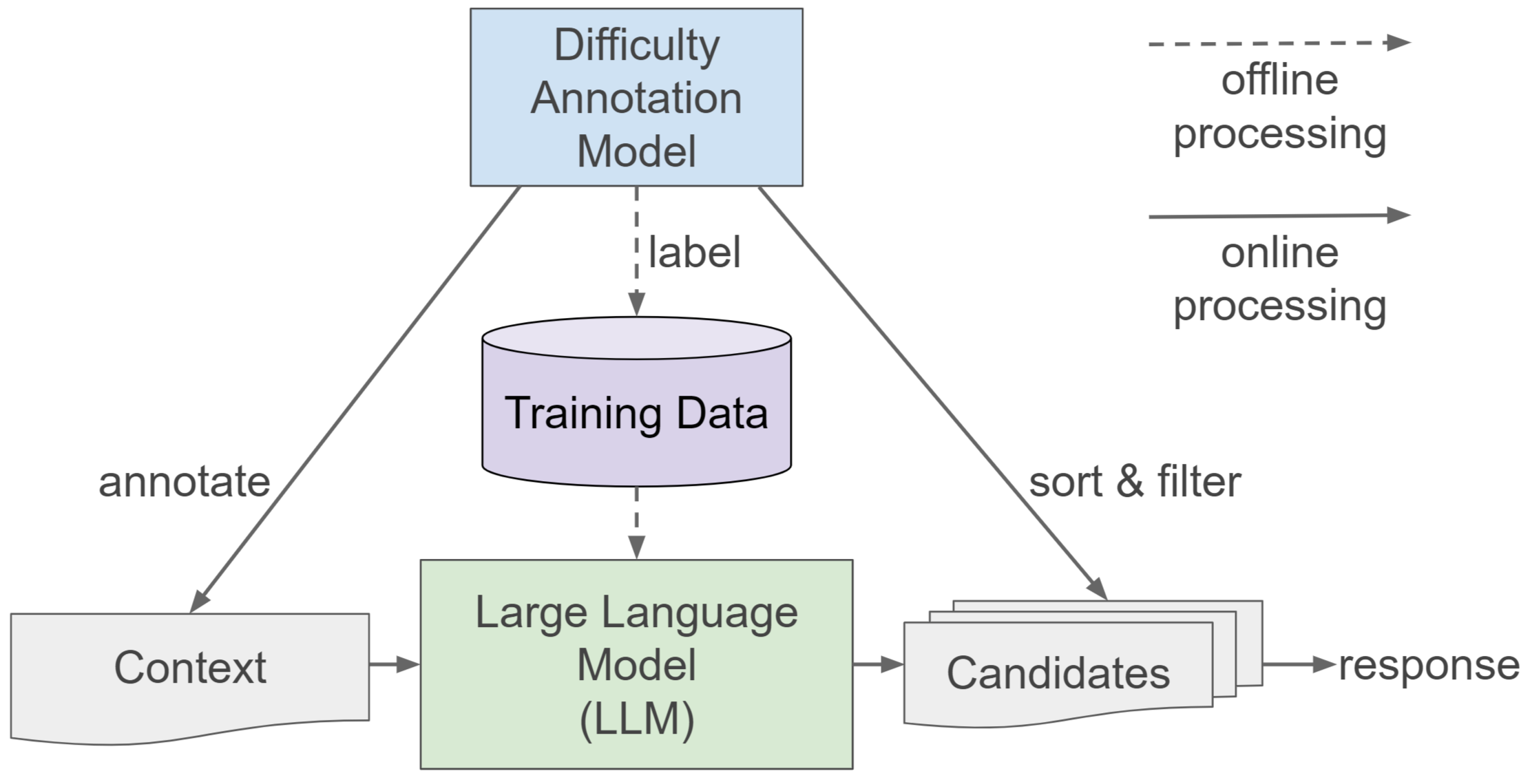
- The paper introduces Ace-CEFR, a novel dataset of conversational texts annotated with CEFR difficulty levels to calibrate language learning models.
- It compares linear regression, BERT, and PaLM 2-L models, with the BERT-based approach achieving an MSE of 0.37 against human ratings.
- Implications include enabling personalized language learning and advancing automated language assessment in latency-sensitive educational contexts.
Ace-CEFR Dataset for Evaluating Linguistic Difficulty in Conversational Texts
The "Ace-CEFR -- A Dataset for Automated Evaluation of the Linguistic Difficulty of Conversational Texts for LLM Applications" paper presents a novel dataset and evaluation framework designed to address the challenge of accurately assessing the linguistic difficulty of conversational texts. Such a capability is particularly crucial for the development and refinement of LLMs aimed at language education and proficiency assessment across diverse learner profiles.
Introduction to the Ace-CEFR Dataset
Ace-CEFR introduces a robust dataset of English conversational text passages, meticulously annotated with difficulty levels according to the CEFR scale—a standardized framework ranging from A1 (beginner) to C2 (proficiency). The development of this dataset responds to the pressing need for LLMs that can generate appropriately challenging language outputs tailored to individual learners. To effectively calibrate learning materials, particularly short conversational passages essential for language learning, the dataset offers a comprehensive foundation for training and evaluating machine learning models capable of estimating text difficulty with high precision.
Ace-CEFR distinguishes itself from existing datasets by focusing on short, colloquial passages typical of real-world conversations. The dataset comprises annotations gathered from experienced linguists and language teachers, ensuring its reliability and alignment with CEFR standards.
Methodology and Modeling Approaches
A variety of modeling approaches were implemented to evaluate the effectiveness of the Ace-CEFR dataset in predicting the difficulty of text passages. Three primary models were explored: a linear regression model, a BERT-based model, and a few-shot prompted PaLM 2-L model, each chosen for their unique strengths in handling text complexity.
Evaluations revealed that models trained with Ace-CEFR can predict text difficulty with an accuracy that challenges expert human assessments, demonstrated in Figure 2. The BERT-based approach, in particular, exhibits an MSE of 0.37 against human labeling, highlighting its robustness and applicability in latency-sensitive tasks.

Figure 2: Summary of mean squared error using the Ace-CEFR set to train difficulty prediction models, with 90% confidence intervals.
The implications of this dataset are far-reaching. It enhances the adaptability of LLMs in educational contexts, allowing for the creation of personalized and more effective learning experiences. Moreover, by offering a publicly available resource, the dataset facilitates ongoing research and development in automated language assessment tools.
Conclusion
Ace-CEFR represents a pivotal resource for the automated evaluation of text difficulty, particularly within conversational contexts. Through stringent evaluation and expert annotations, it enables the enhancement of educational technologies to better serve diverse learner needs. By providing this dataset to the public, the authors catalyze further research that could extend beyond English, exploring possibilities for other languages in multilingual instructional settings. Future research may explore cross-linguistic proficiency assessment, fine-tuning models with even richer datasets, and optimizing real-time applications for broader accessibility.