- The paper introduces a cache pruning strategy that evicts entire blocks of tokens to enhance memory efficiency during LLM inference.
- It employs a structured approach using L2 norm-based importance metrics within the vLLM framework without modifying CUDA kernels.
- Experimental results demonstrate high throughput and accuracy under varying cache budgets, outperforming traditional token-level methods.
PagedEviction: Structured Block-wise KV Cache Pruning for Efficient LLM Inference
Introduction
The paper "PagedEviction: Structured Block-wise KV Cache Pruning for Efficient LLM Inference" introduces an innovative method to optimize memory usage in the inference phase of LLMs by efficiently managing the Key-Value (KV) Cache. This approach addresses the memory bottleneck issue that arises as the KV cache size increases linearly with sequence length, often surpassing the memory used by the model weights themselves. The paper proposes PagedEviction, a cache pruning strategy compatible with vLLM's PagedAttention framework, allowing structured block-wise eviction without modifying CUDA kernels.
PagedEviction Architecture
PagedEviction utilizes a unique method to manage KV cache by evicting entire blocks of tokens, maintaining a structured memory layout that reduces fragmentation and facilitates efficient memory reuse. It operates in two phases: the prefill phase and the decode phase. During the prefill phase, the algorithm computes the importance of each token and evicts the least important ones prior to the segmentation of Key and Value tensors into blocks (Figure 1).
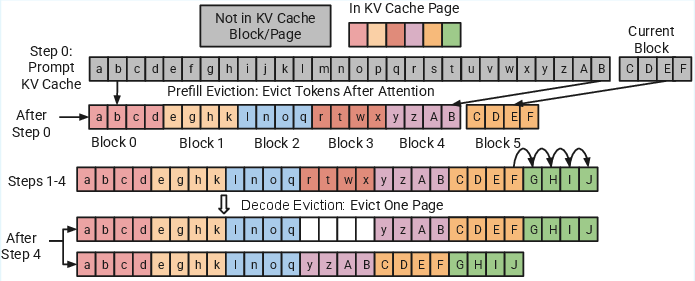
Figure 1: Illustration of the PagedEviction technique integrated into vLLM with a block size (B) and a cache budget (C). During the prefill stage, after the initial set of Key and Value tokens is generated, a subset of tokens is evicted until the cache budget is reached. In the decode phase, one block of tokens is evicted once the recent block becomes full.
In the decode phase, PagedEviction evicts one block of tokens per step only when a current block is full, thus preserving the structural consistency of the blocks (Figure 2).
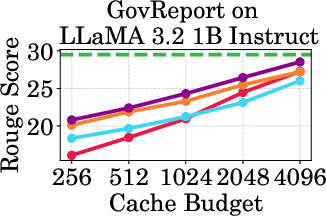
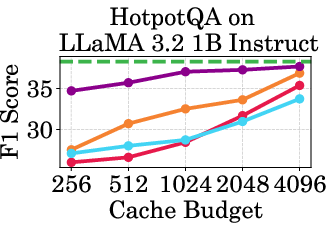
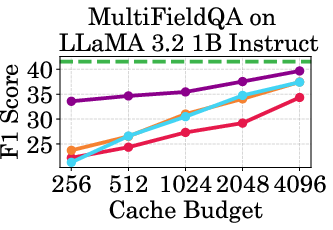
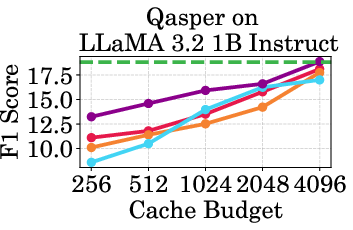
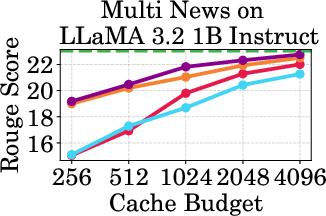
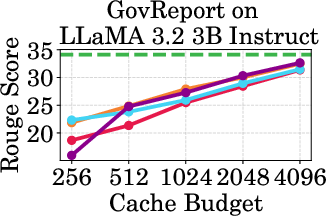
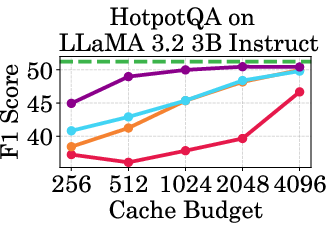
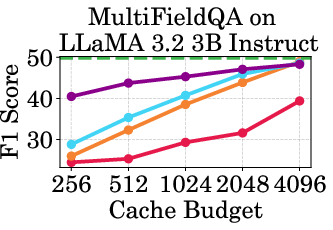
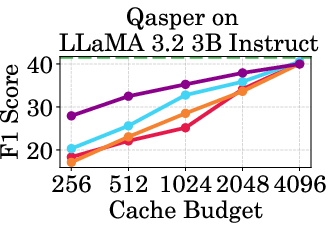
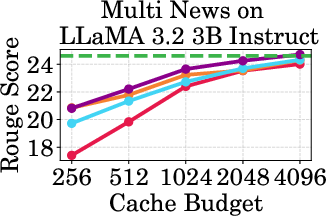
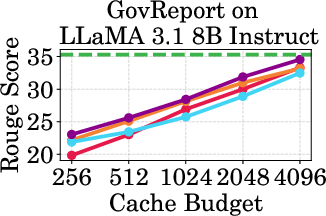
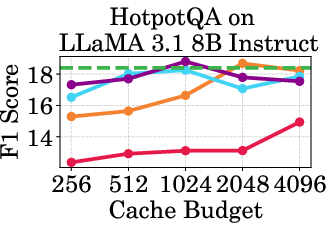
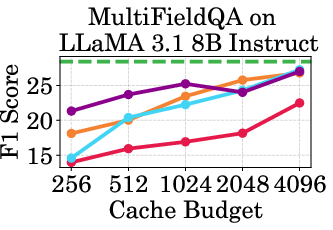
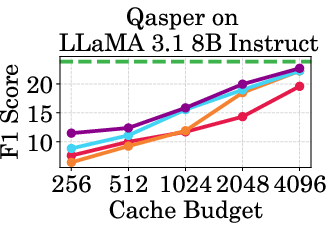
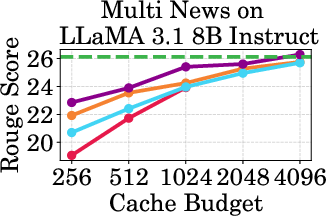
Figure 2: Accuracy vs Cache Budget of 1B, 3B, and 8B models on various datasets. PagedEviction consistently achieves higher or comparable accuracy relative to other attention-free baselines under low cache budgets (e.g., 256–1024) and closely approaches Full Cache performance at high budgets (2048–4096).
Implementation Considerations
PagedEviction integrates seamlessly with vLLM's PagedAttention through the innovative use of block-wise importance metrics. It relies on the ratio of the L2 norms of Value to Key tokens for computing importance, which avoids dependencies on attention scores that are not accessible in frameworks like FlashAttention. This approach makes it possible to implement PagedEviction without altering the CUDA attention kernels, ensuring high compatibility and ease of integration into existing systems.
PagedEviction's block-wise eviction methodology minimizes memory fragmentation and reduces runtime overhead, especially under batch inference. The strategy also simplifies KV cache management by eliminating token-level rearrangement across blocks, a feature particularly advantageous for large-scale LLM deployments.
Evaluation and Results
The evaluation of PagedEviction on LongBench datasets demonstrates superior memory efficiency and accuracy compared to various baselines such as StreamingLLM and KeyDiff. The approach achieves significantly higher throughput, evidenced by up to a 3020 tokens/sec rate on the LLaMA-1B model at a 1024-token cache budget, representing a substantial improvement over both Full Cache and other compression methods (Figure 3).
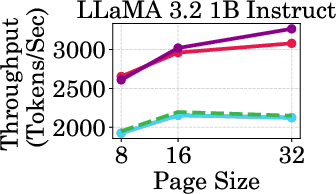
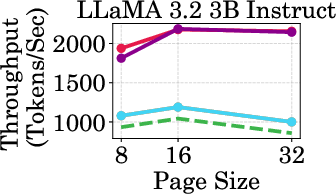
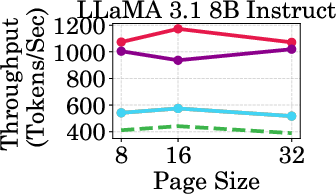
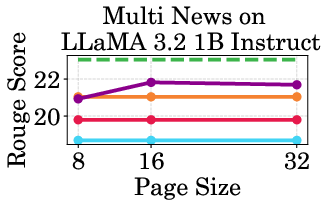
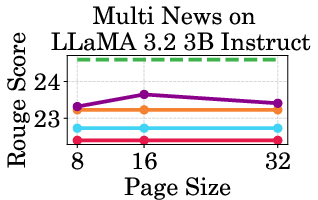
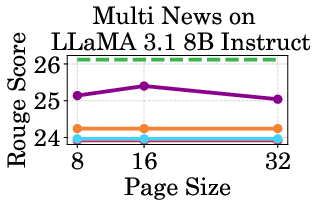
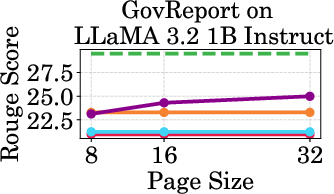
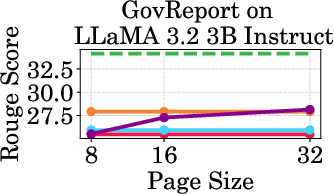
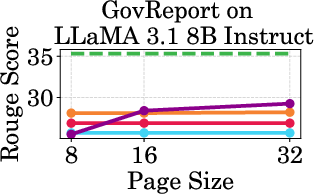
Figure 4: Throughput of LLaMA models under different cache budgets, highlighting PagedEviction's performance gains over baseline methods.
PagedEviction shows consistent performance across different models and datasets, maintaining high accuracy under low cache budgets while achieving close to full-cache performance under higher budgets. This reflects its strength in maximizing efficiency and scalability without compromising on model precision.
Conclusion
PagedEviction emerges as a robust solution for memory-efficient LLM inference, leveraging structured block-wise KV cache management to effectively reduce memory usage while retaining high model performance. Its compatibility with existing frameworks like vLLM and avoidance of kernel modifications position it as an ideal approach for deployment in large-scale, production-ready environments. Further extensions could explore integrating additional optimizations like layer-wise budgeting or quantization techniques, potentially enhancing its efficacy and application scope in various AI tasks.