Beyond IVR: Benchmarking Customer Support LLM Agents for Business-Adherence
Abstract: Traditional customer support systems, such as Interactive Voice Response (IVR), rely on rigid scripts and lack the flexibility required for handling complex, policy-driven tasks. While LLM agents offer a promising alternative, evaluating their ability to act in accordance with business rules and real-world support workflows remains an open challenge. Existing benchmarks primarily focus on tool usage or task completion, overlooking an agent's capacity to adhere to multi-step policies, navigate task dependencies, and remain robust to unpredictable user or environment behavior. In this work, we introduce JourneyBench, a benchmark designed to assess policy-aware agents in customer support. JourneyBench leverages graph representations to generate diverse, realistic support scenarios and proposes the User Journey Coverage Score, a novel metric to measure policy adherence. We evaluate multiple state-of-the-art LLMs using two agent designs: a Static-Prompt Agent (SPA) and a Dynamic-Prompt Agent (DPA) that explicitly models policy control. Across 703 conversations in three domains, we show that DPA significantly boosts policy adherence, even allowing smaller models like GPT-4o-mini to outperform more capable ones like GPT-4o. Our findings demonstrate the importance of structured orchestration and establish JourneyBench as a critical resource to advance AI-driven customer support beyond IVR-era limitations.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
The paper is about testing AI “customer support agents” to see if they can follow business rules step by step, not just reach an answer. Think of it like checking whether a student follows every step of a math problem, not just whether they got the final number. The authors build a new test, called JourneyBench, that creates realistic customer service situations and scores how well an AI follows the required process.
The main questions the paper asks
- Can AI agents follow company policies and procedures (the “rules of the road”) during a support conversation, not just solve the customer’s problem?
- What’s a fair way to measure “did you follow the rules in the right order”?
- Does giving the AI a structured plan it must follow (like a guided flowchart) help it follow rules better than a single, long instruction?
How they did it (the approach, in everyday language)
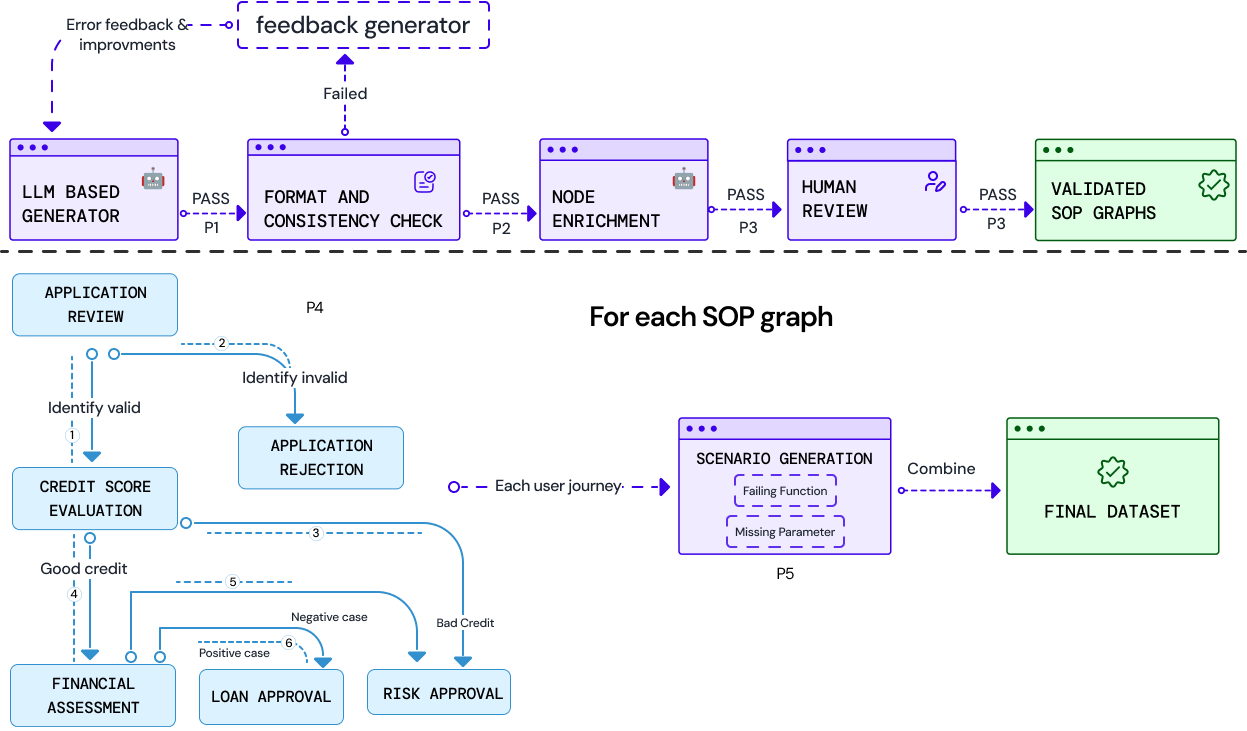
The authors built JourneyBench, a benchmark (a big, repeatable test) for customer support agents. It has four main parts:
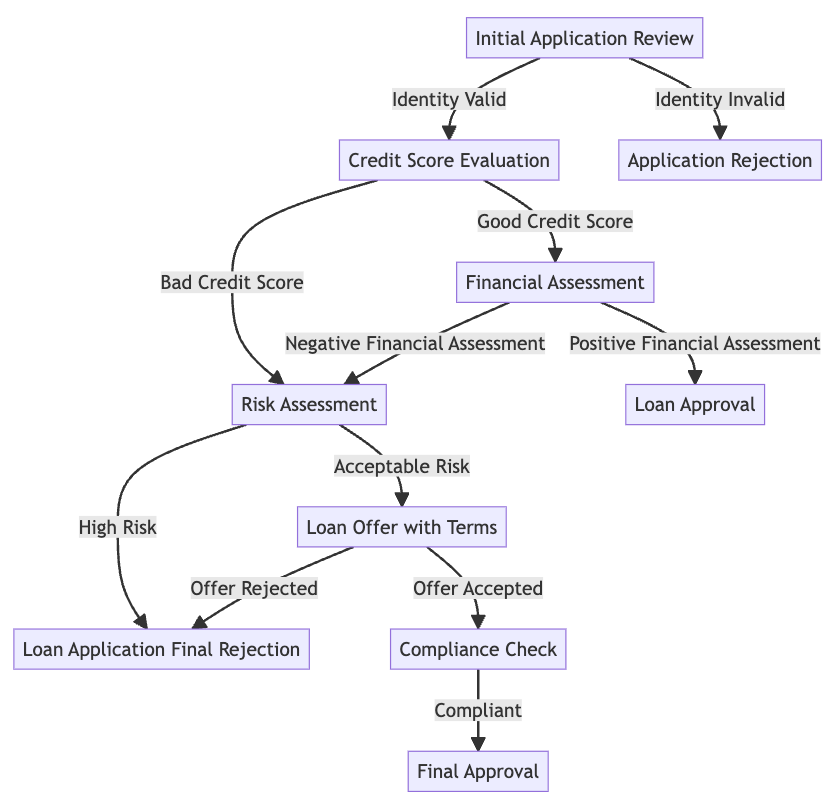
- Standard Operating Procedures as flowcharts: Each business process (like checking identity, then checking credit, then deciding on a loan) is drawn as a flowchart where arrows show the next step. This is a Directed Acyclic Graph (DAG) — basically a flowchart with no loops back.
- Nodes (steps) with tools and rules: Each step describes the task (e.g., “verify identity”), the tools the agent can use (like calling an API — think of it as pressing a button that fetches info), and the rules for moving to the next step (e.g., “if risk is low, continue; if high, stop”).
- User journeys (paths through the flowchart): These are complete, realistic paths a customer might take from start to finish (like following a recipe one step at a time).
- Scenarios (tests): For each journey, they create test conversations, including harder versions where:
- Everything works as expected,
- A required piece of info is missing,
- A tool fails (like a button returning an error).
They also introduce a score, the User Journey Coverage Score (UJCS). You can think of UJCS as a report card between 0 and 1:
- First, it checks if the AI used the exact right steps in the right order. If not, that conversation gets a 0.
- If the order is correct, it then checks if the AI filled in the right details (like correct customer ID) for each tool call.
- The final UJCS is the average of those conversation scores.
They tested two types of AI agents:
- Static-Prompt Agent (SPA): The AI gets one giant instruction that describes the whole flowchart and all tools upfront. It must remember and follow everything itself.
- Dynamic-Prompt Agent (DPA): The AI is guided one step at a time. After each step, a controller checks the tool’s result, picks the correct next step from the flowchart, and gives the AI only the info and tools it needs for that step. This reduces confusion and helps the AI stay on track.
They created 703 test conversations across three areas: telecommunications, e‑commerce, and loan applications. They used several well-known AI models (like GPT-4o and others) and simulated realistic customers. Tool responses were pre-generated so every test is fair and repeatable.
What they found and why it matters
- Structure beats size: The Dynamic-Prompt Agent (DPA), which follows the flowchart step by step, sticks to the rules much better than the Static-Prompt Agent (SPA).
- Smaller models can win with good guidance: A smaller, cheaper model with DPA (GPT‑4o‑mini) beat a larger, stronger model using SPA. This means smart design can save cost and improve safety.
- More robust under stress: When information is missing or a tool fails, SPA often goes off-track, while DPA stays steady and keeps following policy.
- Real-world use: Their DPA-style system already handles more than 6,000 calls per day in real contact centers, meeting real-time and policy needs.
Why it matters: In customer support, following rules is critical for safety, fairness, and legal compliance. An agent that reaches the “right answer” the wrong way can still cause problems (for example, approving a loan without a required risk check). JourneyBench shows how to measure and improve rule-following, not just end results.
What this research could change (the impact)
- Better, safer customer support: Companies can trust AI agents more when they can prove the agents follow every required step.
- Cheaper systems that still perform well: With structured guidance (DPA), smaller models may be good enough, reducing costs.
- A common yardstick: JourneyBench gives researchers and companies a shared way to test “policy adherence,” not just task completion.
- Future directions: The authors suggest automating the creation of these flowcharts from real conversation logs, improving the realism of tests, and watching for bias or workforce impacts as automation grows.
Overall, the big message is simple: If you want AI to be reliable in customer support, don’t just teach it what to do—guide it step by step and check it followed the rules. JourneyBench provides the map and the scorecard to make that possible.
Knowledge Gaps
Below is a single, focused list of concrete knowledge gaps, limitations, and open questions that remain unresolved in the paper. These items are intended to guide actionable future research.
- Benchmark scope is limited to three text-only domains (Telecommunications, E-commerce, Loan Application); voice-specific phenomena (ASR errors, barge-in, latency, prosody, interruptions) are not evaluated despite production claims.
- SOPs are constrained to Directed Acyclic Graphs; real workflows often require loops/rework, parallel tasks, cancellations, escalations to humans, and time-based rules—none are modeled or tested.
- Tools are treated as black boxes with pre-generated, deterministic outputs; realistic API variability (latency, schema drift, partial failures, retries, rate limits, timeouts, asynchronous events) and side effects are not captured.
- Tool failure scenarios are simplified (downstream calls removed from the expected trace); agent recovery strategies (retries, fallbacks, alternative paths, human escalation) are not measured or credited.
- The User Journey Coverage Score (UJCS) provides zero credit for any trace misalignment, conflating path adherence with parameter correctness; alternative metrics for partial credit, path-equivalence, critical step weighting, and recovery quality are not explored.
- Policy-criticality is unmodeled: skipping a high-risk step (e.g., risk assessment) is penalized identically to a minor parameter error; severity-aware scoring is absent.
- Scenario distributions are generated via BFS enumeration and synthetic seeding, not calibrated to real interaction frequencies or difficulty; no alignment with production logs or user behavior distributions.
- LLM-based user simulation shows failure modes (hallucinated inputs, premature termination) and uses GPT-4o both as user and as an evaluated agent, raising concerns about simulator–agent coupling and vendor/model-specific bias; cross-simulator robustness is not assessed.
- Conversational quality is validated by LLM-as-a-judge using a QA rubric, but human evaluations, inter-rater reliability, and correlations with business KPIs (CSAT, AHT, escalations, regulatory compliance) are not reported.
- Production deployment claims lack quantitative evidence (e.g., adherence rates, error classes, recovery success, latency, CSAT, escalation rates); methodology to bridge synthetic UJCS and live outcomes is unspecified.
- Dynamic-Prompt Agent (DPA) depends on precise SOP modeling; methods to automatically induce/maintain SOP graphs from conversation logs, tickets, and policy documents (including change detection and versioning) are not developed.
- The orchestrator assumes structured tool outputs enabling deterministic transitions; handling unstructured, noisy, or ambiguous tool responses and schema evolution remains unaddressed.
- No comparison with plan-based or hybrid approaches under latency constraints (e.g., ReAct variants, beam-re-ranked planners); quantitative latency–adherence trade-offs are not measured.
- Tool-access restriction per node in DPA may confound gains (smaller toolsets, shorter prompts); ablations isolating the effects of prompt length, toolset size, and control logic are missing.
- Memory, cross-session state, and longitudinal workflows (e.g., multi-call journeys, persistence, resumption, audit trails) are not evaluated.
- Security and safety aspects (prompt injection, tool misuse, data leakage/PII handling, redaction, adversarial users, malicious tool responses) are not part of the benchmark.
- Multilingual and accessibility considerations (non-English, code-switching, accents, disability accommodations) are absent; generalization beyond English is unknown.
- Bias analysis for synthetic workflows and conversations (domain, demographic, policy impact) is not performed beyond basic expert validation; fairness metrics are missing.
- Error taxonomy is qualitative and limited; a standardized, reproducible error typology with automated detection and root-cause attribution is not provided.
- Only four models are tested due to cost constraints; broader coverage (larger closed models, fine-tuned open-source, instruction-following vs tool-aware variants) and sensitivity to temperature/decoding are not studied.
- Fine-tuning or reinforcement learning to improve policy adherence (e.g., training on SOP graphs, reward shaping for adherence/recovery) is not explored.
- Integration with standard agent frameworks (LangGraph, CrewAI) is not empirically compared; portability and reproducibility across orchestration stacks remain open.
- Dataset, code, and SOP graph artifacts are not explicitly released; reproducibility, benchmarking standardization, and community validation are limited.
- No analysis of scalability with workflow complexity (graph size, branching factor, tool count); complexity-aware performance curves and resource/cost models are absent.
- Parameter validation lacks type/schema enforcement and correction strategies (e.g., JSON schema constraints, programmatic validators); how agents should detect and repair parameter errors is not evaluated.
- Handling off-policy user behavior (novel intents outside the SOP, scope negotiation, graceful deflection/routing) is not tested.
- No formal specification/DSL for policies; lack of verifiable semantics (pre/post-conditions, invariants) and formal adherence checking limits rigor and automated validation.
- Scenario generation sets branching values to force target paths; counterfactual testing (alternative outcomes, stochastic branching) and robustness to path deviations are not examined.
- Economic analysis is missing: cost–performance trade-offs (LLM pricing, latency, adherence, throughput) and ROI optimization with model gating or cascades are not quantified.
Glossary
- Acyclicity: The property of a graph having no cycles, used to ensure SOP graphs are valid and executable. "Outputs are validated for acyclicity and connectivity; if issues arise, an iterative LLM-based refinement resolves them"
- Conditional pathways: Branching rules attached to tasks that determine the next step based on tool outputs. "Conditional pathways encode procedural rules as logical expressions over tool outputs (e.g., riskLevel == 'acceptable'), allowing complex workflow logic to be expressed clearly."
- Contact centers: Centralized customer support operations where automated agents are deployed. "The structured DPA-based orchestration is deployed in production across client contact centers, reliably handling 6{,}000+ calls daily while meeting real-time and policy-adherence requirements."
- Directed Acyclic Graph (DAG): A directed graph with no cycles, used to represent SOP task order and constraints. "We model each SOP as a Directed Acyclic Graph (DAG), where nodes represent tasks and edges define valid transitions according to business logic."
- Dual-control environments: Evaluation settings where multiple controllers (e.g., agent and user/system) influence the interaction state. "extended this to dual-control environments."
- Dynamic-Prompt Agent (DPA): An agent that advances through a workflow one node at a time using an orchestrator and per-node prompts. "We evaluate multiple state-of-the-art LLMs using two agent designs: a Static-Prompt Agent (SPA) and a Dynamic-Prompt Agent (DPA) that explicitly models policy control."
- Hallucination in Parameter Values: A failure mode where the agent invents or substitutes parameter values not provided by the user. "Hallucination in Parameter Values:"
- LLM-as-a-judge: An evaluation approach in which an LLM grades conversations against a rubric for quality and goal attainment. "we evaluate them using the same LLM-as-a-judge rubric applied in client Quality Assurance (QA)."
- Orchestrator: A control component that manages workflow state, interprets tool responses, and advances through SOP logic. "an orchestrator—a control component that manages the workflow state and transitions, interprets the response (Appendix~\ref{app:tool_response_example}), and determines the next node by evaluating conditional pathways defined in the SOP logic."
- Policy-aware agent: An LLM agent designed to consistently follow prescribed business policies throughout an interaction. "we use the term policy-aware agent to denote an agent that consistently follows prescribed policies throughout the interaction."
- Policy control: Explicit modeling of policy constraints to govern agent behavior during workflow execution. "a Dynamic-Prompt Agent (DPA) that explicitly models policy control."
- ReAct: A planning-based approach that combines reasoning and acting, excluded here due to latency concerns. "We exclude explicit planning-based approaches such as ReAct due to their significant latency, which makes them unsuitable for real-time interactions in customer support."
- Runtime state: The evolving internal representation of the agent’s current position and data within an SOP during execution. "we developed a custom framework for the management of SOP's runtime state and facilitate the handling of conditional pathways."
- Separation of concerns: A design principle used to decouple tool implementations from workflow evaluation. "Following principles of separation of concerns from system design, JourneyBench treats tools as modular components with well-defined interfaces, decoupling their internal implementation from workflow evaluation."
- Standard Operating Procedures (SOPs): Structured workflows that encode task order, validations, exceptions, and compliance rules. "Standard Operating Procedures (SOPs) are structured workflows that prescribe execution order, validation checks, and exception handling protocols, encoding operational logic and compliance rules."
- State machine: A computational model that processes one state (task) at a time with defined transitions. "The DPA models the SOP as a state machine, processing one node at a time"
- Stateful execution: Execution that maintains and updates a persistent state across multiple steps or turns. "focus on stateful execution and world-state tracking."
- Static-Prompt-Agent (SPA): An agent that uses a single, monolithic system prompt containing the entire SOP and tools. "Static-Prompt-Agent (SPA):"
- Structured workflow orchestration: An approach that explicitly controls progression through a workflow to improve policy compliance. "structured workflow orchestration (Dynamic-Prompt-Agent) significantly outperforms prompt-based approaches (Static-Prompt-Agent)"
- Tool Call Accuracy: A metric that measures the correctness of parameter values the agent supplies to tools when the tool sequence is correct. "Tool Call Accuracy: For each simulated conversation, this metric quantifies the correctness of parameter values supplied during tool execution."
- Tool Trace Alignment: A metric that checks whether the agent’s sequence of tool calls exactly matches the SOP-prescribed sequence. "Tool Trace Alignment compares the predicted tool call sequence () with the expected sequence ()."
- User journey: A specific path through an SOP graph that represents the intended sequence of tasks and tool calls. "A user journey is a specific execution path through an SOP graph, representing the sequence of nodes and tool calls a user might follow to achieve their goal."
- User Journey Coverage Score (UJCS): An aggregate metric that averages conversation-level tool call accuracy to assess policy adherence. "JourneyBench leverages graph representations to generate diverse, realistic support scenarios and proposes the User Journey Coverage Score, a novel metric to measure policy adherence."
- User seed: A structured prompt that defines the target journey and user information for the simulated user. "Each simulation uses a user seed, a structured prompt specifying: (1) the target journey, (2) user information parameters (e.g., applicant ID), and (3) instructions for natural conversation through the tasks."
- User simulator: An LLM-driven component that plays the role of the user in evaluations. "We observed failures from the LLM-based user simulator, which do not reflect agent performance but can affect evaluation reliability."
- Workflow adherence: The degree to which an agent follows the SOP-defined action sequence rather than deviating or skipping steps. "JourneyBench evaluates workflow adherence rather than tool implementation, treating tools as black boxes with pre-generated responses."
- World-state tracking: Monitoring and updating an explicit representation of the environment or task state across interactions. "focus on stateful execution and world-state tracking."
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging JourneyBench’s SOP-as-graph representation, the Dynamic-Prompt Agent (DPA) orchestration pattern, and the User Journey Coverage Score (UJCS) metric demonstrated in production (6,000+ calls/day) and validated across 703 conversations and 41 tools.
- Policy-orchestrated customer support agents (sector: telecommunications, e-commerce, finance)
- What: Replace or augment IVR/chatbots with DPA-controlled agents that enforce SOP steps (e.g., identity verification → eligibility check → approval/denial) with node-scoped tool access and deterministic transitions.
- Where:
- Telecommunications: plan changes, SIM replacement, outage credits, device trade-ins.
- E-commerce: returns/refunds/replacements, address updates, warranty claims.
- Finance/Loan origination: KYC, credit evaluation, income/risk assessments, adverse-action notices.
- Tools/products/workflows:
- Orchestration layer that runs SOP DAGs as state machines; integrates with CRMs (Salesforce, Zendesk), CCaaS (Genesys, Five9, Amazon Connect, Twilio Flex), and STT/TTS (AWS, Azure, Google).
- Node-level prompt templates; scoped function registries; audit logging of tool traces.
- Assumptions/dependencies: Current SOPs must be accurate and versioned; stable API/tool endpoints; latency budgets compatible with LLM calls; privacy controls for PII.
- Compliance and QA measurement for agents and humans (sector: finance, healthcare, regulated support)
- What: Use UJCS and Tool Trace Alignment to quantify SOP adherence in production and QA; gate releases via CI/CD tests.
- Where: Model risk management (MRM), internal audit, contact center QA.
- Tools/products/workflows: UJCS dashboard; regression packs built from JourneyBench-like scenarios (correct context, missing parameter, failed function); weekly adherence reports and drift alerts.
- Assumptions/dependencies: Adoption of UJCS as a governance KPI; traceable tool calls; storage/retention policies.
- Cost optimization via structure-over-scale (sector: software, contact centers)
- What: Systematically downsize models (e.g., GPT-4o → GPT-4o-mini) when using DPA, maintaining adherence with measurable UJCS.
- Where: High-volume chat/voice deflection; off-hours automation.
- Tools/products/workflows: Auto-tuning that tests multiple model tiers against the same SOP scenario suite; recommendation engine for the cheapest model meeting UJCS thresholds.
- Assumptions/dependencies: Equivalent tool access across models; CI harness to catch regressions.
- IVR modernization with voice agents (sector: telecommunications, utilities, travel)
- What: Replace rigid IVR menus with DPA voice agents that adhere to SOP graphs; integrate STT/TTS.
- Tools/products/workflows: STT/TTS adapters; barge-in handling; hybrid handoff to humans with full tool trace context.
- Assumptions/dependencies: Telephony integration; robust interruption handling; background noise tolerance.
- Pre-deployment benchmarking and vendor selection (sector: enterprise procurement)
- What: Use JourneyBench-like graphs and UJCS to evaluate LLM vendors, tool-use frameworks, and orchestration libraries (LangGraph, CrewAI).
- Tools/products/workflows: “JourneyBench Runner” harness; standardized SOP packs per domain; procurement scorecards.
- Assumptions/dependencies: Comparable scenario suites; reproducible tool responses; temperature-controlled evaluation.
- Training and onboarding simulators (sector: contact centers, education)
- What: Simulate realistic journeys (including missing inputs and tool failures) to train human agents and internal bot builders on SOP compliance.
- Tools/products/workflows: LLM-as-user simulators; rubrics for conversational proficiency and goal attainment; replay of annotated tool traces.
- Assumptions/dependencies: Simulator guardrails to prevent information leakage; curated seeds reflective of real customers.
- CI/CD and observability for agent workflows (sector: software/DevOps for AI)
- What: Treat SOPs as code; enforce “no extra/missing/misordered tool calls” prior to deploy; monitor UJCS in production and alert on dips.
- Tools/products/workflows: Git-managed SOP DAGs; path enumeration tests; synthetic canaries; tool trace diffing; incident RCA based on error classes (dependency violations, parameter hallucinations).
- Assumptions/dependencies: Deterministic or recorded tool responses in test; feature flags for safe rollout.
- Audit-ready documentation and export (sector: finance, healthcare, public sector)
- What: Provide auditors with SOP graphs, expected traces, and adherence metrics as evidence of policy compliance.
- Tools/products/workflows: “Audit Trace Exporter” producing time-stamped tool calls, parameter validation, and path rationales.
- Assumptions/dependencies: Regulator acceptance of structured logs; secure storage; consent and PII minimization.
- Synthetic data generation for model fine-tuning (sector: ML engineering)
- What: Use node-scoped tools and scenario generation to produce high-quality, policy-grounded dialogues for supervised fine-tuning or RL from human feedback.
- Tools/products/workflows: Scenario generator with negative cases; parameter-perturbation to combat hallucinations.
- Assumptions/dependencies: Bias checks on synthetic data; domain expert review workflows.
- Safety-by-design scoping and guardrails (sector: security, data governance)
- What: Reduce data leakage and unsafe actions by limiting tool access per node and enforcing preconditions/decision guards.
- Tools/products/workflows: Policy enforcer middleware that validates parameters and preconditions before tool invocation.
- Assumptions/dependencies: Accurate precondition specs; comprehensive error handling paths.
Long-Term Applications
The following opportunities require further research, scaling, or standardization, but are natural extensions of the paper’s findings and methods.
- Semi-automated SOP graph induction from logs and documents (sector: process mining, BPM)
- What: Learn/derive DAGs from historical call/chat logs, CRM tickets, and SOP PDFs to reduce manual authoring.
- Tools/products/workflows: Process mining with LLM-assisted step extraction; alignment to BPMN; active learning loops with SMEs.
- Assumptions/dependencies: High-quality logs; privacy-preserving mining; human-in-the-loop validation.
- Industry standards and certification for policy-adherent AI (sector: policy/regulation, compliance)
- What: Establish UJCS-like metrics and tool-trace evidence as part of certification (e.g., NIST AI RMF mappings, ISO/IEC AI management standards).
- Tools/products/workflows: Third-party compliance labs; “Policy-Adherent AI” labels for customer service systems.
- Assumptions/dependencies: Regulator buy-in; cross-industry SOP schema standardization.
- Formal verification and safe controllers for agents (sector: safety engineering, finance/healthcare)
- What: Combine DPA with formal methods to prove no path can bypass required steps (e.g., KYC before disbursement).
- Tools/products/workflows: Symbolic execution over SOP graphs; model-checking of conditional pathways; certified runtime guards.
- Assumptions/dependencies: Formal semantics for SOP nodes; tractability for large graphs.
- Cross-channel, end-to-end process orchestration (sector: enterprise automation, RPA)
- What: Unify chat/voice/email/web flows under one policy-aware controller that also drives RPA/ETL tasks (back-office fulfillment).
- Tools/products/workflows: Connectors to BPM suites (e.g., Camunda), RPA (UiPath, Automation Anywhere), and ERPs; human-in-the-loop checkpoints as graph nodes.
- Assumptions/dependencies: Reliable handoffs; idempotent operations; unified identity and access controls.
- Domain expansion to high-stakes workflows (sector: healthcare, public sector, energy)
- What: Prior authorization, benefits enrollment, claims management; government permits; utility move-in/move-out with credit checks and deposits.
- Tools/products/workflows: HIPAA-compliant orchestration; consent capture nodes; advanced exception trees and appeals processes.
- Assumptions/dependencies: Regulatory approvals; rigorous data governance; red-teaming for edge cases.
- Marketplace and interchange for SOP graphs (sector: software ecosystem)
- What: Shareable, versioned SOP templates per industry with an open interchange format (BPMN ↔ JourneyBench DAG).
- Tools/products/workflows: SOP template hub; version diffing; impact analysis tools for policy updates.
- Assumptions/dependencies: Community governance; IP/licensing frameworks; compatibility with existing BPM tools.
- Adaptive policy learning with safe overrides (sector: advanced AI systems)
- What: Agents that propose policy refinements from observed failures while preserving hard constraints.
- Tools/products/workflows: Constraint-based reinforcement learning; “shadow” policy evaluation sandboxes; safety reviews.
- Assumptions/dependencies: Robust counterfactual testing; transparent change management; SME oversight.
- Real-time risk scoring and incentive alignment (sector: insurance, finance)
- What: Use adherence telemetry (UJCS trends, error classes) to price support risk, SLAs, and compliance insurance.
- Tools/products/workflows: Risk dashboards; SLA renegotiation triggers tied to adherence metrics.
- Assumptions/dependencies: Actuarial validation; access to longitudinal data; standardized metrics.
- Human-agent collaboration patterns embedded in SOPs (sector: workforce enablement)
- What: Explicit “human gate” nodes for discretionary decisions, with assistants pre-populating evidence packets from tool traces.
- Tools/products/workflows: Tiered escalation graphs; explainability overlays per node; coaching feedback loops.
- Assumptions/dependencies: Clear delegation policies; training for agents on reading tool traces.
- Robust simulators and perturbation testing (sector: ML evaluation)
- What: Next-generation user simulators that better match human variability; richer failure models (latency, partial data corruption).
- Tools/products/workflows: Scenario fuzzing; adversarial conversation generators; coverage metrics for edge-case paths.
- Assumptions/dependencies: Grounding against real interaction datasets; cost-efficient large-scale simulation.
- Privacy-preserving, locale-aware deployments (sector: global enterprises)
- What: Multi-lingual SOP prompts and localized policy branches; on-prem or VPC LLMs with differential privacy for sensitive data.
- Tools/products/workflows: Policy branches per jurisdiction; PII redaction nodes; regional model routing.
- Assumptions/dependencies: Local compliance mapping; robust multilingual STT/TTS; performance parity across locales.
These applications build directly on the paper’s core innovations: representing SOPs as DAGs, orchestrating agents via node-scoped dynamic prompts and a workflow controller, and quantifying adherence using UJCS and tool-trace alignment. Collectively, they enable safer, cheaper, and more reliable AI-driven customer support beyond IVR-era limitations.
Collections
Sign up for free to add this paper to one or more collections.