- The paper introduces a self-distilled sparse attention gating mechanism that reduces quadratic complexity in auto-regressive reasoning.
- It employs Grouped Query Attention and a custom FlashAttention kernel to achieve near-lossless accuracy with significant speedup.
- The approach integrates seamlessly with pretrained models, offering efficient long-context decoding without requiring retraining.
SeerAttention-R: Efficient Sparse Attention for Long Reasoning in LLMs
Motivation and Context
The quadratic complexity of self-attention is a substantial bottleneck for auto-regressive decoding in reasoning-centric LLMs, particularly as generation length increases. This is exacerbated on benchmarks like AIME24 and AIME25, where strong performance is correlated with longer generations. Empirical analysis in the paper demonstrates that reasoning models naturally exhibit significant attention sparsity, and efficient exploitation of this sparsity is essential for practical deployment at scale.
Sparse attention, while widely studied for generic language modeling, has seen limited exploration in the reasoning context, especially for auto-regressive decoding. Existing training-free baselines (e.g., Quest (Tang et al., 2024)) rely on upper-bound heuristics and suffer accuracy degradation at larger block sizes. SeerAttention-R addresses these deficiencies via a training-based self-distilled attention gating methodology tailored for decoding. The design leverages Grouped Query Attention (GQA), aligns hardware efficiency via shared sparsity, and introduces substantial algorithmic and kernel-level advances for high-throughput inference.
Architecture and Distillation Mechanism
SeerAttention-R builds upon SeerAttention (Gao et al., 2024) by porting the gating mechanism to auto-regressive decoding and abolishing query pooling to enable token-by-token processing. The AttnGate module is plugged into existing attention layers without altering original model weights, distilling the sparsity choice post-training.
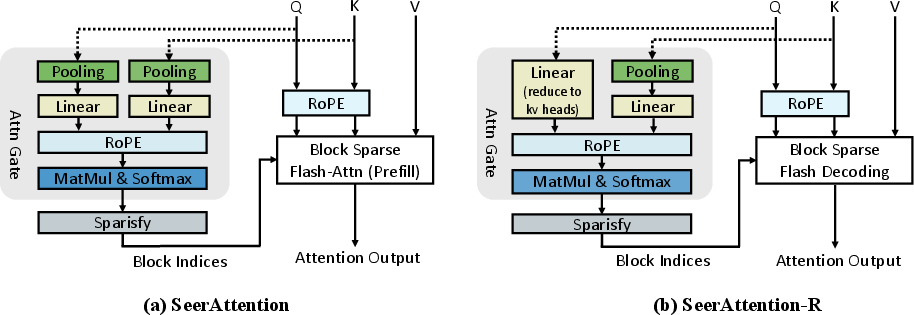
Figure 1: SeerAttention-R architecture eliminates query pooling, facilitating GQA-aligned shared sparsity selection for efficient decoding.
AttnGate aggregates query heads within each GQA group and compresses keys via a composition of Max/Min/Average pooling. RoPE positional encoding is reapplied for gated value estimation. Training uses column-wise max pooling of the pretrained model's dense attention matrix, generating ground truth for block activation—see the training flow in (Figure 2).

Figure 2: AttnGate distillation employs 1D max-pooled ground truth from dense attention, with a custom FlashAttention-2 kernel optimizing both memory and compute.
The distillation phase is remarkably lightweight, requiring only 0.4B tokens and leaving original parameters untouched. Efficient kernel modifications ensure in-place ground truth generation during training, enabling high-sequence-length batch processing without out-of-memory failures.
Inference and Efficient Execution
During inference, SeerAttention-R uses a K Compression Cache to persist compressed key representations, refreshing cache entries only when new blocks are generated. This cache constitutes less than 1% of the memory footprint of the full KV cache for block size 64. Retrieval is block-wise, enabling efficient offloading strategies and heterogeneous compute integration. The binary mask for block activation is determined either via a token budget (top-k selection) or thresholding.
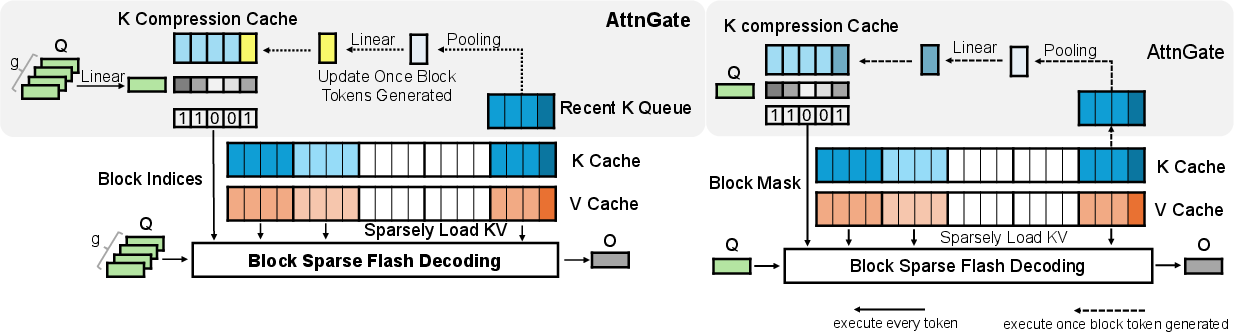
Figure 3: K Compression Cache minimizes AttnGate overhead, activating last block when cache updates lag behind sequence advancement.
A custom block sparse FlashAttention decoding kernel is implemented with TileLang and Triton. The kernel leverages GQA, assigns parallelism at batch/head/KV-shard granularity, and maximizes load balancing via block-level partitioning. TileLang's wgmma-backed kernel achieves superior speedup, especially in regimes with high sequence length and batch size.
Empirical Results and Comparative Analysis
Oracle studies on Qwen3-14B show that near-lossless performance is achievable at 2k token budget with block sizes 32/64, even for challenging reasoning tasks (Figure 4).
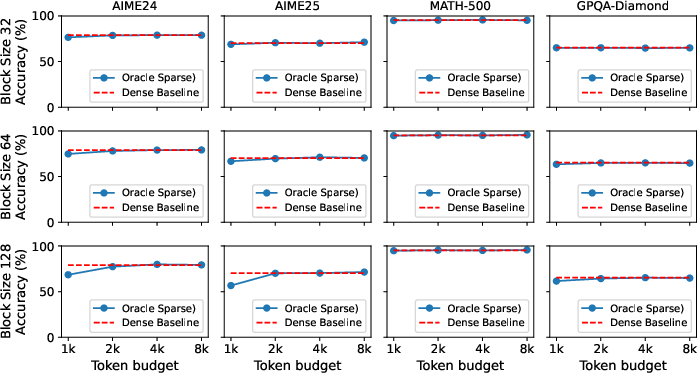
Figure 4: Oracle sparse selection on Qwen3-14B demonstrates near-lossless accuracy for block sizes up to 64 at modest token budgets.
SeerAttention-R outperforms Quest across all benchmarks and configurations, maintaining nearly lossless accuracy at 4k token budget for AIME24, AIME25, MATH-500, and GPQA-Diamond (Figure 5). Larger models exhibit increased robustness to sparsity, confirming scalability.
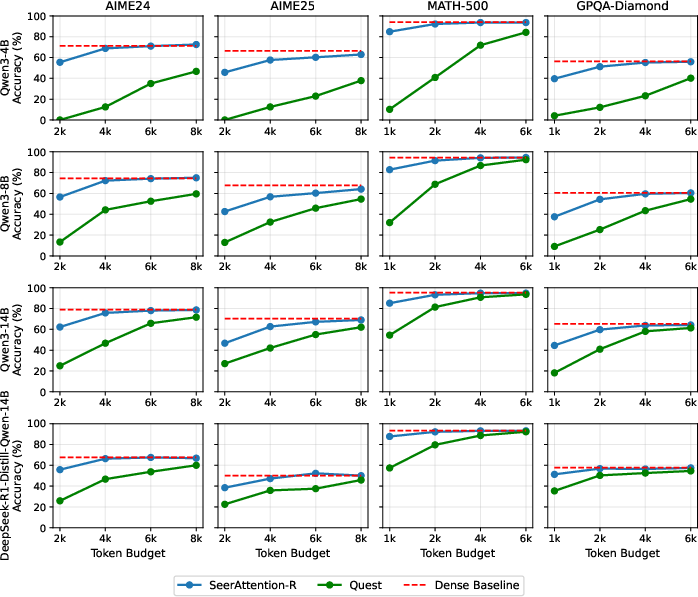
Figure 5: SeerAttention-R delivers higher accuracy than Quest, even at larger block sizes and lower token budgets.
The sparse kernel achieves up to 8.6–9x speedup over FlashAttention-3 (FA3) at high sparsity (90%) with batch size 16 and sequence length >32k, outperforming Triton (Figure 6). These gains persist across a wide operating range.
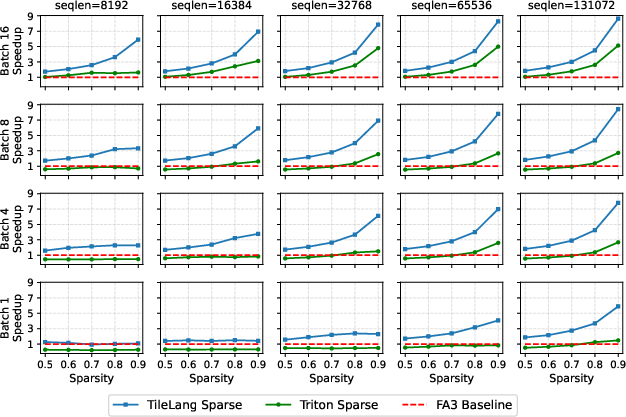
Figure 6: TileLang's block sparse decoding kernel approaches theoretical speedup bounds on H100 GPU for large batch and sequence regimes.
Ablation studies confirm SeerAttention-R's accuracy is invariant to block size, unlike Quest whose performance degrades as block size increases (Figure 7). Marginal gains are observed from introducing hybrid dense attention in early layers.
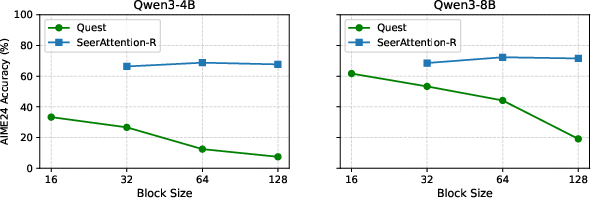
Figure 7: SeerAttention-R maintains accuracy across block sizes, whereas Quest suffers at coarse granularity.
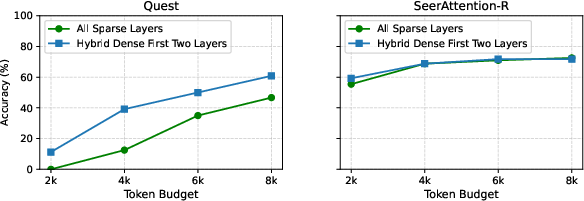
Figure 8: Hybrid dense attention provides negligible improvement for SeerAttention-R, but substantially boosts Quest accuracy.
Threshold vs. token budget strategies are compared; thresholding yields smoother token activation distributions and marginal accuracy improvement at high sparsity, but both methods are viable.
Practical and Theoretical Implications
SeerAttention-R presents a highly efficient, post-training adaptation method for sparse attention in auto-regressive reasoning models. Practical deployment benefits include:
- Plug-in Integration: No retraining or architectural modifications; seamless for existing pretrained models.
- Lightweight Distillation: Extremely low training overhead (less than 20 GPU-hours for 14B models with 32k sequence).
- Robustness to Block Size: Enables coarse-grained block activation, maximizing hardware utilization and minimizing overhead.
- Near-Theoretical Speedup: Sparse decoding kernel achieves hardware-aligned performance, facilitating large-scale inference.
- Efficient Memory Architecture: Enables KV cache offloading and block-wise retrieval, supporting long-context utilization.
Theoretical implications relate to the inherent block-level sparsity observed in reasoning, corroborated by oracle analyses. The demonstrated robustness to coarse granularity suggests that scaling and future hardware advances may further enhance the utility of sparsity-adapted mechanisms.
Speculative Directions and Limitations
Key future research directions include:
- End-to-End System Integration: Incorporation with PagedAttention frameworks (e.g., vllm, sglang, Lserve) and advanced offloading schemes.
- Adaptive Sparsity Ratio: Dynamic, task-dependent sparsity selection (e.g., Top-p methods [Twilight, MagicPIG]).
- Unified Prefill/Decode Gating: Merging sparse prefill and decode via multi-token prediction or speculative decoding for agentic workflows.
- Periodic Dense Rectification: Integration with rectified sparse attention mechanisms to prevent reasoning path escalation from accumulated errors.
Conclusion
SeerAttention-R introduces an effective, flexible, and hardware-aligned adaptation for sparse attention during long-context auto-regressive decoding in reasoning models (2506.08889). By leveraging self-distilled gating within GQA, it achieves robust accuracy at low computational budgets, is resilient to block granularity, and attains substantial kernel-level speedup. The approach is practically efficient for post-training deployment and theoretically aligned with observed sparsity properties in reasoning-centric inference.

