- The paper introduces DeepResearch Bench, a benchmark that evaluates DRAs using novel RACE (report quality) and FACT (web retrieval) frameworks.
- It employs a large dataset filtered from 96,147 queries to create 100 research tasks distributed across 22 domains.
- Experimental analysis shows leading performance of models like Gemini-2.5-Pro and Claude-3.7-Sonnet, aligning closely with human judgments.
DeepResearch Bench: A Comprehensive Benchmark for Deep Research Agents
This paper introduces DeepResearch Bench, a novel benchmark designed for evaluating the capabilities of Deep Research Agents (DRAs). The benchmark comprises 100 research tasks spanning 22 domains, crafted by domain experts to mirror real-world research requirements. The authors address the limitations of existing evaluation frameworks by proposing two new methodologies: RACE (Reference-based Adaptive Criteria-driven Evaluation) for assessing report quality and FACT (Factual Abundance and Citation Trustworthiness) for evaluating information retrieval and citation accuracy. The efficacy of these frameworks is validated through comprehensive experiments and human studies.
DeepResearch Bench and Data Collection
The construction of DeepResearch Bench involved a systematic approach to ensure its relevance and representativeness. The authors began by analyzing a dataset of 96,147 user queries to determine the distribution of research topics. These queries were filtered using DeepSeek-V3-0324 to identify those aligning with deep research requirements, resulting in 44,019 queries.
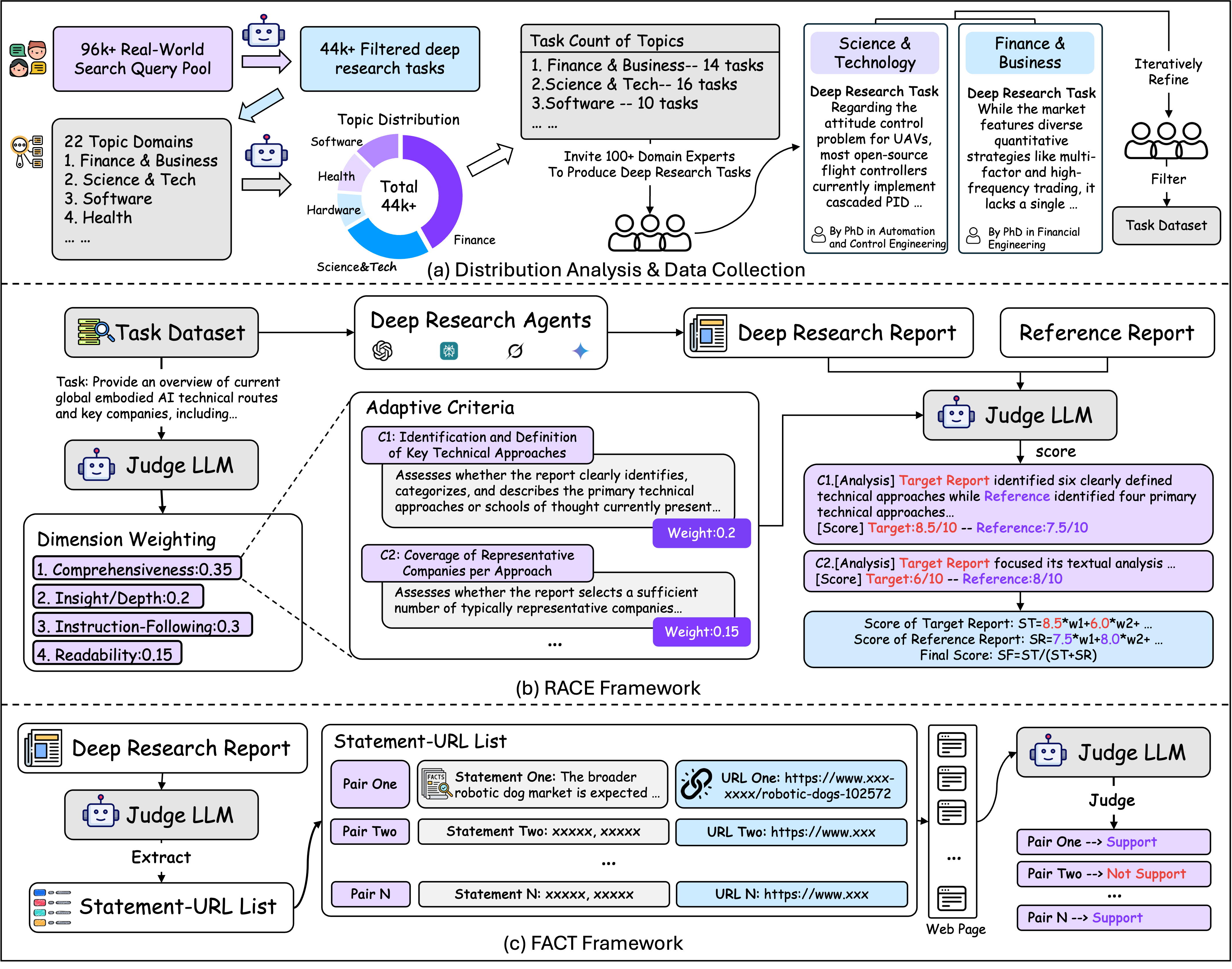
Figure 1: Overview of DeepResearch Bench including the distribution analysis and dataset construction pipeline (a), RACE (b), and FACT (c).
The queries were then classified into 22 distinct topic domains based on the WebOrganizer taxonomy, providing insights into real-world user demand for deep research within these areas. The benchmark tasks were subsequently created, balancing Chinese and English tasks, and refined by Ph.D. holders and senior practitioners. Examples of the task distributions are shown in (Figure 2) and (Figure 3).
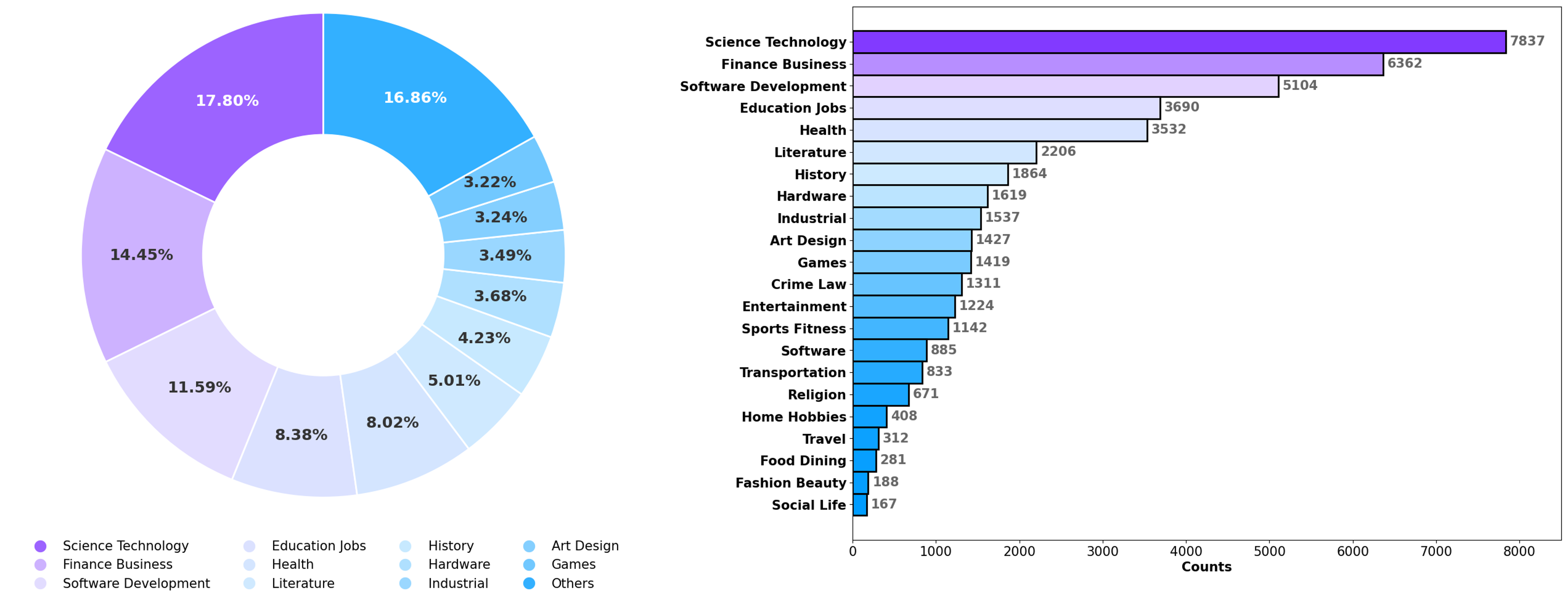
Figure 2: Topic distribution of the filtered deep-research tasks, including a donut chart showing proportional share of each topic domain (left) and a bar chart listing the absolute task counts for all 22 domains (right).
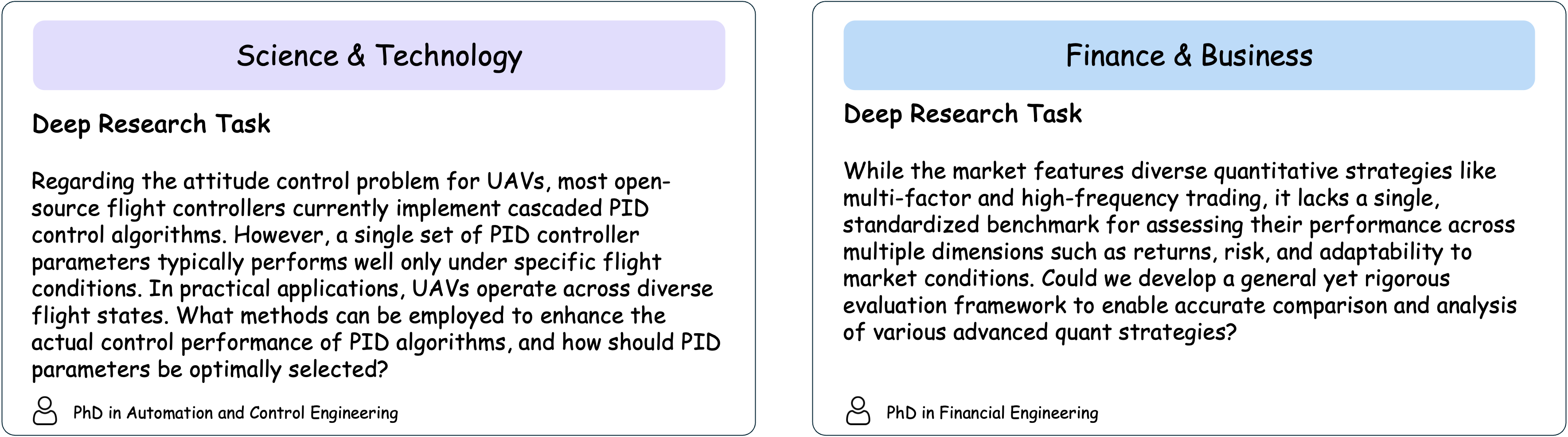
Figure 3: Two example tasks from DeepResearch Bench.
Evaluation Methodologies: RACE and FACT
RACE: Report Quality Evaluation
The RACE framework addresses the shortcomings of traditional evaluation methods by dynamically generating task-specific weights and criteria. It leverages the LLM-as-a-Judge method, using Gemini-2.5-pro to assess report quality based on four dimensions: Comprehensiveness, Insight/Depth, Instruction-Following, and Readability.
The framework operates in three key stages: dynamic weight and adaptive criteria generation, reference-based scoring, and overall score calculation. By comparing target reports with high-quality references, RACE mitigates biases and ensures a more accurate evaluation of report quality.
FACT: Web Retrieval Evaluation
The FACT framework evaluates the factual grounding of report content and the agent's effectiveness in retrieving and utilizing web-based information. This framework employs a Judge LLM to extract statement-URL pairs from reports, deduplicate them, and assess whether the webpage content supports each statement. Citation Accuracy and Average Effective Citations per Task are the primary metrics used to gauge performance.
Experimental Results and Analysis
The authors evaluated several DRAs and LLMs with search tools using DeepResearch Bench and the RACE and FACT frameworks. The results, as shown in (Figure 4), indicate that Gemini-2.5-Pro Deep Research achieves leading overall performance in report quality, while also obtaining a high number of effective citations.
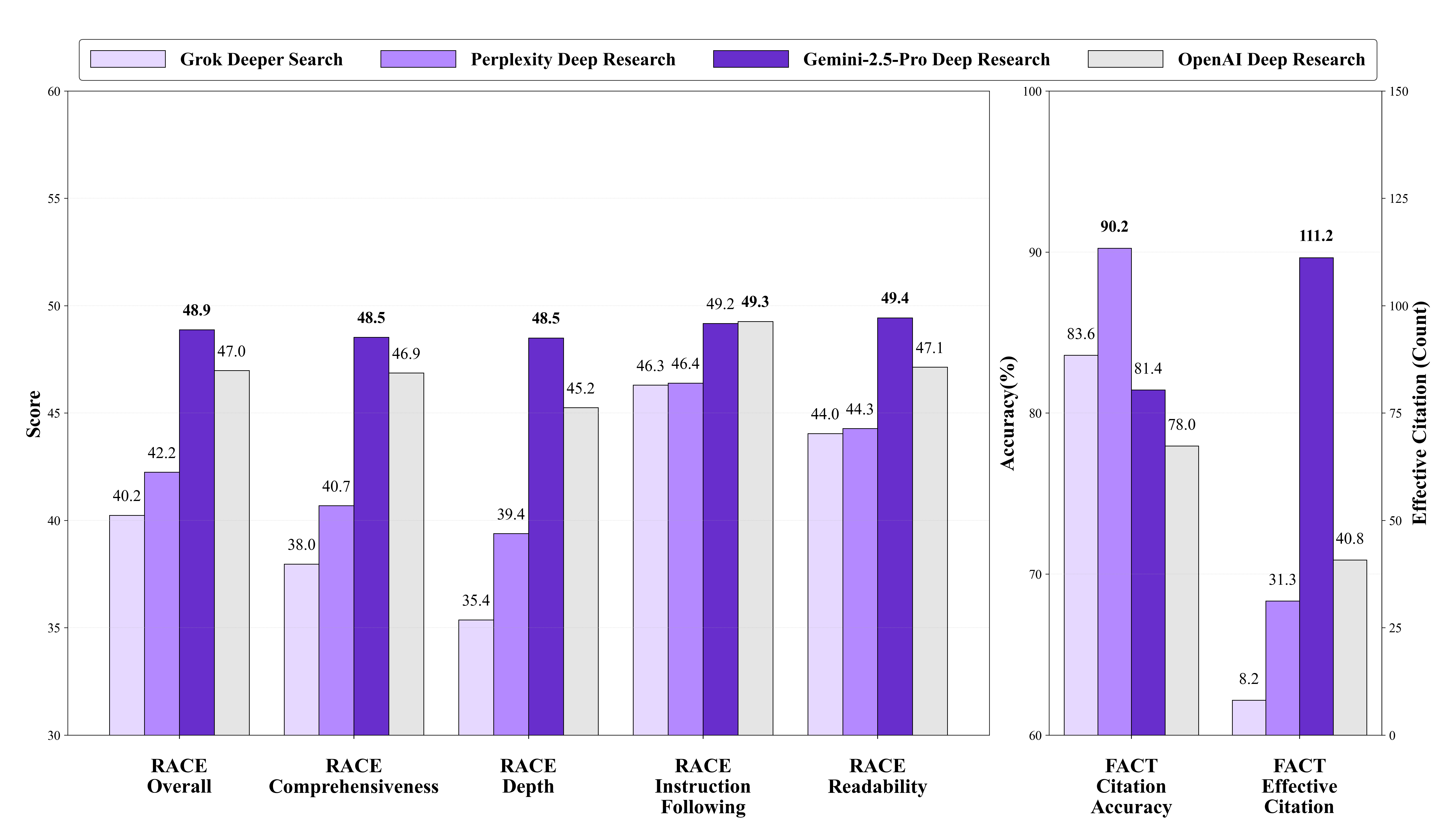
Figure 4: Overview of agent performance on DeepResearch Bench, including generated report quality scores across evaluation dimensions (left) and agent citation accuracy and average number of effective citations (right).
Claude-3.7-Sonnet with Search delivers impressive performance among the LLMs with search tools, even exceeding Grok Deeper Search. The performance of different models across various topics and languages evaluated by RACE are shown in (Figure 5).
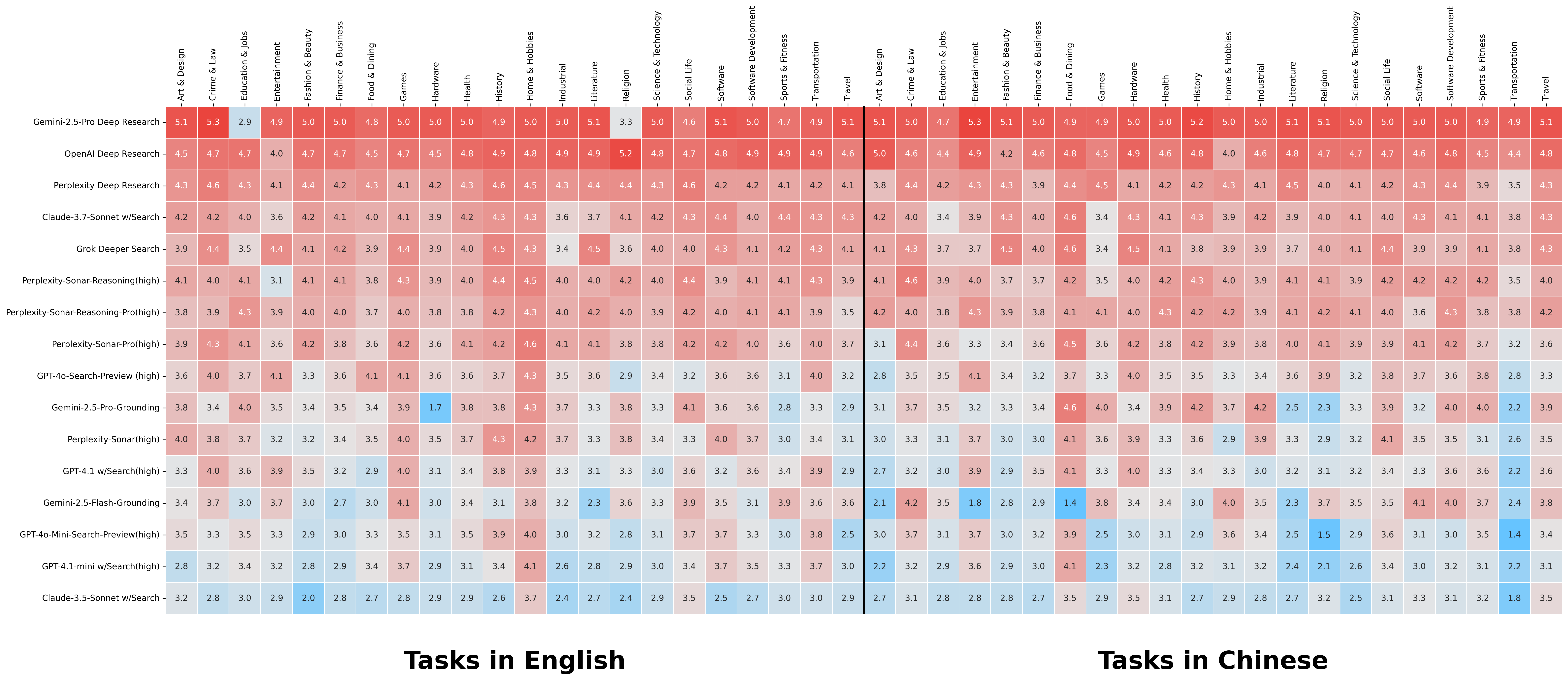
Figure 5: Scores of different models across various topics and languages evaluated by RACE, where red indicates a higher score and blue indicates a lower score.
Further experiments validated the human consistency of the RACE framework, demonstrating a strong correlation between RACE scores and human judgments.
Conclusion
DeepResearch Bench presents a valuable resource for evaluating DRAs, offering a comprehensive benchmark and evaluation frameworks that align with human judgment. The results and analyses presented in this study provide insights into the strengths and weaknesses of current DRAs, paving the way for future advancements in AI agent systems. The authors acknowledge the limitations of the benchmark, including its scale and potential domain coverage bias, and outline plans for future improvements.