- The paper presents SOP-Bench, a benchmark featuring over 1,800 tasks across ten industrial domains to assess LLM agents on complex SOP adherence.
- It uses a synthetic data generation framework combining LLM outputs with human oversight to simulate realistic industrial workflows and complex tool interactions.
- Results reveal LLM agents achieving only 27% and 48% success rates, emphasizing critical gaps in decision-making and tool selection for SOP automation.
Summary of SOP-Bench: Complex Industrial SOPs for Evaluating LLM Agents
Introduction and Motivation
LLMs have shown proficiency in general reasoning and problem-solving, yet struggle with strictly following complex Standard Operating Procedures (SOPs) crucial for industrial automation. This paper introduces SOP-Bench, a benchmark specifically designed to evaluate LLM agents in industrial contexts where adhering to SOPs is essential. The paper's main intent is to address the lack of publicly available benchmarks that encapsulate the intricate nature and domain-specific aspects of SOPs, aiming to test the planning, reasoning, and tool use capabilities of LLM-based agents.
Synthetic Benchmarking Framework
SOP-Bench includes over 1,800 tasks spanning ten industrial domains such as healthcare, logistics, and customer service. The benchmark is built using a synthetic data generation framework that combines LLMs with human oversight to produce detailed SOPs integrated with APIs and tool interfaces. This ensures a rigorous evaluation of agents against realistic workflow tasks. The paper extensively discusses the benchmark generation process, highlighting the task context extraction and structured SOP creation to maintain realistic industry conditions. The framework is designed to introduce complexity post-generation, challenging the LLM agents in decision-making, tool selection, and error handling.
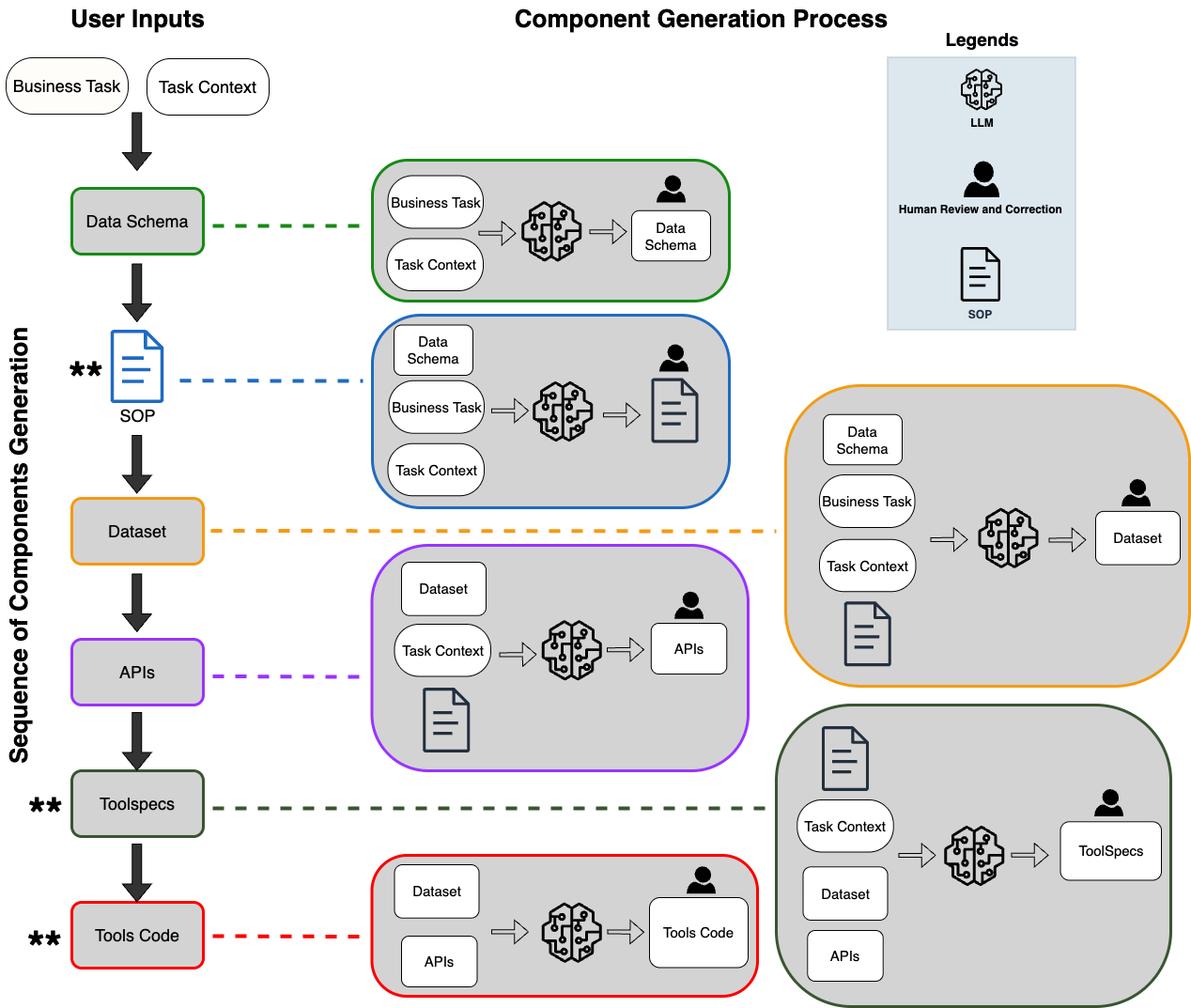
Figure 1: SOP-Bench Synthetic Benchmark Generation Workflow using LLMs and Human oversight. *
denotes post-generation complexity introduction in respective components.*
Evaluation of Agent Architectures
The benchmark evaluates two prominent agent architectures: Function-Calling Agent and ReAct Agent. Both architectures are put to test across SOP-Bench tasks. The agents exhibited average task success rates of 27% and 48%, respectively, highlighting the gap between current LLM capabilities and the demands of real-world SOP automation. Remarkably, tasks with a larger tool registry led agents to invoke incorrect tools almost 100% of the time, emphasizing the necessity for improved tool selection strategies and architectural refinement.
Results and Findings
The performance evaluation reveals significant variability across task types and domains, pointing to the importance of domain-specific benchmarking. While the ReAct Agent demonstrated superior reasoning capabilities in complex decision chains, both architectures struggled with structured workflows demanding precise tool use and compliance. The findings suggest that current LLM-based agents are not yet ready for the reliable automation of SOPs, especially in tasks requiring intricate procedural adherence.
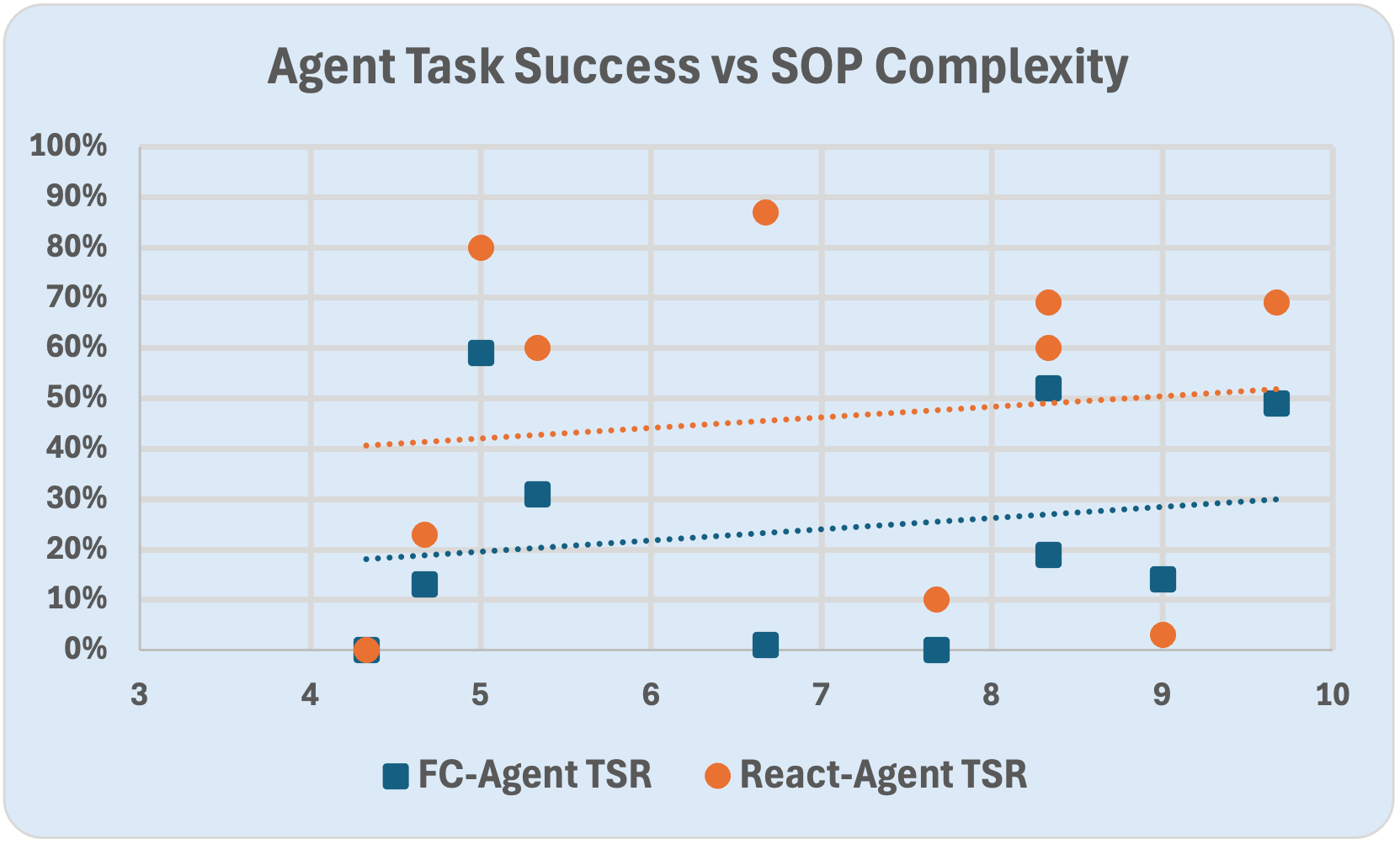
Figure 2: Shows the relationship between human perceived complexity and task success rates (TSR) of the two agents. There is very low correlation, $\rho(\text{TSR}_{\text{FC}, \mathbb{C_H}) = 0.19$, $\rho(\text{TSR}_{\text{React}, \mathbb{C_H}) = 0.12$, both p>0.10, so statistically insignificant, thus highlighting the fact that even SOPs with low human perceived complexity could be complex for LLMs.
Implications and Future Work
The implications of SOP-Bench extend to both theoretical and practical domains. The benchmark presents a standardized method for evaluating LLM agent readiness for SOP executions, inviting researchers to contribute SOPs from their domains to enrich the benchmark dataset. Future work includes exploring multi-agent systems, integrating retrieval-augmented agents, and extending benchmarks to multimodal SOPs involving images and tables. SOP-Bench encourages exhaustive testing of different agent paradigms based on pre-trained models, paving the way for safer and more reliable industrial automation using LLMs.
Conclusion
SOP-Bench provides a robust evaluation framework for assessing LLM agents in executing complex industrial SOPs, bridging the gap between current AI capabilities and real-world application demands. The benchmark aims to drive advancements in LLM architecture and tool-use efficiency, fostering community collaboration to enhance the scope and diversity of SOP-based evaluations, ultimately steering the field towards reliable SOP automation in industrial settings.