- The paper demonstrates a multi-teacher distillation approach that integrates language-specific teacher models to enhance SER performance.
- It employs cosine similarity metrics along with a mix of cross-entropy and KL divergence losses to align predictions.
- Experiments on English, Finnish, and French datasets show improved recall metrics, highlighting robust cross-linguistic capabilities.
Multi-Teacher Language-Aware Knowledge Distillation for Multilingual Speech Emotion Recognition
Introduction
The paper introduces a novel approach to enhancing Speech Emotion Recognition (SER) in multilingual environments through Multi-Teacher Knowledge Distillation (MTKD). This method employs multiple teacher models, each tailored for a specific language, to distill language-specific emotional information into a single multilingual student model. The integration of monolingual insights aims to improve the student model's cross-linguistic emotional recognition capabilities. SER plays a pivotal role in human-computer interaction, where understanding and interpreting emotions can significantly improve communication efficacy and empathy.
Methodology
The proposed MTKD method involves leveraging Wav2Vec2.0 foundation models as teacher models for English, Finnish, and French. The architecture of these models is designed to process raw audio inputs and produce probabilistic outputs. The methodology employs cosine similarity metrics to align the student model with the most relevant teacher model at any given instance.
The optimization process uses a blend of the cross-entropy loss and KL divergence loss to balance accurate classification with alignment to teacher model predictions. This ensures that the student model can learn both precise emotional classification and cross-linguistic emotion transfer from the teacher models.
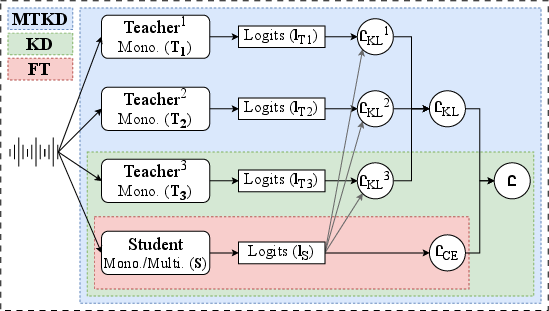
Figure 1: Proposed language-aware MTKD method.
Experimental Setup
The experimentation was conducted using datasets representing three languages: IEMOCAP for English, FESC for Finnish, and CaFE for French. These datasets are standardized for emotion recognition tasks, containing common emotional classes such as angry, happy, neutral, and sad.
The baselines compared include fine-tuning (FT) and conventional KD approaches, with experiments structured to evaluate these methods alongside the MTKD approach. Performance was measured using metrics such as Unweighted Recall (UR) and Weighted Recall (WR) to account for class distribution variability.
Results
Quantitative assessments reveal that the MTKD method surpasses conventional SER methods. Specifically, the MTKD model demonstrated superior performance in recall metrics across multilingual setups, which highlights its generalization capacity. In English SER, the model achieved a WR of 72.9, setting a new benchmark compared to prior conventional distillation methods.
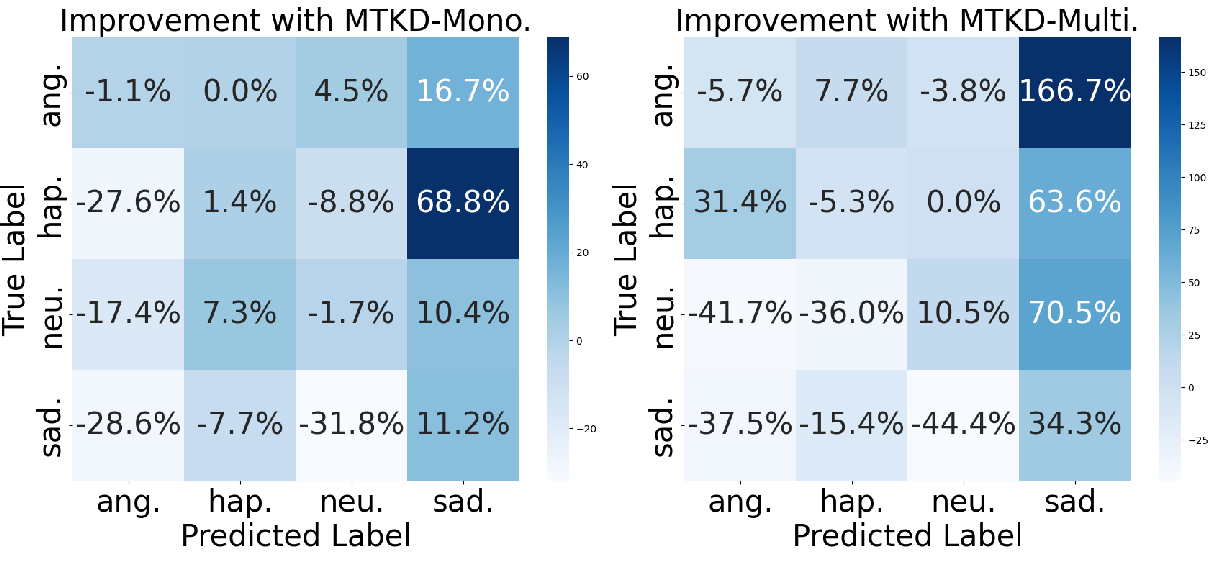
Figure 2: Performance improvement of MTKD-Mono. over FT-Mono. on monolingual set (Left) and of MTKD-Multi. over FT-Multi. on multilingual set (Right), respectively.
Qualitative Analysis
The qualitative analysis of SER performance illustrated in confusion matrices underscores the MTKD model's capability in distinguishing between complex emotion classes more effectively than fine-tuning and single-teacher distillation methods. This is particularly evident in languages where training data is extensive enough to harness cross-linguistic insights.
Error Analysis
The error analysis indicates that the MTKD model still struggles with distinguishing between emotions with lower prevalence, such as anger and happiness in certain datasets. However, it consistently improves classification rates for more prevalent emotions, suggesting an effective learning process that prioritizes linguistic adaptability.
Conclusion
The paper presents a significant advancement in SER by utilizing a multi-teacher knowledge distillation framework tailored for multilingual environments. MTKD's ability to integrate cross-linguistic emotional knowledge from monolingual teacher models has proven beneficial in enhancing the student model's performance. Despite its effectiveness, there are areas such as computational demands and teacher selection criteria that warrant further exploration. Future work may investigate heterogeneous teacher models and broader language incorporation to further expand the versatility of this SER model.
In summary, this study not only advances the pursuit of multilingual empathy in digital interactions but also contributes to the growing body of research aimed at refining SER techniques by leveraging the synergy of multiple knowledge sources.