- The paper introduces an EFG framework that evaluates autoformalization by dissecting logical preservation, mathematical consistency, formal validity, and formal quality.
- It employs 12 interpretable atomic properties aggregated via a linear ensemble model, achieving a strong correlation with human judgment.
- Empirical results show that LLM-based judges, particularly GPT-4.1 variants, effectively capture nuanced evaluation aspects beyond traditional metrics.
The evaluation of autoformalization—the translation of informal mathematical statements into formal languages—has become critical for advancing formal mathematical reasoning. As LLMs achieve impressive results in formalization tasks, the precise assessment of their outputs remains a challenge, especially given the multidimensionality of correctness and faithfulness in formal representations. Existing evaluation protocols rely predominantly on syntactic validity or coarse-grained criteria, often resulting in binary or reference-biased assessments that fail to capture nuanced quality attributes. Human evaluation, although reliable, becomes impractical in advanced mathematical domains due to the requisite expertise and scalability constraints.
The paper introduces an epistemically and formally grounded (EFG) framework for evaluating autoformalization, constructing a taxonomy of four core aspects:
- Logical Preservation (LP): Assessing the fidelity with which the logical structure and inferential intent of the natural language statement are retained in the formalization.
- Mathematical Consistency (MC): Evaluating the semantic accuracy of mathematical objects and operations.
- Formal Validity (FV): Verifying syntactic and structural correctness within the target formal system (Isabelle/HOL, Lean4).
- Formal Quality (FQ): Measuring clarity, conciseness, and non-redundancy.
This taxonomy is operationalized via 12 interpretable, computable Operable Atomic Properties (OAPs), such as quantification, formula preservation, referential completeness, type-matching, conciseness, and logical consistency, which enable systematic estimation of each aspect.
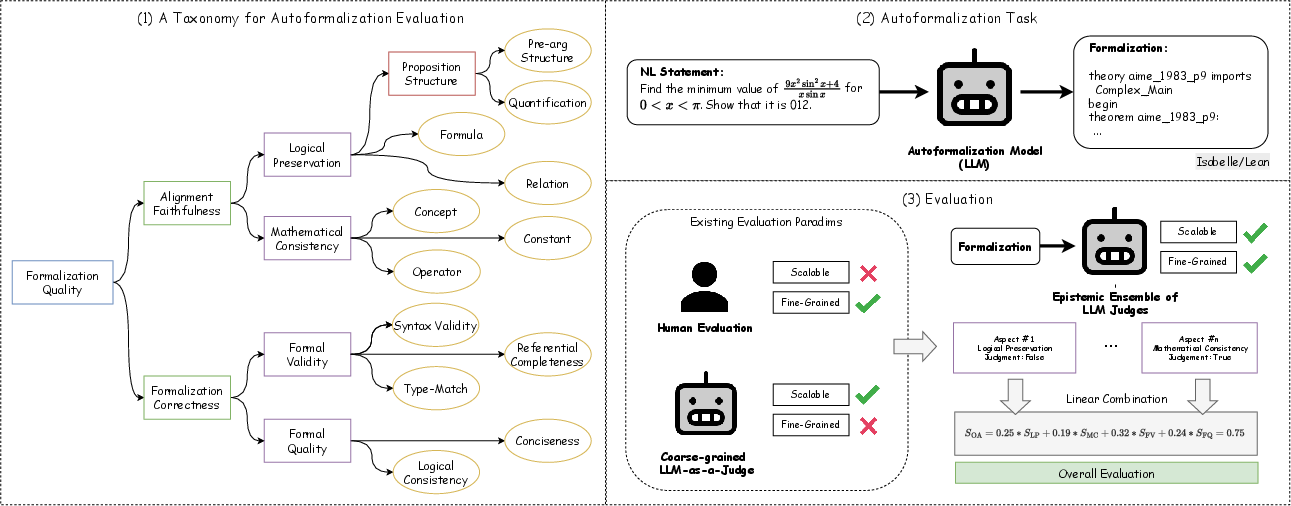
Figure 1: Overview of the EFG-LMM judge ensemble framework, incorporating scores from LLM judges and theorem provers into a single assessment via weighted aggregation.
Human Evaluation and Linear Ensemble Model
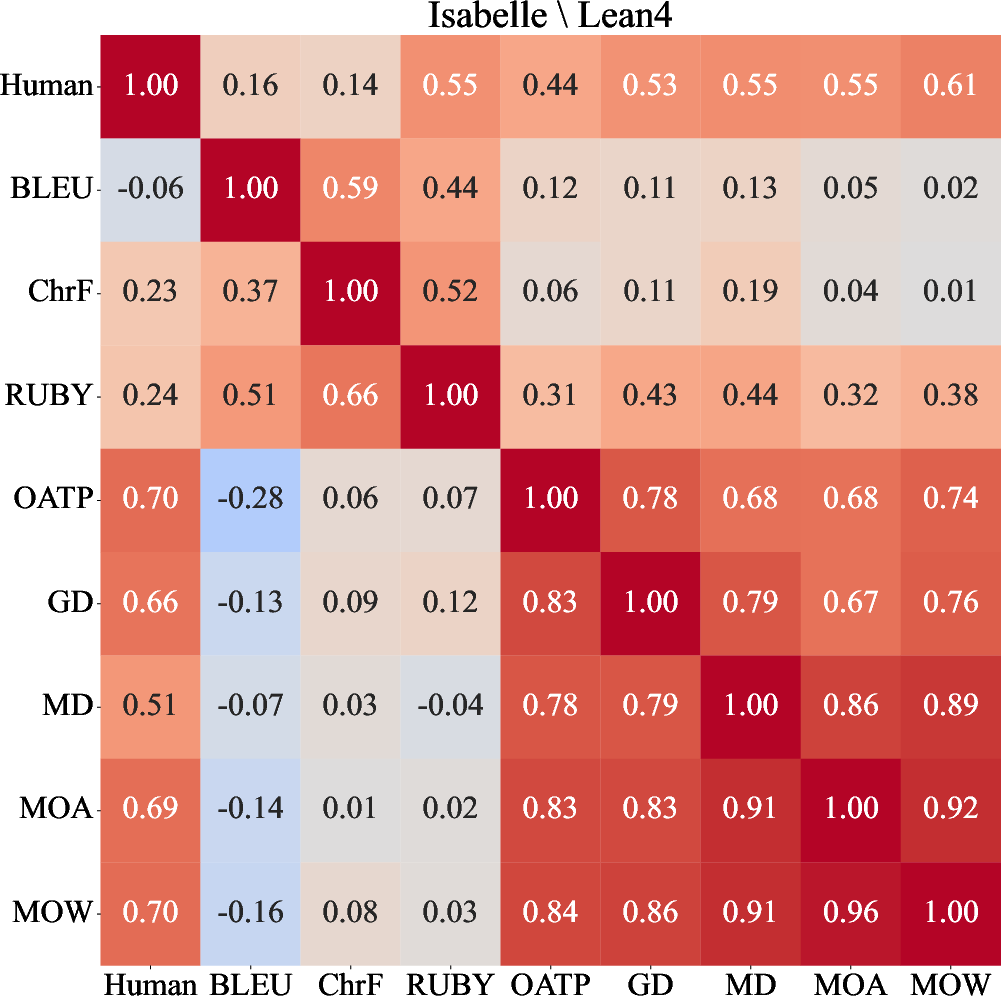
The framework was validated through human annotation of formalizations from miniF2F and ProofNet datasets, covering Isabelle/HOL and Lean4. Empirical analysis demonstrates that logical preservation and mathematical consistency are often insufficient in ground-truth formalizations, and that LLMs like GPT-4.1 are competent at identifying problematic cases. Formal validity, as determined by theorem provers, shows strongest correlation with overall quality, but quality is multifaceted—LP and MC exhibit low inter-correlation, confirming that these aspects are not redundant.
A linear ensemble model synthesizes aspect scores:
SOA(s,ϕ)=wLPSLP(s,ϕ)+wMCSMC(s,ϕ)+wFVSFV(ϕ)+wFQSFQ(ϕ)
Optimal weighting (wLP=0.25, wMC=0.19, wFV=0.32, wFQ=0.24) is determined via constrained quadratic programming, yielding a strong correlation (Coef=0.785, NRMSE=0.284) with human assessment.
LLM-as-Judge: Comparative Evaluation
LLM judges, tested with both direct aspect assessment and OAP-based aggregation, were benchmarked against human evaluations. The results indicate:
Robustness and Reliability Analysis
Evaluation with multiple LLMs (GPT-4.1-Mini, Qwen2.5-Coder-7B) reveals that although absolute scores vary, the ranking of autoformalization performance remains consistent. No evidence was found for cross-family bias favoring same-series autoformalizations. Empirical variance analyses show robustness across temperature settings—overall assessment scores remain stable despite randomness, though component scores (MC, FQ) fluctuate more with higher sampling diversity.
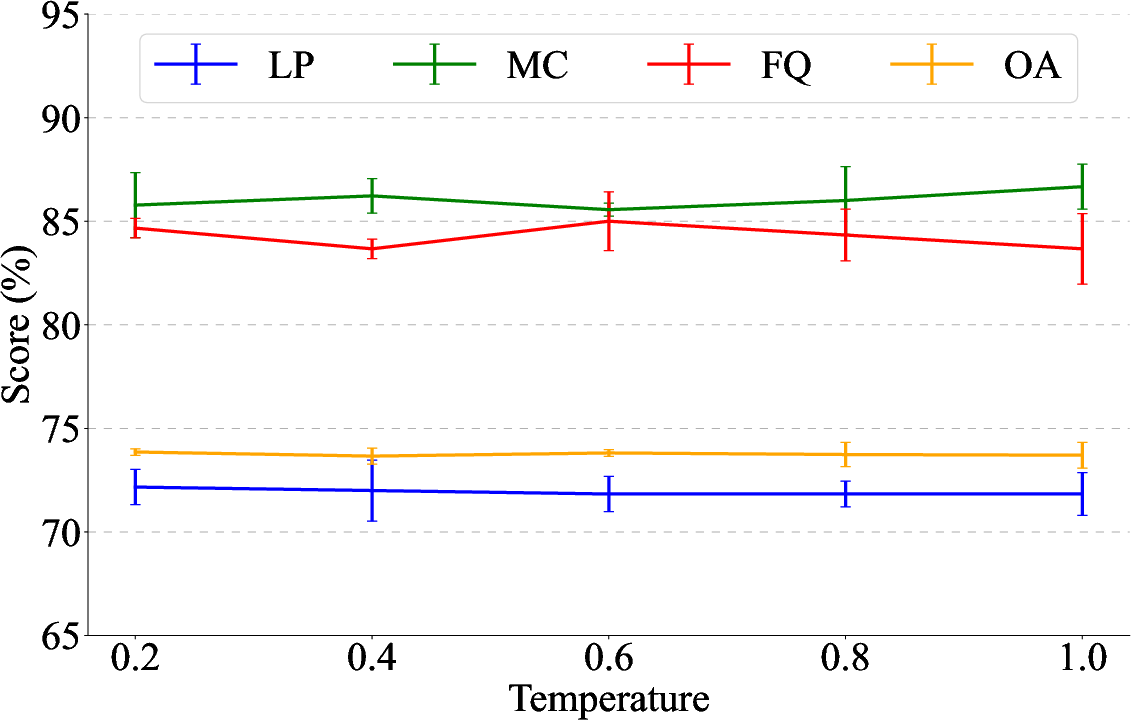
Figure 3: Error bars for GPT-4.1-Mini OAP-WA scoring across temperatures and runs, illustrating stable OA score distributions.
Agreement analysis between LLM-judges and theorem provers using Cohen's kappa shows LLMs are not reliable proxies for formal validity; agreement rarely exceeds $0.3$, especially in more restrictive languages like Lean4.

Figure 4: Cohen's kappa for agreement between LLM-judges and theorem provers for formal validity on miniF2F, highlighting the limits of LLM evaluation for syntactic correctness.
Implications and Future Directions
The fine-grained, interpretable EFG ensemble offers a scalable and reproducible evaluation protocol for autoformalization tasks. Core numerical results highlight that OAP-guided ensembles not only outperform direct assessment from larger LLMs but also provide richer, aspect-specific feedback. This circumvents reference bias and enables systematic benchmarking across varying model architectures and datasets.
The practical implication is that lightweight LLMs, properly structured via atomic property prompts, are sufficient for reliable judgment, enabling automated evaluation without expensive human annotation. Theoretically, disentangling alignment faithfulness from formalization correctness paves the way for models to optimize distinct aspects of formalization simultaneously and supports more granular error analysis.
Open questions remain regarding the optimal design of OAPs, judge-ensemble training/fine-tuning strategies, and integration of LLM explanations for boosting autoformalization quality. Further directions include specializing smaller open-source LLMs as domain-calibrated judges and leveraging self-improving evaluators for continuous refinement.
Conclusion
This work establishes a comprehensive multidimensional evaluation paradigm for autoformalization in formal mathematics, leveraging epistemic ensembles of LLM judges structured by interpretable atomic properties. The approach consistently yields stronger alignment with human judgment than coarse metrics, and enables robust, scalable evaluation of formalization systems. Limitations include dependence on small annotated sets and subjectivity in certain aspects, but the methodology is generalizable. Future research should further automate LLM judge calibration and expand the taxonomy to cover broader formal reasoning domains.