Uncertainty-Informed Active Perception for Open Vocabulary Object Goal Navigation
Published 16 Jun 2025 in cs.RO | (2506.13367v2)
Abstract: Mobile robots exploring indoor environments increasingly rely on vision-LLMs to perceive high-level semantic cues in camera images, such as object categories. Such models offer the potential to substantially advance robot behaviour for tasks such as object-goal navigation (ObjectNav), where the robot must locate objects specified in natural language by exploring the environment. Current ObjectNav methods heavily depend on prompt engineering for perception and do not address the semantic uncertainty induced by variations in prompt phrasing. Ignoring semantic uncertainty can lead to suboptimal exploration, which in turn limits performance. Hence, we propose a semantic uncertainty-informed active perception pipeline for ObjectNav in indoor environments. We introduce a novel probabilistic sensor model for quantifying semantic uncertainty in vision-LLMs and incorporate it into a probabilistic geometric-semantic map to enhance spatial understanding. Based on this map, we develop a frontier exploration planner with an uncertainty-informed multi-armed bandit objective to guide efficient object search. Experimental results demonstrate that our method achieves ObjectNav success rates comparable to those of state-of-the-art approaches, without requiring extensive prompt engineering.
The paper introduces a semantic uncertainty-informed pipeline using prompt ensembling to address challenges in open-vocabulary object goal navigation.
It integrates probabilistic semantic estimates with a geometric-semantic map updated via Kalman filter equations for real-time navigation.
A multi-arm bandit exploration planner leveraging expected improvement and GP-UCB balances semantic exploitation with exploration.
Uncertainty-Informed Active Perception for Open-Vocabulary Object Goal Navigation
Introduction and Motivation
Embodied agents operating in indoor environments frequently face the challenge of open-vocabulary object goal navigation (ObjectNav): given a goal specification (e.g., "find a printer"), efficiently search for and navigate to the corresponding object. Recent advances have leveraged large vision-LLMs (VLMs) to ground open-ended language queries into actionable visual perception. However, the semantic uncertainty introduced by prompt phrasing variations, and the statistical variability of VLM similarity scores, remains largely underexplored in embodied navigation systems.
This paper introduces a semantic uncertainty-informed active perceptual pipeline for ObjectNav. The central insight is to move beyond ad hoc prompt engineering and instead incorporate explicit models of the uncertainty inherent to VLM-based semantic perception into planning and exploration. The system further integrates these probabilistic semantic signals into a geometric-semantic map and designs an uncertainty-aware exploration planner that uses a multi-arm bandit formulation to actively guide language-conditioned navigation.
Figure 1: Uncertainty-informed ObjectNav system overview: given a target object, semantic relevance estimates (blue Gaussians) are computed for frontiers (yellow rectangles) on a geometric-semantic map (purple), and the robot actively explores by selecting frontiers via a bandit planner.
System Architecture
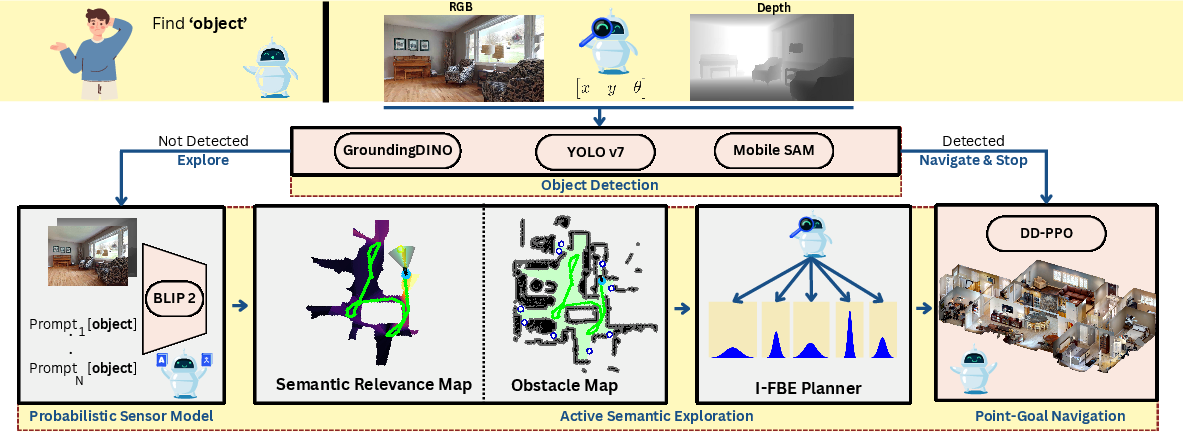
Object Detection and Navigation
The ObjectNav system comprises two main modules: (i) object detection, which combines both closed-set (YOLOv7) and open-vocabulary (Grounding DINO) detectors, and (ii) an active semantic exploration planner.
Upon detecting the target object o in the current egocentric RGB-D observation, the system deploys a segmentation model (MobileSAM), estimates 3D object coordinates using the detected mask and depth, and invokes state-of-the-art point-goal navigation (DD-PPO).
Figure 2: ObjectNav pipeline: the system attempts target object detection from the present observation; if unsuccessful, it switches to active semantic exploration using the probabilistic map.
Should the target not be detected, the system proceeds to uncertainty-informed semantic exploration, described below.
Probabilistic Semantic Relevance Estimation
Classic object search with VLMs suffers from prompt sensitivity ("cup", "the cup", "there is a cup ahead" yield different outputs). To model this, the paper proposes a probabilistic sensor model built on prompt ensembling:
An ensemble of N varied prompts pi is generated for each target object using a LLM.
Each prompt is scored with BLIP-2: for a given camera image Irgb and textual prompt pi, cosine similarity S(lrgb,lpi) in the shared language-vision embedding space provides a scalar relevance score.
The set of N scores is treated as samples of a Gaussian, with mean and variance (μZ,σZ2) forming a semantic relevance measurement model.
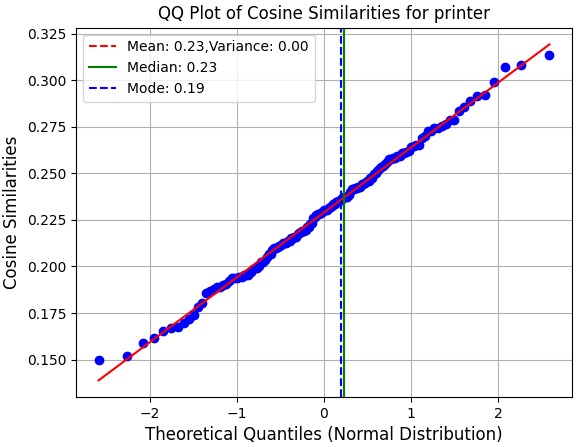
Empirical justification for Gaussian modeling is established via quantile-quantile analysis against the standard normal:
Figure 3: QQ-plot for 100 VLM similarity scores from prompt ensembling reveals their near-Gaussian distribution, validating the sensor model's normality hypothesis.
A viewpoint-dependent pixel-level variance correction is introduced to discount reliance on off-center image regions, yielding a final per-pixel variance estimate.
Probabilistic Geometric-Semantic Mapping
A 2D geometric-semantic occupancy grid map is maintained, with each cell storing both occupancy probability (from depth) and a probabilistic estimate of semantic relevance (from the above sensor model). The semantic relevance posterior is updated in closed-form via Kalman filter equations, exploiting the conjugacy of Gaussian priors and measurements. This enables online map updates per timestep, fusing both geometry and semantic information under uncertainty.
Exploration in the absence of object detection is cast as a frontier search task: the robot considers boundaries between explored and unexplored space as candidate frontiers, each evaluated with a posterior N(μS,t,σS,t2) over semantic relevance.
The paper introduces two planners based on bandit reward functions:
I-FBE1: Expected Improvement, measuring the expectation that exploring a frontier improves upon the current best semantic relevance.
I-FBE2: Gaussian Process Upper Confidence Bound (GP-UCB), combining exploitation (μS,t) and exploration (βσS,t).
The planner actively selects frontiers to stochastically balance exploitation of semantically promising locations with exploration of high-uncertainty, potentially informative regions.
Empirical Evaluation
Prompt Engineering and Uncertainty
Strong evidence is presented that ObjectNav performance using VLMs is highly sensitive to prompt selection, with 2% differences in success rate for prompt variations differing only by a single word. The uncertainty-informed prompt ensemble approach, without hand-tuning, consistently matches or outperforms hand-tuned baselines across evaluation splits in terms of success rate, with only a modest decrease in SPL due to more exploratory behavior.
Notably, semantic relevance scores from ensembling exhibit near-Gaussian behavior across objects and scenes, supporting the probabilistic sensor model as statistically adequate.
ObjectNav Performance and Planner Analysis
Both I-FBE1 and I-FBE2 perform at least as well as (and sometimes better than) state-of-the-art prompt-engineered open-vocabulary ObjectNav systems, while requiring no prompt tuning and providing increased robustness to prompt and perception variability. However, the planners occasionally trade off path optimality (SPL) in favor of robust semantic exploration, reflecting a deliberate bias towards thoroughness under uncertainty.
Computationally, the full system operates in real time with sub-second per-step planning overhead.
Discussion and Implications
This method constitutes a significant advance in semantic navigation, demonstrating effective integration of uncertainty into perception and planning for open-vocabulary goals. By explicitly modeling the uncertainty in VLM-based semantic signals, the method sidesteps burdensome prompt engineering, increases robustness to linguistic ambiguity, and promotes more reliable semantic exploration.
The system is readily extensible to variants of the ObjectNav task, and can be integrated with auxiliary vision-language features, scene graph priors, or real-world robot platforms. Limitations include potential over-exploration in environments with severe aliasing or where semantic priors are poor, as indicated by modest reductions in SPL. Further, computational bottlenecks may arise as the number of prompts or map resolution increases.
Future work could explore richer uncertainty models (non-Gaussian posteriors, multimodal distributions), self-adaptive prompt set selection, real-world field validation under severe sensor noise, and integration with LLMs for dynamic instruction following. Potential synergies arise with recent open-query scene understanding models, as well as with generative world models capable of integrating open-ended visual and linguistic cues for planning.
Conclusion
This paper establishes that explicit modeling of semantic uncertainty via prompt ensembling in VLM-driven ObjectNav obviates the need for hand-tuned prompt engineering and enables uncertainty-aware semantic exploration. Empirically, the resulting system is competitive with or superior to prior fixed-prompt baselines and exhibits greater robustness. The architecture, built atop probabilistic sensor models, semantic mapping, and bandit-based planning, provides a strong foundation for robust open-vocabulary goal-directed navigation in unstructured environments. The approach opens several avenues for extending open-ended language-based perception and action in real-world robotic agents.