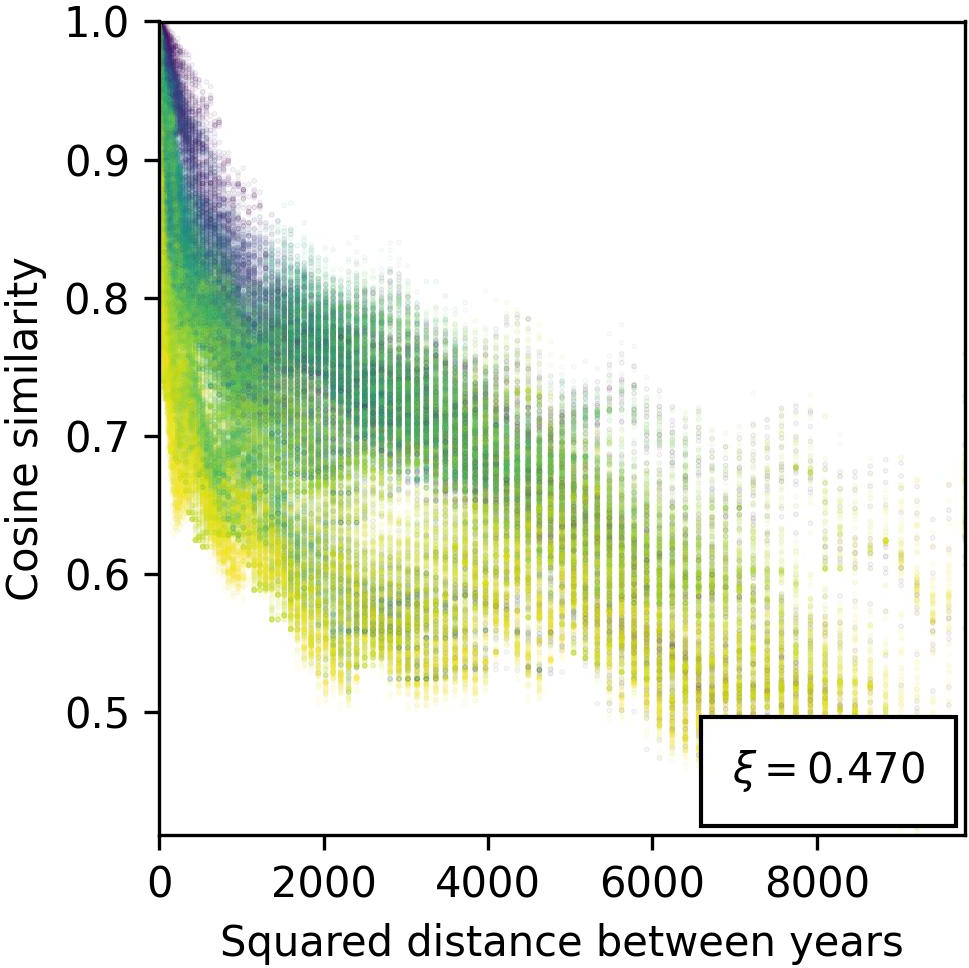
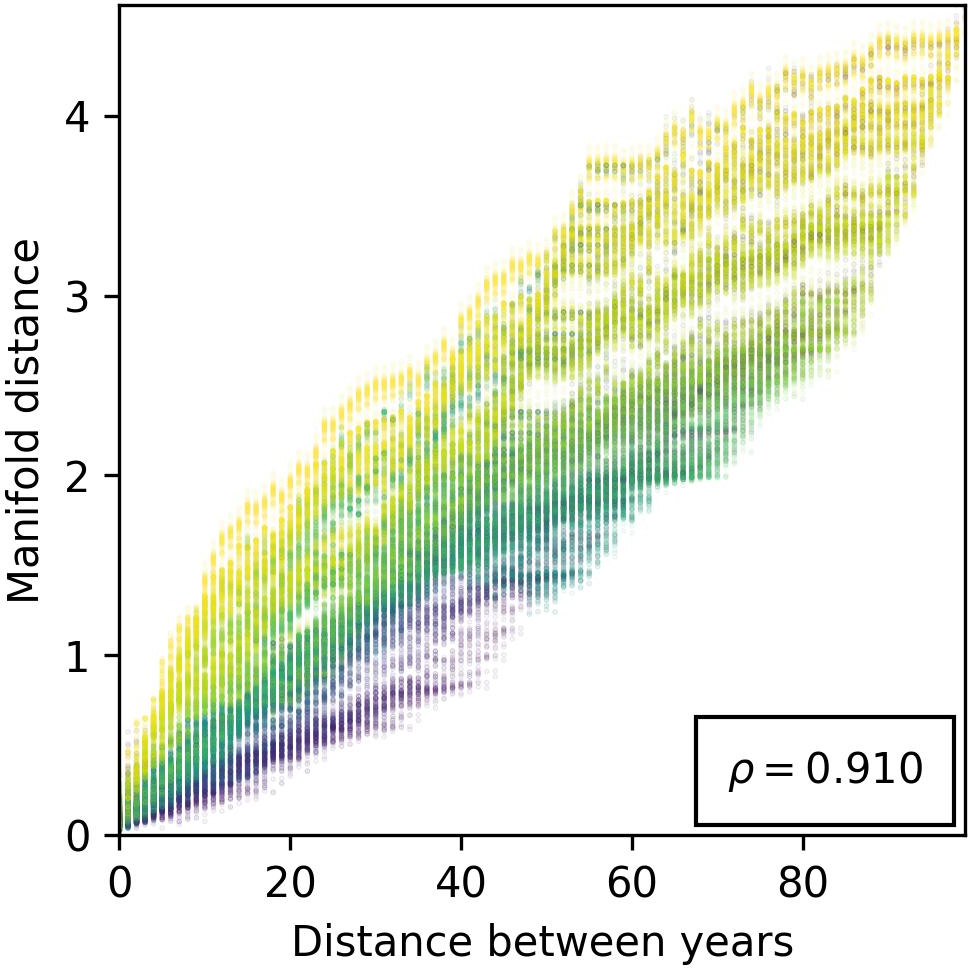
Figure 4: Evidence against isometry with respect to the metric space $\*Z_{years}$, illustrating the nuanced relationship between year encodings and their geometric representation.
Overall, this study contributes innovative perspectives on feature encoding in LLMs, fostering advancements in the development of AI systems that align closer to human reasoning and interpretable decision-making processes.