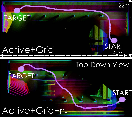- The paper presents a RL framework that couples active perception with goal-driven navigation for aerial robots, enhancing situational awareness with an actuated camera.
- It employs a multi-objective reward function, including a voxel-based information gain term, to balance collision avoidance with exploratory behavior.
- Empirical evaluations show improved environment coverage (up to 63.4%) and low crash rates, demonstrating robust sim2real performance in cluttered settings.
Reinforcement Learning for Active Perception in Autonomous Navigation: An Expert Analysis
Introduction and Motivation
This work introduces a reinforcement learning-based framework that integrally couples active perception with safe goal-directed navigation in aerial robots. The authors address a critical limitation in contemporary navigation systems—the passive treatment of perception via fixed sensors. By equipping a quadrotor platform with an actuated camera system, the proposed approach enables dynamic viewpoint control, fostering more sophisticated situational awareness and exploratory behavior in unknown, cluttered environments.
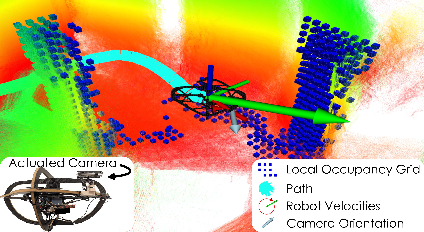
Figure 1: The quadrotor platform equipped with an actuated camera system. The local occupancy grid informs the robot about the nearby obstacle while the camera is directed to explore new regions in cluttered environments.
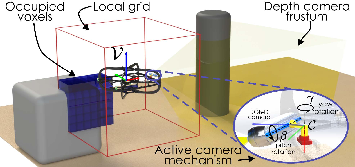
Figure 2: The quadrotor platform with its actuated RGB-D camera system.
The navigation problem is modeled as a Partially Observable Markov Decision Process, where the agent must optimize collision-free motion to a goal and simultaneously decide camera orientations for enhanced perception. The action space is expanded to include both linear/yaw velocities and camera pitch/yaw references. Observations comprise odometry, depth frames compressed via Deep Collision Encoder (DCE), local ego-centric occupancy grids, and historical action-state information. The local occupancy grid ensures resilience to odometric drift and encodes short-horizon geometric context for collision avoidance.
Methodology
RL-Based Policy Architecture
The network architecture utilizes dedicated encoder streams for depth images and local occupancy grids, processed through ResNet modules. A MLP/GRU sequence integrates robot, camera states, and latent encodings, outputting continuous controls for both flight and camera actuation.
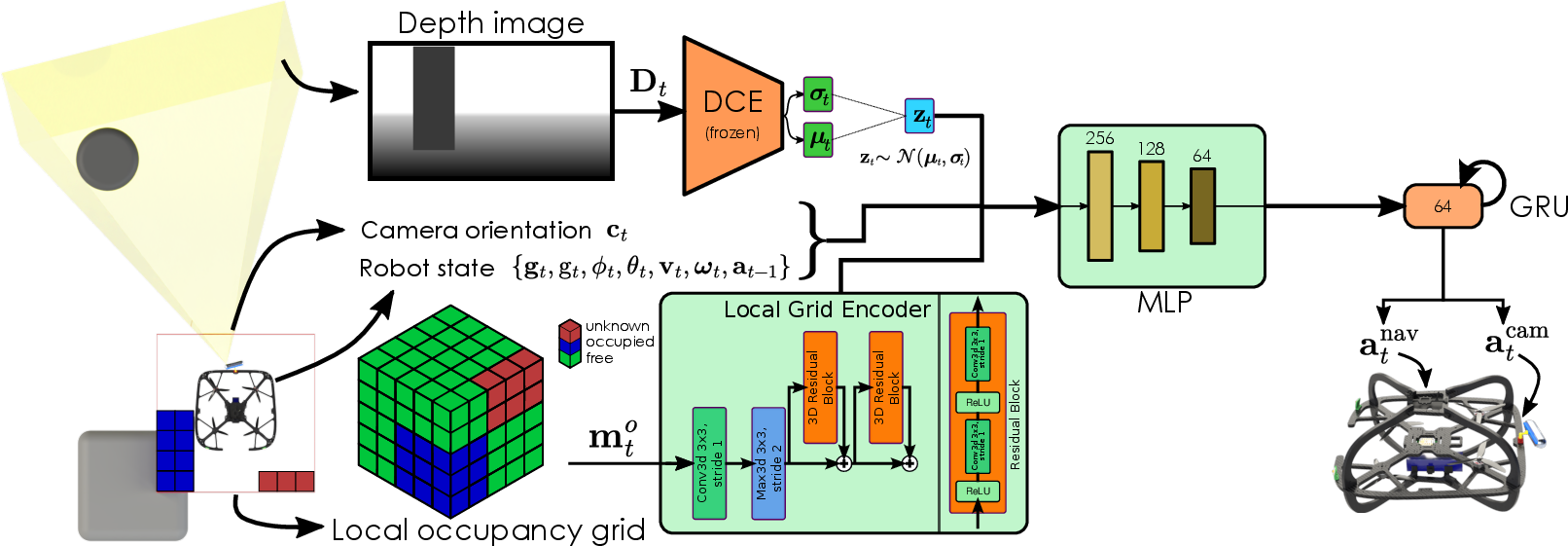
Figure 3: The proposed network architecture for safe navigation with active perception. The network processes depth images as well as the local occupancy grids through dedicated encoder blocks, integrates robot state and camera orientation via MLP and GRU modules, and commands the actions for the robot.
A salient methodological innovation addresses the interaction between perception and action: the reward function is multi-objective, with terms for navigation progress, action smoothness, collision avoidance, and a voxel-based information gain. The latter intrinsically rewards discovery of new spatial information, promoting exploration beyond merely safe navigation.
Training Environment and Robustification
Episodes are simulated using the Aerial Gym Simulator with randomized primitive obstacles (box, cylinder, etc.) and both sensor and actuator noise injections to facilitate robust sim2real transfer.

Figure 4: Aerial Gym training environment with randomized primitive obstacles ensuring diverse scenarios and sim2real transferability.
Empirical Evaluation
Ablation Studies
Nine different agent configurations evaluate the impact of static vs. active camera, local grid inputs, and exploration reward (nt) across increasing obstacle densities. Success rates, crash rates, and spatial exploration metrics are reported.
Simulation Studies
The policy augmented with nt reward consistently outperforms pure navigation objectives, discovering up to 61% of a previously unknown environment during Gazebo-based missions, versus only 47.5% for the variant lacking nt.
Real-World Deployment
Experiments on a custom quadrotor platform validate sim2real transfer, demonstrating collision-free navigation, active environmental scanning, and adaptability in both cluttered and T-shaped corridors. The agent actively manipulates the camera to scan lateral or occluded regions prior to commitment to navigation maneuvers.
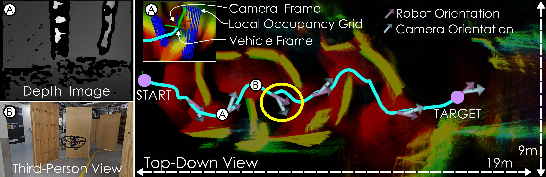
Figure 6: Top-down view of navigation through a cluttered corridor. The cyan trajectory and point cloud show the robot's path and perception. Gray and purple arrows indicate camera orientations diverging from robot heading for enhanced spatial awareness. Network inputs (depth image, local occupancy grid) are shown at time A; a third-person mission view at time B.
Comparison with static camera baselines shows pronounced deficiencies in narrow or branched environments. The static method suffered collisions and required environmental modification for eventual target success.
Figure 7: Navigation missions in a T-shaped corridor comparing (Active+Grid+nt) with Static+FOV~\cite{kulkarni2024reinforcement}. The trajectories highlight the differences in navigation performance.
Implications and Future Prospects
The integration of active perception control with RL-based navigation yields dual gains in safety and spatial awareness. The multi-objective reward framework enables policies to trade off goal progress and exploration, resulting in robust behavior suitable for inspection, search-and-rescue, and exploration applications. The agent’s ability to direct sensing actively is critical in occluded, dynamic, or highly cluttered domains.
From a theoretical standpoint, this work substantiates the necessity of actuated perception modules and local geometric reasoning in RL navigation frameworks. The voxel-based information gain term provides a practical route toward unsupervised spatial understanding, bringing RL closer to generalized autonomy.
Future research can extend the framework to semantic search tasks (e.g., object-specific exploration), adaptation to dynamic obstacles, and continual learning for lifelong environmental understanding. Integrating semantic cues into the information gain reward and augmenting the platform with multi-modal sensors (e.g., radar, thermal) remain promising directions.
Conclusion
This paper demonstrates an effective RL approach for autonomous aerial navigation that actively fuses perception and motion planning. The proposed method achieves strong empirical results in both simulated and real environments, advancing agent safety and spatial exploration through actuated camera control and voxel-based intrinsic rewards. The approach delineates clear pathways for the development of robust, information-driven autonomous systems and offers solid groundwork for future extensions into semantic reasoning and dynamic scene adaptation.