HySparse: A Hybrid Sparse Attention Architecture with Oracle Token Selection and KV Cache Sharing
Abstract: This work introduces Hybrid Sparse Attention (HySparse), a new architecture that interleaves each full attention layer with several sparse attention layers. While conceptually simple, HySparse strategically derives each sparse layer's token selection and KV caches directly from the preceding full attention layer. This architecture resolves two fundamental limitations of prior sparse attention methods. First, conventional approaches typically rely on additional proxies to predict token importance, introducing extra complexity and potentially suboptimal performance. In contrast, HySparse uses the full attention layer as a precise oracle to identify important tokens. Second, existing sparse attention designs often reduce computation without saving KV cache. HySparse enables sparse attention layers to reuse the full attention KV cache, thereby reducing both computation and memory. We evaluate HySparse on both 7B dense and 80B MoE models. Across all settings, HySparse consistently outperforms both full attention and hybrid SWA baselines. Notably, in the 80B MoE model with 49 total layers, only 5 layers employ full attention, yet HySparse achieves substantial performance gains while reducing KV cache storage by nearly 10x.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to make LLMs faster and use less memory when they read very long texts. The method is called HySparse. It mixes two types of “attention” layers: a few powerful layers that look at everything, and several lighter layers that only look at the most important parts. The trick is that the lighter layers reuse information from the powerful layer right before them, so they don’t have to guess what’s important or store extra memory.
What questions did the researchers ask?
They focused on two big problems with existing “sparse attention” methods:
- How do we pick which words or tokens are important without using extra guesswork that can be wrong?
- Can we save not just computing time, but also the large memory used to store attention history (called the KV cache) during long conversations?
Their goal was to design an attention system that:
- Chooses important tokens accurately without extra complicated modules.
- Cuts both computation and memory, so models can handle longer inputs more efficiently.
How did they try to solve it?
Think of reading a big textbook:
- A “full attention” layer is like carefully skimming every page to understand the whole book.
- A “sparse attention” layer is like jumping straight to bookmarked pages that matter most.
HySparse alternates them: after a careful skim (full attention), it adds several quick jumps (sparse attention). The key is where the bookmarks come from.
Quick plain-language dictionary
- Token: a small piece of text (like a word or part of a word).
- Attention: how the model decides which earlier tokens to look at when processing the current token.
- Full attention: looks at all previous tokens (accurate but slow and memory-heavy).
- Sparse attention: looks only at selected tokens (faster, but needs to choose wisely).
- KV cache: a memory of past “keys” and “values” the model uses to avoid re-reading everything every time.
- Sliding Window Attention (SWA): always looks at just the most recent chunk of text, like a small “nearby window.”
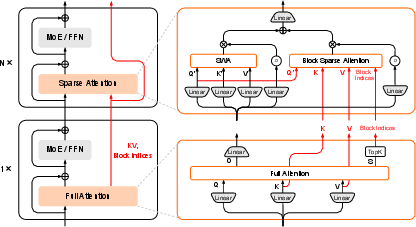
The HySparse idea
- Interleave layers: 1 full attention layer, then several sparse layers, then repeat.
- The full layer acts like an “oracle” (a reliable guide): it knows exactly which tokens were important.
- The following sparse layers reuse:
- The list of important tokens chosen by the full layer.
- The full layer’s stored memory (KV cache) for those tokens.
How HySparse picks “important tokens”
Instead of guessing with extra tools or rules, the full attention layer directly tells the next layers which tokens mattered most. This avoids mistakes from “proxy” methods that try to estimate importance.
How HySparse saves memory
Normally, sparse methods still keep a big KV cache because importance can change over time. HySparse shares the KV cache from the full layer with the following sparse layers, so it doesn’t store extra copies. It also adds a small SWA branch that keeps a tiny, local cache to capture nearby details (like recent sentences). This mix gives both global and local understanding without blowing up memory.
What did they find?
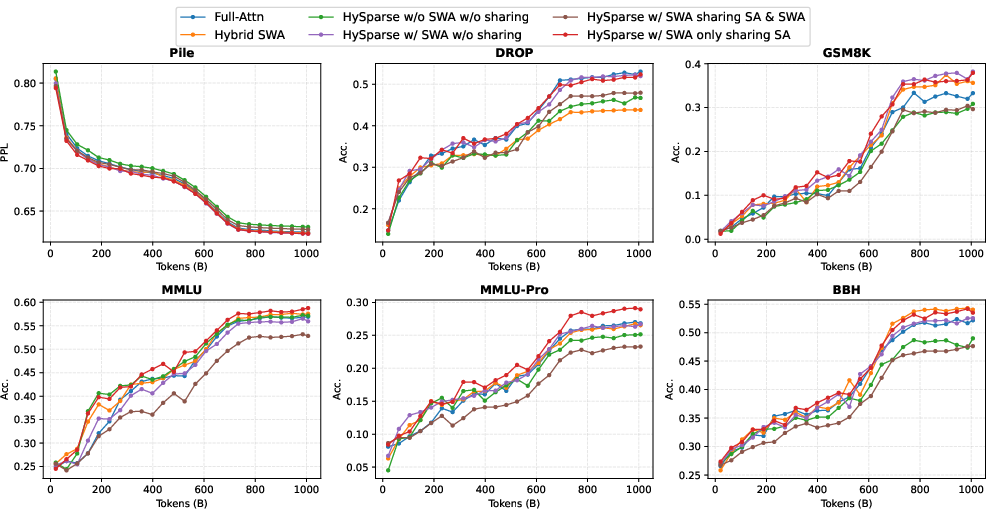
Across many tests, HySparse was both efficient and strong in accuracy. Here’s what stood out:
- Better accuracy than baselines: It beat both standard full attention models and popular “hybrid sliding window” models on a wide range of benchmarks (language understanding, reasoning, math, coding, and long-context tasks).
- Big memory savings: In a large 80B “Mixture-of-Experts” model with 49 layers, only 5 layers used full attention. Even so, HySparse kept high accuracy while reducing KV cache memory by nearly 10×.
- Long documents handled well: On long-context benchmarks, HySparse kept strong performance even when the hybrid ratio was very aggressive (very few full layers).
- Local + global balance helps: An extra small sliding window inside each sparse layer improved results, because it captures short-range details that global bookmarks might miss.
Why does this matter?
- Longer inputs, lower cost: Models can read longer documents, conversations, and instructions with less memory and compute, which means lower latency and higher throughput.
- Simpler design, fewer guesses: Using the full layer as an “oracle” means the model doesn’t need extra guesswork modules to pick important tokens, making training and use more stable.
- Practical deployment: Lower memory use means serving bigger batches and supporting longer contexts on the same hardware, which is great for chatbots, code assistants, and AI agents that work with long records or multi-step tasks.
The big takeaway
HySparse is a simple but effective redesign: let a full attention layer do precise, heavy lifting occasionally, then let several lighter sparse layers reuse its choices and memory. This cuts computation and memory while keeping or improving accuracy, especially for long texts. It could make future LLMs faster, cheaper, and better at handling lengthy inputs without needing massive hardware.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following points identify what remains missing, uncertain, or unexplored in the paper and suggest concrete directions for future work:
- End-to-end efficiency quantification: Report wall-clock latency, throughput, peak/resident GPU memory, and kernel-level overhead for the modified FlashAttention with block-score output, across sequence lengths and batch sizes, compared to Full-Attn, Hybrid SWA, and trainable sparse attention baselines.
- Selection metric fidelity: Test whether block-wise maximum attention scores are the optimal saliency proxy; compare against alternatives (block-wise sum, per-token TopK, entropy-based saliency, gradient-based importance) and measure token recall/precision relative to dense attention across tasks.
- Sensitivity to hyperparameters: Systematically vary TopK k, block size B, SWA window size w, number of sparse layers per block N, hybrid ratios, and placement of full-attention layers; derive guidelines or automated policies for layer scheduling.
- Placement of full-attention layers: Study optimal distribution of full layers (early vs middle vs late), including adaptive placement dependent on context or task, and quantify the trade-offs in accuracy and memory.
- Head/group diversity trade-off: Evaluate the impact of aggregating indices within GQA groups on expressivity; compare per-head vs per-group indices and quantify kernel efficiency vs accuracy trade-offs.
- Stability of salient tokens across depths: Provide empirical analysis of cross-layer token saliency stability across model sizes, domains (code, math, dialogue), and depths; identify regimes where stability breaks and when index refresh is needed.
- KV cache sharing dynamics: Analyze representational drift and gradient flow when sparse layers reuse KV from the preceding full layer; determine how many consecutive layers can safely share KV; explore adapters or re-projection layers to mitigate drift.
- SWA branch design space: Explore dynamic/learned window sizes, dilated windows, content-adaptive local ranges, and alternative fusion mechanisms (softmax gating, MoE-style routers, cross-attention fusion); quantify effects on locality-heavy tasks.
- Parameter tying and projections: Clarify whether SA and SWA branches share Q projections or use separate Wq/Wk/Wv; ablate parameter sharing vs separation and report parameter overhead and accuracy impacts.
- Robustness across task types: Extend evaluation to long-document generation (summarization), book-level QA, pointer-chasing tasks, and tool-use/agentic workflows; analyze failure modes where HySparse underperforms (e.g., observed drops on MMLU-Pro, DROP, ARC-C).
- MoE-specific interactions: Study how oracle selection interacts with expert routing (load balancing, specialization, interference); evaluate per-expert sparse indices, expert-specific KV sharing, and effects on MoE stability and throughput.
- Training vs post-training adoption: Assess whether HySparse can be retrofitted to pretrained models without full retraining (e.g., via distillation or SwiftKV-style adaptation), quantifying accuracy vs cost.
- Quantization compatibility: Evaluate INT8/FP8/FP4 quantization effects on shared KV and sparse kernels (including attention-scale calibration), especially for reasoning-heavy tasks where quantization may hurt performance.
- Very long-context scaling: Test beyond 32k (e.g., 64k, 128k, ≥256k) with appropriate positional encodings; characterize degradation patterns, index-refresh schedules, and memory behavior under extreme contexts.
- System-level KV offloading: Prototype the proposed offloading of full-attention KV to host/NVMe; measure PCIe/NVLink bandwidth, prefetch policies, eviction strategies, interactions with paged attention, and end-to-end serving gains.
- Adversarial/noisy context robustness: Investigate susceptibility to adversarial token injections or distractor-heavy contexts; determine whether oracle selection can be manipulated and design defenses (e.g., diversity or anti-spam constraints).
- Theoretical analysis: Develop bounds on approximation error from block-level selection; conditions under which KV sharing is equivalent (or near-equivalent) to recomputation; formalize the expected recall of salient tokens under HySparse.
- Encoder–decoder and multimodal applicability: Explore HySparse for encoder–decoder architectures and cross-attention (e.g., translation, speech, vision–LLMs); define token-selection strategies for cross-attention memories.
- Kernel implementation details: Release/open-source kernels; document memory layout for shared KV, indexing overhead, multi-GPU support, compatibility with FlashAttention versions, and batched decoding with variable sequence lengths.
- Statistical reliability: Report variance across seeds, confidence intervals, and nondeterminism controls for training/inference; ensure observed gains are statistically significant.
- Training cost accounting: Quantify training-time compute, optimizer dynamics, convergence speed, and total FLOPs relative to baselines; provide scaling-law behavior under HySparse.
- Large-scale ablations: Replicate the 7B ablation findings at 80B (MoE) scale to confirm the necessity of independent SWA KV and measure how scale alters design trade-offs.
- Data/domain dependence: Evaluate HySparse across varied corpora (programming, math, multilingual, dialogue) to test robustness of oracle selection and KV sharing beyond the reported datasets.
- Memory accounting clarity: Provide a detailed breakdown of the “~10× KV reduction,” including SWA KV footprint, sparse index metadata, gates, and any auxiliary buffers; reconcile theoretical vs measured memory savings.
- Inference-time index management: Describe how sparse indices are updated during autoregressive decoding, especially when context importance shifts; specify refresh cadence and its impact on accuracy/latency.
Practical Applications
Overview
The paper proposes Hybrid Sparse Attention (HySparse), an architecture that interleaves a small number of full attention layers with many sparse attention layers. Sparse layers reuse (1) the “oracle” salient token indices identified by the preceding full attention layer and (2) the full layer’s KV cache for global retrieval, while maintaining an independent sliding-window (SWA) branch and local KV for short-range modeling. The result is large memory savings (up to ~10× KV cache reduction in an 80B MoE model with only 5 full attention layers out of 49 total), improved or comparable accuracy across general, math, code, Chinese, and long-context benchmarks, and strong scalability to 32k contexts.
Below are the applications derived from these findings, organized by deployment horizon.
Immediate Applications
The following applications can be deployed now with moderate engineering effort, primarily involving kernel integration (modifying FlashAttention to emit block-level scores), hybrid-layer scheduling, and KV cache management.
- Cloud LLM serving and inference optimization (software; finance, customer service, e-commerce, media):
- Deploy HySparse in inference stacks to cut KV cache memory by ~10× (shown in 80B MoE), enabling larger batch sizes, longer contexts (up to 32k), and reduced cost per token.
- Tools/workflows: “HySparse-FlashAttention” kernel that emits block-level maxima for TopK selection; a “KVShare API” for cross-layer KV reuse; a “Hybrid Attention Planner” to schedule full:sparse ratios (e.g., 1:3 for 7B; 1:11 for 80B).
- Assumptions/dependencies: availability of GPU kernel engineering; engine support for cross-layer KV sharing; saliency stability across layers; careful memory management for shared KV.
- Enterprise RAG and long-document analysis (software; legal, finance, healthcare, insurance):
- Process much longer documents and corpora (contracts, filings, clinical notes) per request, while meeting SLAs and budgets due to reduced memory footprints.
- Tools/products: “HySparse-RAG” templates for retrieval+generation with 8–32k contexts; “Oracle TopK Selector” for salient block selection during generation.
- Dependencies: RAG pipelines need models trained or finetuned with HySparse; accurate TopK block selection configured (k≈1024, block size≈64 by default).
- Agentic workflows and test-time scaling (software; operations, research, automation):
- Run multi-step, tool-using agents with long memory traces and fewer attention bottlenecks, benefiting multi-turn planning and reasoning (supported by improvements on MMLU, GSM8K, and RULER).
- Tools: “HySparse Agent Memory” that pins sparse global KV across layers and uses SWA for local steps.
- Dependencies: frameworks must expose per-block indices from full layers to downstream sparse layers; gating stability during training/inference.
- MoE model serving at scale (software; cloud providers, LLM platforms):
- Interleave HySparse with MoE experts to keep memory pressure manageable while sustaining accuracy (validated at 80B with 1:11 hybrid ratio).
- Tools: “HySparse-MoE Scheduler” to control full attention placement (e.g., final layer full attention to preserve global aggregation).
- Dependencies: MoE dispatcher compatibility; stable gating; mixed precision support (BF16).
- KV offloading to host memory (systems; cloud platforms):
- Offload full-layer KV caches to CPU/NVMe and prefetch before sparse layers, keeping only selected sparse KV on GPU to boost throughput and reduce VRAM usage.
- Tools: “SparseKV Offloader” with pinned memory, prefetch queues, and block-wise cache layout aligned to TopK indices.
- Dependencies: high-bandwidth interconnects (PCIe Gen5/NVLink), pinned memory management, cache-aware scheduling.
- On-device assistants with extended memory (software/hardware; mobile, IoT, automotive):
- Enable 8–32k token contexts for offline personal assistants, meeting minutes, note-taking, and automotive logs with reduced compute and battery draw.
- Products: “HySparse Mobile Runtime” for NPU/GPU-capable devices; offline summarization and personal knowledge management.
- Dependencies: mobile kernels must implement block-score emission and shared KV; quantization compatibility (note that some studies report quantization may hurt reasoning).
- Code assistants for large repositories (software; developer tools):
- Provide longer project context (monorepos, multi-file codebases) at similar or lower serving cost, improving completion and navigation.
- Tools: “HySparse Code LLM” plugin for IDEs with repository-level context windows.
- Dependencies: repo indexing and chunking aligned with block attention; stable local SWA branch for near-context continuity.
- Academic training and finetuning (academia):
- Adopt HySparse in pretraining/finetuning to reduce memory and compute for long-context studies; replicate ablations showing the necessity of an independent SWA KV and the gains from intra-layer hybridization.
- Resources: “HySparse Training Cookbook” with kernel patches, recommended ratios, RoPE base frequency settings, and sink biases.
- Dependencies: integration with training stacks; modified FlashAttention; robust logging for TopK selection quality.
- Data center operations and cost control (industry/policy interface):
- Immediate cost and energy reductions for LLM inference at scale via memory savings and larger batch sizes.
- Workflows: capacity planning models updated for HySparse’s reduced KV footprint; energy dashboards reflecting improved joules/token.
- Dependencies: organizational buy-in; benchmarking under realistic traffic patterns.
- Benchmarking longer contexts (academia/industry):
- Use HySparse to push 32k context evaluations on RULER-like benchmarks without exponential cost increases, accelerating long-context research cycles.
- Tools: standardized evaluation harnesses with HySparse toggles and per-layer cache diagnostics.
- Dependencies: evaluation frameworks must track cache reuse correctness and latency.
Long-Term Applications
These applications require further research, scaling, hardware support, or ecosystem standardization before widespread deployment.
- Fully sparse architectures with minimal or no full attention (software/hardware co-design):
- Progressively reduce or eliminate full attention layers while maintaining accuracy via stronger oracle selection or learned selectors, pushing hybrid ratios further.
- Tools: end-to-end training strategies that stabilize purely sparse blocks; learned selectors bootstrapped from occasional full attention.
- Assumptions: cross-layer saliency remains robust; new stabilization tricks (gating, auxiliary losses) emerge; training complexity manageable.
- Standardized APIs for cross-layer KV sharing (software; frameworks):
- Introduce unified KV-sharing interfaces across vLLM/TGI/SGLang/Triton to make memory reuse portable and safe.
- Products: “KVShare Standard” and kernel ABI guidelines for block-wise KV layouts and TopK index broadcasting.
- Dependencies: community consensus; versioned kernel contracts; robust debugging tools.
- Hardware acceleration for block-level saliency and sparse KV (hardware; semiconductors):
- Add ISA or compiler-level support for block saliency extraction, TopK reduction, and sparse concatenation, reducing kernel overhead and making HySparse first-class in accelerators.
- Tools: “HySparse-aware compilers” (e.g., TileLang/Triton) and runtime schedulers that pipeline saliency, TopK, and KV prefetch.
- Dependencies: vendor adoption; performance validation across workloads; memory fabric optimizations.
- Multimodal long-context models (healthcare, robotics, media):
- Apply HySparse to video, audio, and sensor streams to keep long temporal windows affordable for clinical timelines, robot planning, and media editing.
- Products: “HySparse-VLM” for video-language tasks; long-horizon robotics planners with sparse global retrieval and local SWA branches.
- Dependencies: multimodal tokenization aligned with block attention; empirical saliency stability in multimodal layers; tailored SWA for modality-specific locality.
- Privacy-preserving healthcare and EHR assistants (healthcare; policy):
- On-device or hospital-hosted assistants with long patient histories, reducing cloud exposure and cost while maintaining accuracy.
- Tools: “HySparse Clinical LLM” with strict local KV and audited sparse retrieval to minimize data motion.
- Dependencies: clinical validation, regulatory compliance (HIPAA/GDPR), robust fail-safes for token selection fidelity.
- Education: long-memory personal tutors (education; consumer software):
- Tutors retain semester-long context on device or low-cost cloud tiers, supporting cumulative mastery and project histories.
- Products: “HySparse Tutor” with long-term learning traces and low operational costs.
- Dependencies: curriculum-aligned memory management; safeguards for hallucination; quantization-friendly configurations.
- Finance: long-horizon analysis of filings and market streams (finance):
- Process entire annual reports, multi-year filings, and streaming news in a single context window for compliance and risk analytics.
- Tools: “HySparse Filings Analyzer” integrating sparse global retrieval across time with local SWA for recent updates.
- Dependencies: data governance; integration with internal knowledge bases; robust latency SLAs.
- Energy and IoT: sensor-rich monitoring with long context (energy, manufacturing):
- Use HySparse for anomaly detection across long logs and time-series, keeping memory costs low in edge analytics.
- Products: “HySparse APM” for industrial telemetry; smart-grid long-context analysis.
- Dependencies: domain adapters; time-aware tokenization; stability under streaming updates.
- Agent memory architectures and hierarchical context (software; research):
- Build agent planners that combine sparse global memory retrieval with SWA-based local working memory, formalizing hierarchical memory control.
- Tools: agent frameworks with “memory budgets” per layer and learned gates for global-local fusion.
- Dependencies: training procedures for gate calibration; robust evaluation under long decode and tool use.
- Green AI policy and procurement standards (policy):
- Establish certifications or reporting for energy-efficient long-context inference (joules/token, batch-normalized memory footprint), encouraging adoption of HySparse-like designs.
- Workflows: energy labeling in model cards and procurement checklists.
- Dependencies: industry consortia; standardized measurement protocols; auditor tooling.
- Robustness and quantization research (academia/industry):
- Study interactions between HySparse and low-bit quantization (4–8 bit), ensuring reasoning quality remains strong with smaller models and devices.
- Tools: calibration pipelines that preserve saliency quality; mixed-precision gating strategies.
- Dependencies: benchmark suites sensitive to reasoning; joint kernel-quantization co-design.
Cross-cutting assumptions and dependencies
- Token saliency stability across consecutive layers underpins oracle selection; while empirically supported, it may vary by architecture/domain and should be monitored.
- Modified FlashAttention kernels must efficiently emit block-level maxima with negligible overhead and be maintained across GPU generations.
- Independent KV for the SWA branch is critical for local modeling; forcing SWA to share global KV degrades accuracy (as shown in ablations).
- Hyperparameters matter: typical defaults use
TopK≈1024tokens withblock size≈64,SWA window≈128, GQA grouping for index sharing, and full attention in the final layer. - Long-context scaling (e.g., RoPE base frequency adjustments) remains necessary; systems should support pinned memory, prefetch, and cache-safe layouts for offloading.
- Quantization and nondeterminism can affect reasoning; deployments should validate accuracy under target precision and kernel settings.
Glossary
- AdamW optimizer: A variant of the Adam optimizer that decouples weight decay from the gradient update to improve generalization in deep learning. "using the AdamW optimizer"
- agentic workflows: LLM-driven processes where models act as autonomous agents coordinating tasks and tools. "agentic workflows"
- BF16 precision: A 16-bit floating-point format (bfloat16) that preserves exponent range of FP32 to speed training while saving memory. "Training uses BF16 precision"
- Block Sparse Attention: An attention mechanism that restricts computation to selected blocks of key/value tokens instead of the full sequence. "Block Sparse Attention branch attends only to key-value blocks"
- block-wise attention scores: Aggregated attention magnitudes computed per block (tile) used to select important token regions efficiently. "derive block-wise attention scores by storing and appropriately rescaling it."
- Cross-layer KV cache sharing: Reusing key/value tensors from one layer in subsequent layers to reduce memory and bandwidth costs. "HySparse further incorporates cross-layer KV cache sharing."
- Cross-Layer Salient Token Stability: The empirical observation that tokens receiving high attention in one layer tend to remain important in adjacent layers. "Cross-Layer Salient Token Stability"
- dynamic sparsity: A sparsity pattern that adapts at runtime (per input/time step) to preserve model fidelity while reducing compute. "modern sparse attention methods increasingly adopt dynamic sparsity"
- end-to-end sparse pretraining: Training that directly integrates sparse selection into the main model objective so the selector learns via the full forward/backward signal. "performs end-to-end sparse pretraining"
- FlashAttention: A memory-efficient attention algorithm that computes softmax attention in tiles with online normalization to avoid materializing the full attention matrix. "FlashAttention"
- gated attention: An attention variant that applies learnable gates to stabilize or modulate attention outputs. "we additionally employ gated attention"
- Gated DeltaNet: A gated variant of DeltaNet (a linear-attention style module) used in hybrid architectures. "Gated DeltaNet"
- Grouped-Query Attention (GQA): An attention scheme where multiple query heads share a smaller set of key/value heads to reduce memory and compute. "Grouped-Query Attention (GQA)"
- HBM (High Bandwidth Memory): High-throughput on-package memory used in GPUs/accelerators for fast data movement. "from HBM to SRAM"
- heterogeneous interleaving: Alternating different attention mechanisms (e.g., full and sliding-window) across layers to balance performance and efficiency. "employ a heterogeneous interleaving of sliding window attention and global full attention layers."
- Hybrid Sparse Attention (HySparse): The proposed architecture that interleaves full attention layers with sparse layers that reuse indices and KV caches from the preceding full layer. "Hybrid Sparse Attention (HySparse)"
- KV cache: Stored key and value tensors for past tokens used to speed autoregressive decoding in transformers. "KV cache"
- KV cache eviction: Removing entries from the key/value cache, which can be irreversible and harm performance if important tokens are discarded. "complete KV cache eviction is irreversible and destructive"
- KV cache offloading: Moving key/value tensors to external memory and prefetching them to reduce GPU memory usage. "offload the full attention KV cache to external memory"
- Mixture-of-Experts (MoE): An architecture that routes tokens to a subset of specialized expert subnetworks, increasing capacity without proportional compute. "Mixture-of-Experts (MoE) model"
- online softmax: Computing softmax incrementally over tiles/blocks to avoid storing the full attention score matrix. "online softmax procedure"
- per-head learnable sink biases: Head-specific bias terms added to attention to stabilize focus (e.g., on sink tokens) and improve training. "per-head learnable sink biases"
- RoPE base frequency: The base angular frequency used in Rotary Position Embeddings that controls extrapolation to longer contexts. "The RoPE base frequency is adjusted to 640,000"
- scaled dot product self-attention: The standard transformer attention mechanism using scaled dot products between queries and keys followed by softmax over values. "The full attention layer computes standard scaled dot product self-attention"
- self-distillation: Training a model (or module) to match its own or a teacher’s predictions as an auxiliary objective, often to supervise token selection. "such as self-distillation"
- sigmoid gates: Learnable gating functions (sigmoid activations) that weight and fuse outputs from multiple attention branches. "sigmoid gates are applied to the output of the two branches"
- sliding window attention (SWA): Attention restricted to a fixed-size recent window of tokens to model local dependencies efficiently. "sliding window attention (SWA)"
- TopK operator: Selecting the K highest-scoring items (e.g., blocks by attention score) to limit attention computation to the most important tokens. "we apply a TopK operator to select"
- training-free sparse attention: Sparse attention methods applied without retraining, typically using fixed patterns or heuristics at inference. "Training-free methods rely on fixed patterns or heuristics"
- WSD schedule: A learning-rate schedule (Warmup–Stable–Decay) used to control training dynamics over long runs. "using the WSD schedule"
Collections
Sign up for free to add this paper to one or more collections.