- The paper introduces a Spark Transformer that enforces activation sparsity using statistical top-k masking in both FFN and attention modules.
- It achieves up to 2.5× reduced FLOPs and significant speedups on CPUs and GPUs by reallocating parameters effectively.
- Empirical evaluations demonstrate maintained model quality with only 8% active neuron utilization, highlighting practical efficiency gains.
Introduction
The Spark Transformer architecture introduces an innovative approach to achieving activation sparsity in both feed-forward networks (FFN) and attention mechanisms of Transformers, without sacrificing model quality or increasing training complexity. Building upon the observed lazy neuron phenomenon, where the majority of neurons remain inactive for each token, Spark Transformer leverages statistical top-k sparsity to reallocate parameters and enhance computational efficiency. This paper presents improved inference speeds, achieving a significant reduction in FLOPs per token and demonstrating increased wall-time speedups on both CPUs and GPUs.
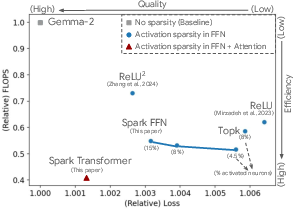
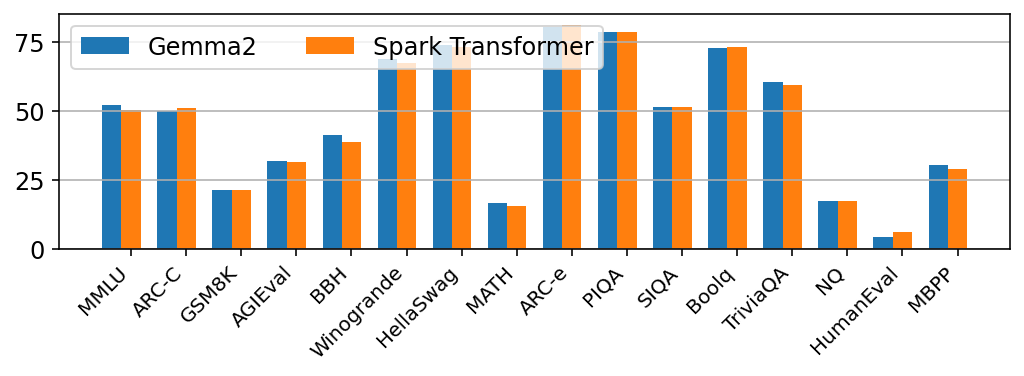
Figure 1: FLOPs per token vs. !quality (1/6 of full training)
Architectural Contributions
Spark FFN
The Spark FFN leverages top-k masking to explicitly enforce a sparse activation pattern. Instead of the ReLU-based activation, Spark FFN utilizes GELU, combined with statistical top-k, to approximate the k largest values without sorting. This approach facilitates linear-time complexity and reduces training slowdown:
Spark-FFN(;1,2,,k,r)=σ(Topk(1⊤[:r])⊙(2⊤[r:]))
Sparsity is realized by repurposing existing FFN parameters to predict active entries, minimizing quality degradation.
Spark Attention
By employing a similar paradigm, Spark Attention focuses on restricting the attention span of each token to a fixed number, effectively reducing the number of evaluations per token:
Spark-Attention(;,,k,r)=σ1(Topk(−∞)(1⊤[:r])⊙σ2(2⊤[r:]))
This reallocation reduces the computational overhead associated with large context lengths, offering accelerated training and inference times.
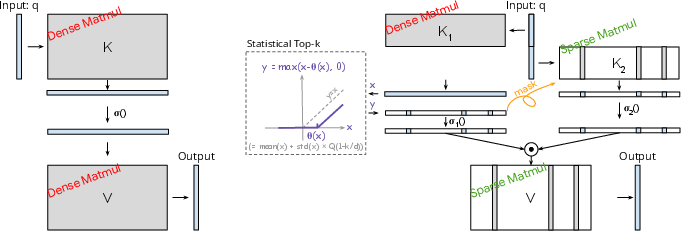
Figure 2: Architecture of Spark FFN and Spark Attention.
Technical Benefits
Statistical Top-k Operator
The statistical top-k operator is a linear-complexity algorithm that effectively combats the inefficiencies associated with traditional sorting-based methods. By estimating the threshold through Gaussian distribution fitting, the algorithm provides differentiability and computational efficiency essential for activation sparsity:
θ(,k)=mean()+std()⋅Q(1−dk)
This operator maintains activation sparsity, ensuring only essential neurons contribute to final outputs.
Empirical Evaluation
The Spark Transformer demonstrates competitive performance across standard benchmarks, showing neutrality in model quality while maintaining substantial sparsity:
- Sparsity Levels: 8\% activation in FFN neuron utilization.
- Reduced FLOPs: 2.5× reduction in computational FLOPs.
- Inference Speedups: Achieving up to 1.79× speedup on CPU and 1.40× speedup on GPU.
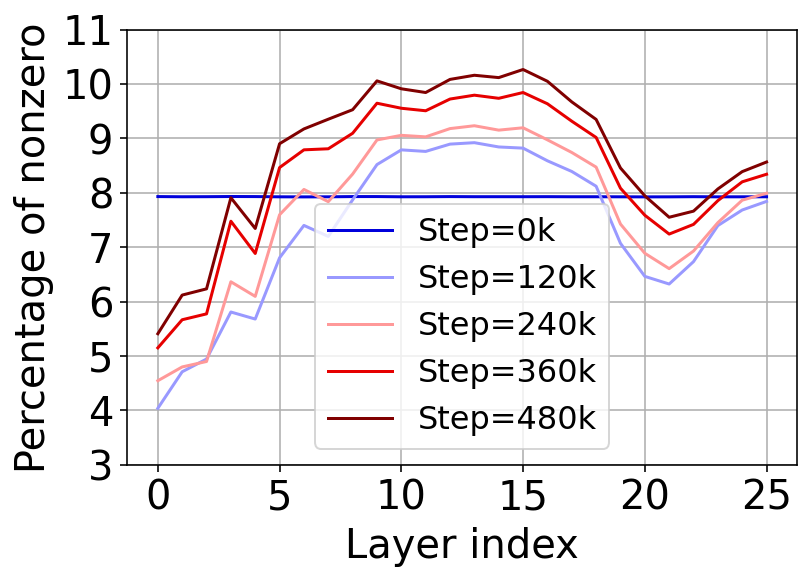
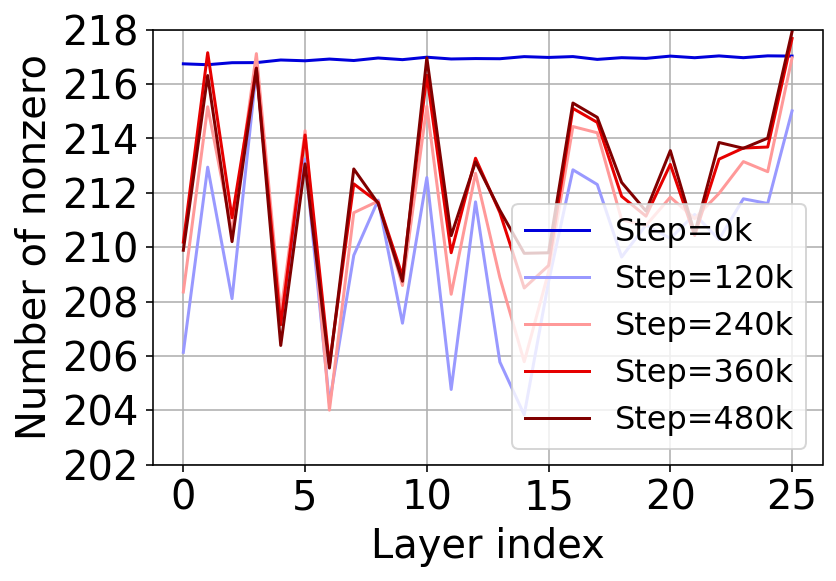
Figure 3: Sparsity level in Spark FFN.
Inference and Training Efficiency
Using customized computational approaches, the Spark Transformer facilitates speed enhancements on hardware platforms constrained by high-memory access and compute overheads:
- Sparse Matrix Operations: Optimized for CPUs and GPUs, leveraging SIMD operations and CUDA kernels to skip unnecessary computation and storage loads.
- Wall-time Improvements: Effective increase in token processing times due to reduced FLOPs and optimized memory bandwidth usage.
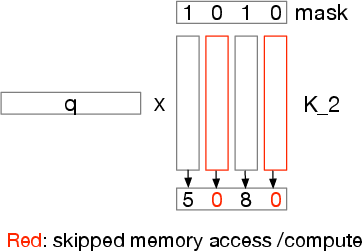
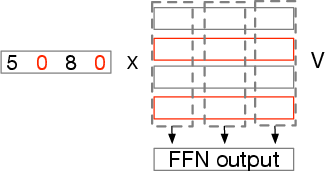
Figure 4: Vector-Masked Matrix Multiplication.
Conclusion
Spark Transformer represents a significant advancement in achieving efficient large-scale model deployment. Through its novel approach to enforcing activation sparsity, it offers both theoretical benefits and practical optimizations that promise enhanced performance across deployment environments. Future work could explore further integration of Spark mechanisms with quantization and other model optimization strategies to continue improving efficiency in state-of-the-art neural network models.