- The paper introduces a lagged KV eviction framework that leverages Token Importance Recurrence to reduce memory usage by 50-70%.
- It tracks recurrence intervals using an observation window to protect tokens predicted to regain attention, maintaining minimal accuracy loss.
- Empirical results on benchmarks like GSM8K and MATH500 confirm that LazyEviction enhances efficiency in large language models while retaining performance.
LazyEviction: Lagged KV Eviction for Efficient Long Reasoning
Introduction
The paper "LazyEviction: Lagged KV Eviction with Attention Pattern Observation for Efficient Long Reasoning" (2506.15969) addresses the increasing challenge of memory overhead in LLMs when handling extended reasoning sequences. As these models improve their reasoning capabilities with Chain-of-Thought (CoT) operations, the consequent elongation of reasoning tasks leads to substantial GPU memory usage due to the accumulation of key-value (KV) cache data. LazyEviction proposes a novel solution to this problem, emphasizing the preservation of crucial information throughout lengthy reasoning processes. The study introduces a lagged eviction framework that prioritizes token eviction based on observed recurring attention patterns, offering notable reductions in memory usage while maintaining task accuracy.
Key Concepts and Methodology
Token Importance Recurrence
One of the central observations in this paper is the phenomenon termed Token Importance Recurrence (TIR). This represents the tendency of certain tokens to regain high attention weights after several decoding steps, despite temporary reductions in importance. The paper empirically identifies this pattern, highlighting its significance in preserving tokens essential for ensuing reasoning phases, which existing methods often overlook.
LazyEviction Framework
LazyEviction distinguishes itself from conventional KV eviction methods through two main components:
- Recurrence Interval Tracking: It utilizes an Observation Window, assessing the Maximum Recurrence Interval (MRI) of each token’s significance over time. This tracking system allows the algorithm to retain tokens with latent future importance.
- MRI-Centric Eviction Policy: An innovative eviction strategy that uses the token’s historical attention recurrence to decide its retention. Tokens whose time since last importance exceeds their MRI are only considered for eviction, effectively safeguarding tokens that are predicted to become important in future decoding steps.
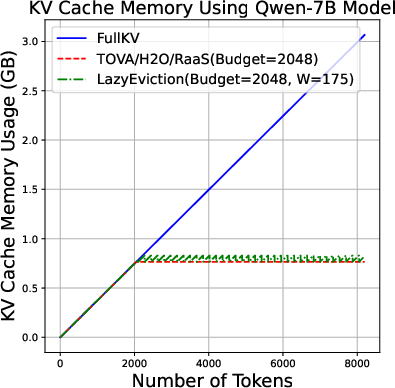
Figure 1: KV cache memory usage of different algorithms with varying output length (0-8k tokens).
Results and Comparison
Extensive experimentation showed LazyEviction’s efficiency across multiple datasets and model configurations, demonstrating memory reductions between 50% and 70% with negligible accuracy loss compared to FullKV setups. The algorithm outperformed existing KV cache compression baselines like H2O and TOVA in various reasoning benchmarks including GSM8K and MATH500, achieving almost identical performance to uncompressed models but with significantly reduced computational overhead.
Implications
The implications of LazyEviction extend both practically and theoretically. By integrating temporal attention patterns into eviction strategies, LazyEviction not only reduces hardware resource dependency but also aligns model efficiency with the dynamic nature of attention processes. Practically, this means substantial savings in memory usage and computational power, facilitating the deployment of LLMs in resource-constrained environments without sacrificing performance.
Conclusion
LazyEviction represents a significant advancement in LLM reasoning efficiency, particularly in contexts necessitating long inference sequences. By leveraging attention pattern observations, LazyEviction provides a robust mechanism for achieving substantial reductions in KV memory usage while maintaining high reasoning accuracy. Future exploration might focus on refining the adaptability of the model to various reasoning task structures and extending its application to broader contexts outside traditional reasoning sequences.