- The paper introduces a novel iterative RL framework (ReVeal) that co-evolves code generation and verification, boosting Pass@1 accuracy from 36.9% to 42.4%.
- It employs a multi-turn reward design with outcome and dense per-turn rewards to guide the model’s self-evolving process during code generation.
- The framework leverages external tools for automated test case execution and feedback, demonstrating superior performance on benchmarks like LiveCodeBench.
ReVeal: Self-Evolving Code Agents via Iterative Generation-Verification
The paper introduces ReVeal, a novel multi-turn RL framework designed to enhance the reasoning and problem-solving capabilities of LLMs, specifically in the domain of code generation (2506.11442). ReVeal distinguishes itself by enabling LLMs to engage in an iterative generation-verification loop, leveraging external tools for precise feedback and customized RL algorithms with dense, per-turn rewards. This approach fosters the co-evolution of a model's generation and verification capabilities, expanding the reasoning boundaries of the base model.
Iterative Generation-Verification Framework
ReVeal's core innovation lies in its iterative generation-verification loop, which mirrors the human problem-solving process of generating a candidate solution, verifying its correctness, and refining it based on feedback. This framework consists of two key stages: generation and verification (Figure 1).
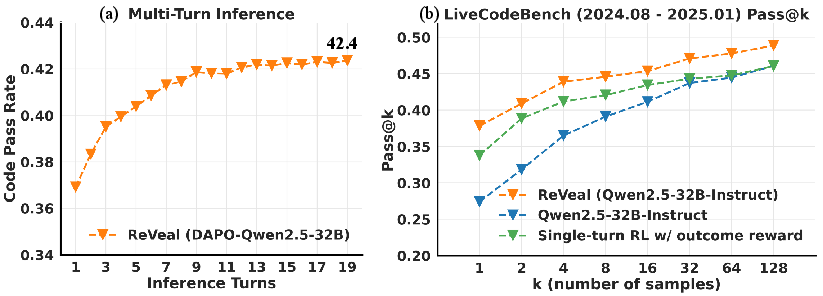
Figure 2: Performance of ReVeal on LiveCodeBench, highlighting its effective test-time scaling and superior Pass@k accuracy compared to baseline methods.
In the generation stage, the LLM produces a candidate code solution based on the given problem description. In the verification stage, the model constructs test cases and invokes external tools, such as Python interpreters, to execute the code and verify its correctness. The feedback from these tools, including runtime errors and test case results, is then incorporated into the prompt for the next turn, allowing the model to iteratively refine its output.
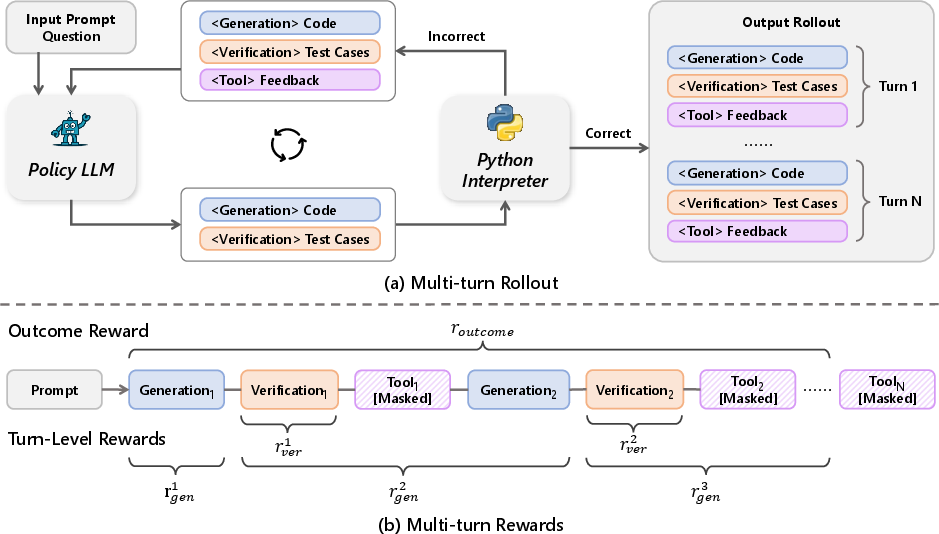
Figure 1: An illustration of the ReVeal framework, detailing the multi-turn rollout process and reward design.
This iterative process is facilitated by a structured prompting format that decouples generation, verification, and tool feedback into an iterative loop using distinct tags. The model reasons about the problem under <generation-think> and produces a candidate solution within <generation-answer>. It then initiates the verification phase, constructing a plan under <verification-think> and specifying test cases under <verification-answer>. The <tool-feedback> section captures execution results, providing fine-grained supervision and guidance for subsequent cycles.
The interaction between the LLM and external tools is crucial for ensuring the accuracy and reliability of the verification process. During training, execution results are parsed into structured <tool-feedback>, guiding the model's next generation-verification turn. To ensure feedback quality, a filtering mechanism is employed: test cases generated by the model are executed on the candidate code only if they are verified as correct against a golden solution.
During RL training, the <tool-feedback> section is excluded from the loss computation and treated solely as contextual input to stabilize training and preserve the model's coherent reasoning sequences.
Multi-Turn RL Algorithm with Turn-Level Reward Design
ReVeal introduces a structured set of turn-level, verifiable rewards for both generation and verification turns, decomposing the final reward into an outcome reward and dense per-turn rewards. The outcome reward consists of a format reward rformat and a pass-rate reward rpassrate:
$r_{\mathrm{outcome} = r_{\mathrm{format}} + r_{\mathrm{passrate}}$
For each generation turn k, the per-turn generation reward is defined as:
$r_{\mathrm{gen}^k =
\begin{cases}
r_{\mathrm{passrate}^1, & k = 1,\[6pt]
\mathit{abs}\cdot r_{\mathrm{passrate}^k + \mathit{imp}\cdot\bigl(r_{\mathrm{passrate}^k - r_{\mathrm{passrate}^{k-2}\bigr), & k \ge 3, \end{cases}$
where abs and imp are hyperparameters that weight the absolute code accuracy and the improvement of code accuracy over the previous turn, respectively.
For each verification turn k, the reward is defined as the proportion of generated test cases that succeed when executed on the golden code:
$r_{\mathrm{ver}^k = \frac{\#\{\text{test cases in turn }k\text{ that pass}\}}{\#\{\text{test cases generated in turn }k\}}$
The paper introduces Turn-Aware PPO (TA-PPO), which preserves the standard PPO actor-critic framework but replaces the conventional GAE-based advantages with a turn-aware return. TA-PPO leverages the critic to efficiently bootstrap over both token-level Monte Carlo returns and turn-level returns, enabling stable learning across these two reward scales.
Experimental Results and Analysis
The ReVeal framework was evaluated on the LiveCodeBench benchmark (Jain et al., 2024) using Qwen2.5-32B-Instruct (Qwen et al., 2024) and DAPO-Qwen-32B (Yu et al., 18 Mar 2025) as base models. The results demonstrate that ReVeal significantly outperforms standard RL baselines and critic-based methods such as CTRL (Xie et al., 5 Feb 2025).
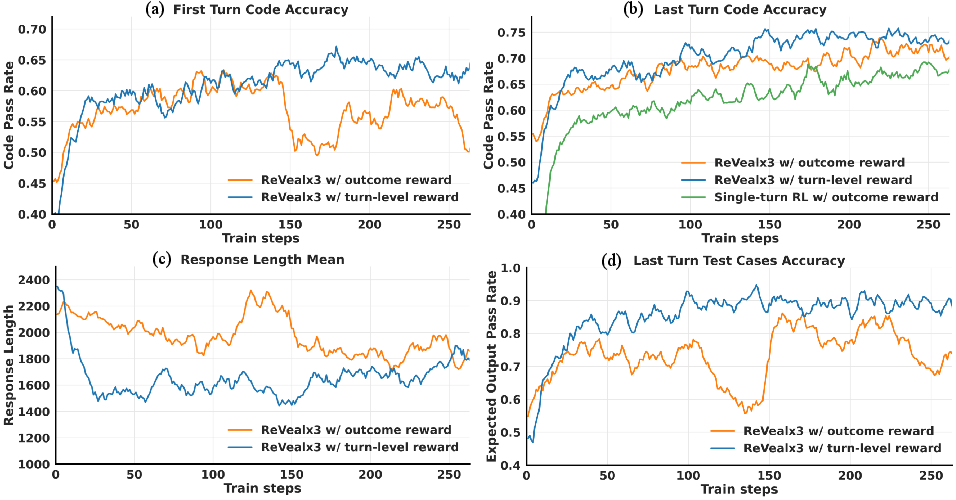
Figure 3: A comparison of code accuracy, test case accuracy, and response length across training for different reward schemes.
ReVeal enables test-time scaling into deeper inference regimes, with Pass@1 accuracy improving from 36.9\% at turn 1 to 42.4\% at turn 19 (Figure 2). The framework also demonstrates the ability to expand the reasoning boundaries of the base model, consistently outperforming both the base model and the RL baseline across all k values from 1 to 128. Ablation studies on the reward design further show that incorporating dense, turn-level rewards leads to improvements in Pass@1.
Implications and Future Directions
The ReVeal framework demonstrates the potential of self-verification and iterative refinement for enhancing the reasoning capabilities of LLMs. The framework's ability to enable test-time scaling and push beyond the reasoning boundaries of the base model has significant implications for the development of more robust and autonomous AI agents. The approach of iterative generation-verification and dense reward design can be applied to other domains with verifiable solutions and verifications, offering a promising blueprint for future advances in self-improving AI systems.
Conclusion
ReVeal offers a compelling approach to enhancing LLMs' reasoning capabilities through an iterative generation-verification paradigm. By integrating self-verification mechanisms, leveraging external tools, and employing a customized RL algorithm with dense, per-turn rewards, ReVeal facilitates the co-evolution of generation and verification capabilities, leading to significant performance improvements and the ability to tackle previously intractable problems. The research suggests a promising path towards developing more robust, scalable, and autonomous AI agents capable of continuous self-improvement.