- The paper introduces a novel structural approach by extending facial keypoints and leveraging PoseC3D to effectively capture subtle micro-gestures for emotion inference.
- Temporal alignment techniques, such as uniform interval sampling and linear interpolation, ensure complete and smooth capture of discriminative motion cues.
- Integration of semantic label embeddings enhances model generalization, achieving a Top-1 accuracy of 67.01% on the challenging iMiGUE dataset.
Fine-Grained Emotion Understanding via Skeleton-Based Micro-Gesture Recognition
Introduction
The study addresses the challenge of skeleton-based micro-gesture recognition (MG recognition) for fine-grained emotion understanding, within the context of the MiGA Challenge at IJCAI 2025. The core difficulty lies in the subtle, short, and low-amplitude nature of micro-gestures, which differentiate the problem from conventional action or gesture recognition. Recognizing such gestures necessitates highly sensitive and semantically aligned motion modeling, particularly in sparse and contextually complex datasets like iMiGUE. The solution is predicated on PoseC3D as a baseline, augmented by a dataset-customized skeletal topology, advanced temporal alignment, and the integration of semantic label embeddings for enhanced generalization.
Topology-Aware Skeleton Representation
Effective discrimination of micro-gestures hinges on representing subtle localized motions, especially within the facial region where many emotion-related actions originate (e.g., lip biting, face touching). The study extends the standard 22-joint OpenPose skeleton to 41 keypoints through the addition of targeted facial landmarks. This newly proposed skeletal topology provides a higher spatial resolution for the body regions most relevant to hidden emotion inference.
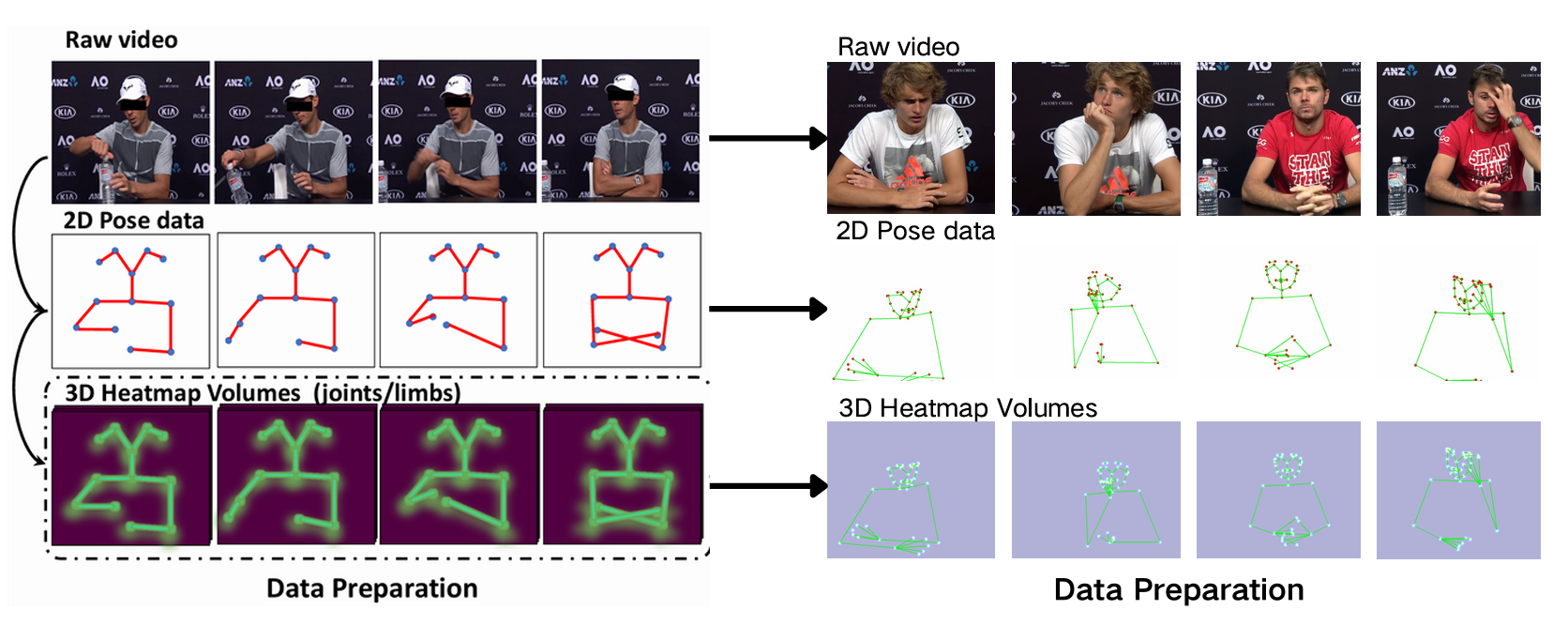
Figure 1: Visualization of the proposed new skeletal joint connection diagram for micro-gesture classification.
The design is drawn from the ST-GCN paradigm but tailored for iMiGUE, acknowledging that typical partitioning schemes (centripetal, centrifugal) are ill-suited for the low-motion, high-density facial regions critical to micro-gesture decoding.
Further comparative analysis demonstrates how varying the keypoint definition (quantity and connectivity) drastically affects the expressivity, model behavior, and ultimately the quantitative classification performance.
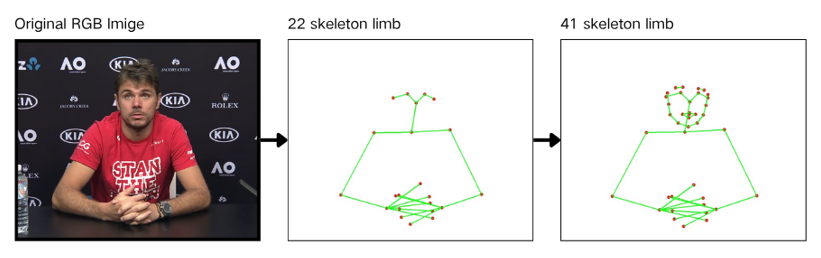
Figure 2: Comparison of skeletal connectivity with different numbers of keypoints.
Model Analysis: ST-GCN vs. PoseC3D Architectures
Experiments contrast ST-GCN—a graph convolutional approach reliant on fixed topology and local partition reasoning—and PoseC3D, which represents skeleton motion as spatiotemporal volumetric heatmaps processed with 3D CNNs. The inclusion of facial keypoints reveals a fundamental discrepancy:
- In ST-GCN, the surging graph complexity, limited annotated data, and relatively stationary facial motion cause these new nodes to act as noise, promoting overfitting and deteriorating classification. The architecture's rigidity prevents exploitation of semantic cues in low-mobility regions.
- PoseC3D, in contrast, leverages its fully-convolutional, topology-agnostic framework. Heatmap encoding of all keypoints (including static regions) increases information entropy and supports the discovery of fine-grained behavioral cues. Empirically, extending PoseC3D with facial keypoints yields significant performance benefits.
This underlines the critical model-architecture/data topology alignment required for micro-gesture tasks and underscores the advantage of dense, uniform spatial modeling for subtle body dynamics.
Temporal Alignment and Processing
MG detection is especially sensitive to temporal sampling strategies. Standard practices (random cropping, zero-padding) risk omitting discriminative micro-gesture frames or introducing abrupt discontinuities, both of which mislead temporal feature learning. The solution proposes:
- Uniform interval sampling for long sequences, ensuring full temporal coverage.
- Linear interpolation for short sequences, maintaining continuity and smoothness.
These modifications ensure trajectory-level preservation of subtle micro-actions and eliminate artificial signal breaks, with direct improvements measured in both model stability and accuracy.
Integration of Semantic Label Embeddings
Given strong label imbalance and semantic overlap among MG classes, auxiliary supervision in the form of semantic label embeddings is incorporated. This leverages external representations to encourage generalization and alleviate confounders among closely related gesture categories.
Experimental Results
Performance is evaluated on the iMiGUE dataset, containing 32 MG classes plus background, sourced from press conference footage of elite tennis athletes. The approach achieves a Top-1 accuracy of 67.01%, ranking third on the MiGA Challenge leaderboard, and consistently outperforms the previous solutions, especially those relying on ST-GCN or unaugmented PoseC3D. Notably, the method registers relative performance gains across all input modalities and ensemble settings, with joint-limb multimodal fusion yielding the best result.
Implications and Future Directions
This work demonstrates that skeleton topology—and its alignment with task-specific dynamics and model class—is pivotal for high-fidelity micro-gesture recognition and by extension fine-grained emotion inference from sparse kinetic cues. The results highlight the limitations of fixed-graph architectures and the value of topology-independent, high-entropy heatmap representations. Improvements in temporal modeling and auxiliary semantic guidance are also validated as critical for robust classification in challenging datasets.
Looking forward, potential avenues include the optimization of noise-robust training for better handling of imbalanced tail classes, advanced data augmentation and denoising, and the integration of RGB/appearance-based streams to complement skeletal dynamics. Extending these findings to real-world emotion-understanding systems can further enable robust, privacy-preserving, and scalable human-affective computing.
Conclusion
The solution for skeleton-based micro-gesture recognition effectively combines a dataset-adaptive skeletal topology, advanced temporal processing, and semantic label supervision within a 3D-convolutional framework. The systematic quantitative and qualitative comparisons delineate the architectural requirements for MG analysis and highlight the unique suitability of PoseC3D, especially when augmented with high-resolution facial keypoints. These findings inform future work on multi-modal, topology-aware emotion recognition systems and provide practical guidelines for modeling subtle human behavior from structured motion data.