- The paper introduces MoSKA to shift attention computations from memory-bound to compute-bound tasks, achieving up to 538.7× throughput gains.
- It employs a specialized disaggregated infrastructure and dynamic query batching to efficiently manage shared versus unique KV data, optimizing GPU utilization.
- The approach supports scalable long-sequence LLM inference with modular, position-independent caching for versatile and future-proof applications.
Mixture of Shared KV Attention for Efficient Long-Sequence LLM Inference
Introduction
The burgeoning need for extensive context windows in transformer-based LLMs has highlighted a critical bottleneck—namely, the Key-Value (KV) cache. Despite modern optimizations such as Grouped-Query Attention, sparse attention, and quantization, the KV cache size scales unfavorably with batch size and sequence length, presenting a persistent challenge for system memory (Figure 1).
The scaling of memory bandwidth requirements compounds the issue, as each request's query must access shared data, resulting in GPU under-utilization due to memory-bound operations. Addressing the memory capacity is insufficient without fundamentally altering attention computation itself.
MoSKA leverages the heterogeneous nature of context data by distinguishing between unique, per-request data and shared, massively reused data. It introduces Shared KV Attention, transforming memory-bound operations into compute-bound tasks, supported by MoE-inspired sparse attention and a tailored disaggregated infrastructure (Figure 2). This combination successfully tackles both bandwidth scaling bottleneck and throughput inefficiencies, paving the way for scalable long-sequence LLM inference.
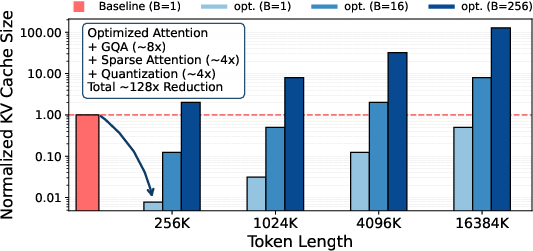
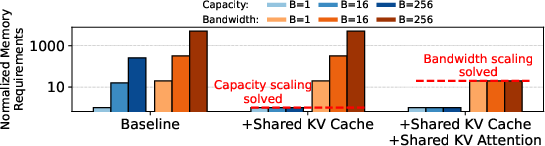
Figure 1: Hardware Requirement Challenges. (a) shows that even with significant optimizations (GQA, Sparse attention, Quantization) with widely-used optimization levels, KV cache size still scales with sequence length and batch size. (b) illustrates that while sharing the KV cache solves the memory capacity scaling, memory bandwidth requirements still scale with the batch size.
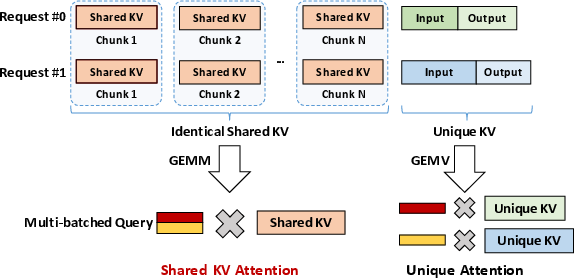
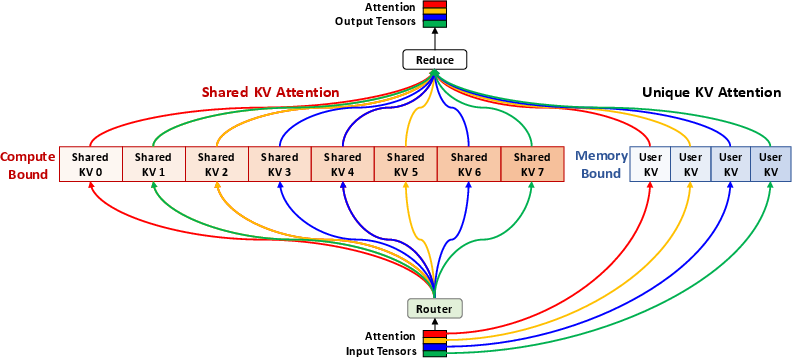
Figure 2: The MoSKA Architecture. detailing its core mechanism and high-level structure.
MoSKA stands on the shoulders of existing research to form a cohesive architectural solution combining various techniques. These include KV cache reuse, shared attention, and system disaggregation. Approaches like prefix reuse in multi-turn conversations and Cache-Augmented Generation reveal opportunities for efficient direct attention over massive shared contexts, necessitating a sophisticated handling system.
Despite advances in KV cache sharing, implementations often struggle with batching flexibility and bandwidth problems, such as strict sequential matching in SGLang and ChunkAttention. MoSKA dynamically batches queries to shared data, beyond prefixes, allowing general application scope.
The blending of MoE-inspired sparse attention and disaggregated infrastructure addresses computational efficiency and resource contention fundamentally. MoSKA partitions attention computation based on data profiles—hardware specialization for compute-bound shared data versus memory-bound unique data—ensures optimized resource allocation.
Proposed Architecture
MoSKA manages large-scale shared KV data as a persistent resource, employing key components like Shared KV Attention and MoE-inspired routing for efficient long-sequence inference.
Shared KV Attention Mechanism
MoSKA differentiates between unique KV operations (memory-bound GEMV) and identical shared KV data accessed by multiple requests. The latter utilizes Shared KV Attention, aggregating queries into large-scale GEMM operations, enhancing arithmetic intensity and GPU utilization. This shift from bandwidth to computation bottleneck dramatically improves throughput.
MoSKA Architecture
The architecture utilizes MoE-inspired routing to manage shared KV spaces by selecting relevant chunks for each query. It calculates relevance scores dynamically, optimizing sparse attention mechanisms to prune computational space, thereby enhancing efficiency and scalability.
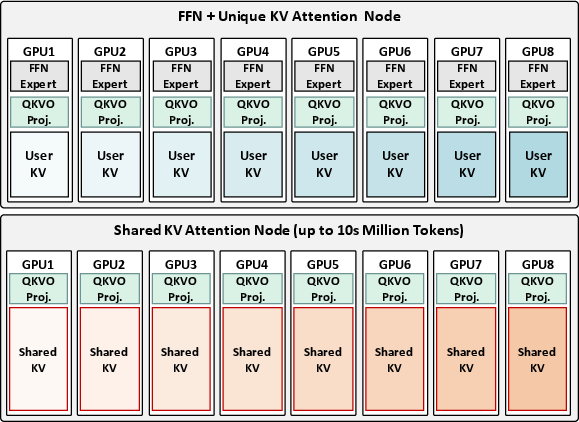
Figure 3: Proposed disaggregated LLM serving infrastructure for MoSKA.
Disaggregated Infrastructure
MoSKA employs hardware specialization to mitigate resource contention. Unique KV Nodes handle latency-sensitive sequences, while Shared KV Nodes focus on throughput for compute-bound tasks. This optimized separation insures scalability without over-provisioning, enhancing system responsiveness and efficiency.
Universal MoSKA for Composable Context
Long-term visions for MoSKA include Universal MoSKA, leveraging position-independent caching to create modular libraries detached from specific contexts. This infrastructure could dynamically compose knowledge-based responses across varied domains, further advancing AI capabilities.
Evaluation
Evaluations of MoSKA using analytical models against state-of-the-art baselines demonstrate up to 538.7× throughput increases, highlighting its efficacy in transforming shared attention operations into compute-bound tasks.
Batch Scaling and Throughput
MoSKA's use of Shared KV Attention results in higher throughput and batch handling capability compared to other methods, effectively addressing bandwidth bottlenecks and improving GPU utilization.
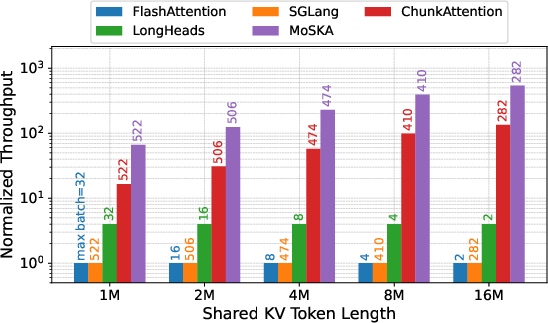
Figure 4: Batch scaling capability and normalized throughput.
Resource Utilization
MoSKA’s disaggregated infrastructure showcases superior resource allocations, ensuring scalability and efficient memory and compute usage. Through specialized node designs, MoSKA optimizes workload handling, maximizing system performance.
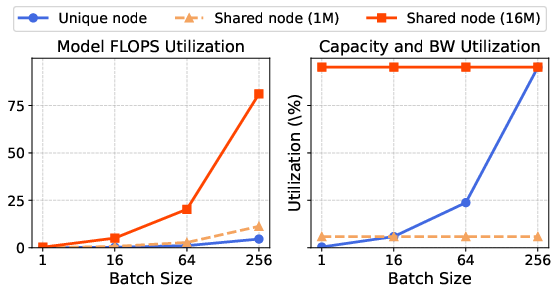
Figure 5: MFU and memory utilization of each node.
Conclusion
MoSKA's architecture systematically resolves the KV cache bottlenecks inherent in LLM inference. By shifting operational tasks from memory to computation-bound processes, MoSKA significantly enhances throughput and efficiency. Future avenues will focus on implementing sophisticated scheduling algorithms and advancing MoSKA's position-independent capabilities for dynamic knowledge composition.