KVzap: Fast, Adaptive, and Faithful KV Cache Pruning
Abstract: Growing context lengths in transformer-based LLMs have made the key-value (KV) cache a critical inference bottleneck. While many KV cache pruning methods have been proposed, they have not yet been adopted in major inference engines due to speed--accuracy trade-offs. We introduce KVzap, a fast, input-adaptive approximation of KVzip that works in both prefilling and decoding. On Qwen3-8B, Llama-3.1-8B-Instruct, and Qwen3-32B across long-context and reasoning tasks, KVzap achieves $2$--$4\times$ KV cache compression with negligible accuracy loss and achieves state-of-the-art performance on the KVpress leaderboard. Code and models are available at https://github.com/NVIDIA/kvpress.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces a new way to make LLMs run faster and use less memory without hurting their accuracy. It focuses on a part of LLMs called the “KV cache,” which stores information about past words so the model can refer back to them. As prompts get very long, this cache becomes huge and slows everything down. The authors present KVzap, a method that throws away the least useful pieces of this cache, keeping only what the model will likely need.
What questions the researchers asked
To make KV cache pruning practical, the authors asked:
- How can we prune the cache quickly so it doesn’t slow the model down?
- Can the same method work both when reading a long input (prefilling) and when generating a long answer (decoding)?
- Can it be compatible with popular, fast attention implementations used in real systems?
- Can we keep accuracy almost the same, even after pruning?
How the method works, in everyday terms
First, a quick background:
- Attention is the model’s way of “looking back” at earlier words to decide which ones matter for the next word.
- The KV cache is like a notebook full of “key” and “value” notes for each past token (word or piece of a word). The model flips through this notebook to find what’s relevant.
- Pruning is like decluttering that notebook: you keep the important notes and recycle the ones you won’t read again.
Past method (KVzip):
- KVzip scored which notes were important by making the model repeat the prompt and measuring how much it looked at each past token.
- It worked well but was slow and couldn’t be used while the model was generating an answer.
Improved scoring (KVzip+):
- The authors tweak KVzip’s scoring to better reflect how much each token actually changes the model’s internal state. Think of it as weighing both “how much attention a token gets” and “how strongly that token affects the result.”
KVzap (the new method):
- KVzap trains a tiny helper model (either a simple linear layer or a small two-layer network) that looks at the model’s hidden states—the internal “thoughts” at each position—and predicts how important each token’s KV pair will be.
- If the predicted importance is below a chosen cut-off (the threshold), KVzap removes that KV pair.
- It also keeps a short “sliding window” of the most recent tokens (for example, the last 128), because the model almost always needs the latest context.
- This helper is fast: it adds about 0.02%–1.1% extra compute per layer, which is negligible compared to the heavy cost of attention on very long contexts.
- Unlike fixed budgets (e.g., “always keep 50%”), KVzap’s threshold adapts to the input: complex prompts keep more notes; repetitive prompts keep fewer.
What they found and why it matters
Across multiple models (Qwen3-8B, Llama-3.1-8B-Instruct, Qwen3-32B) and tasks:
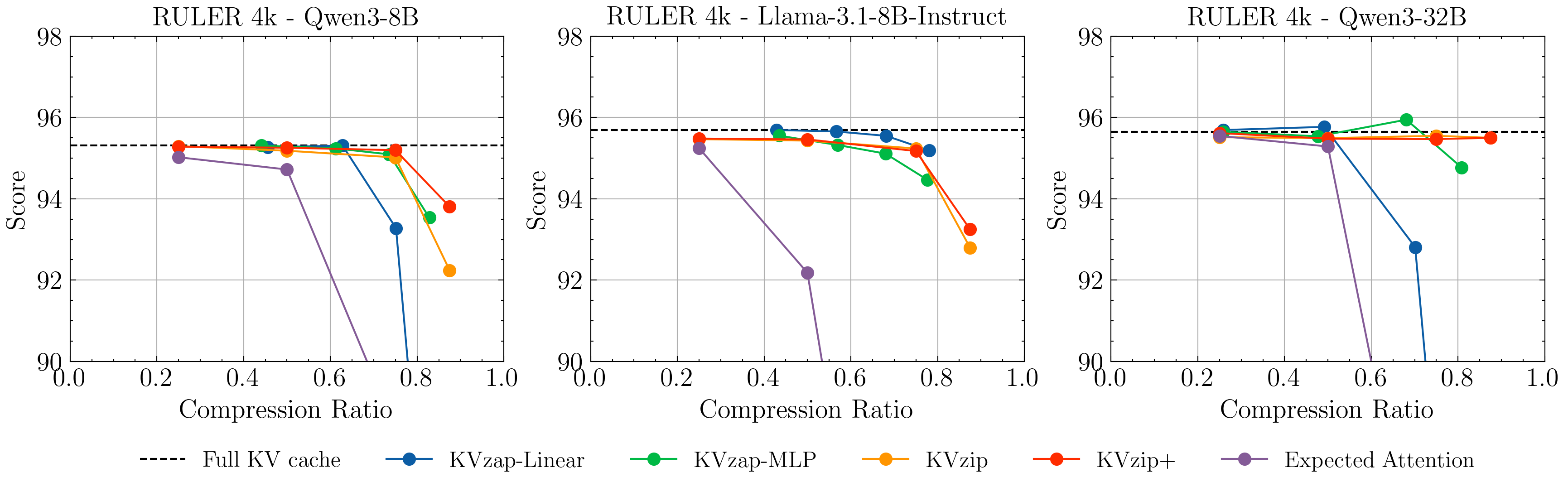
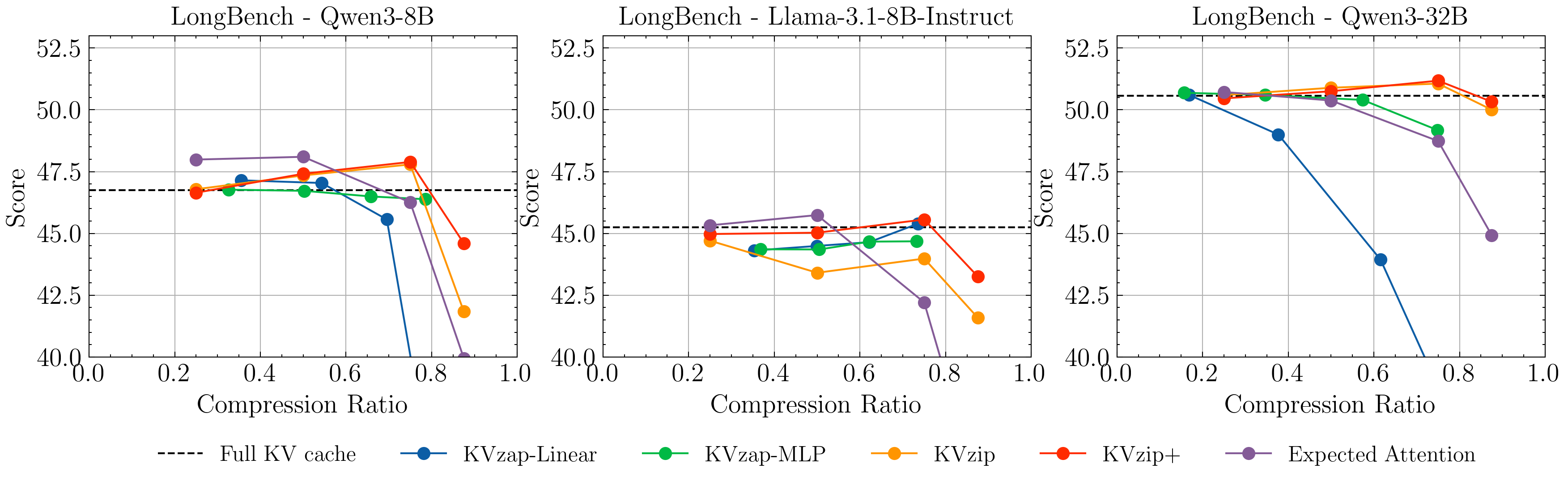
- KVzap compresses the KV cache by 2–4× while keeping accuracy almost the same.
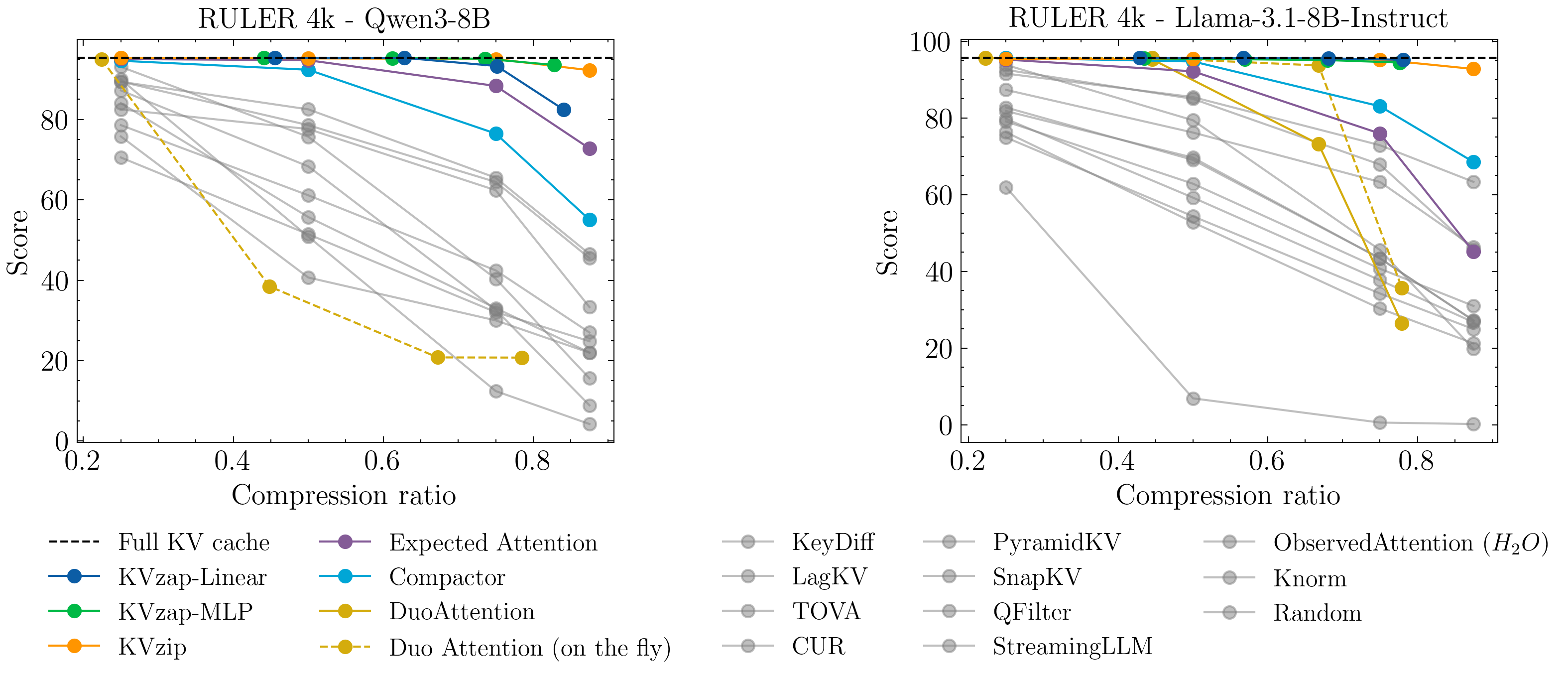
- It matches or beats competing pruning methods on standard long-context tests (RULER and LongBench).
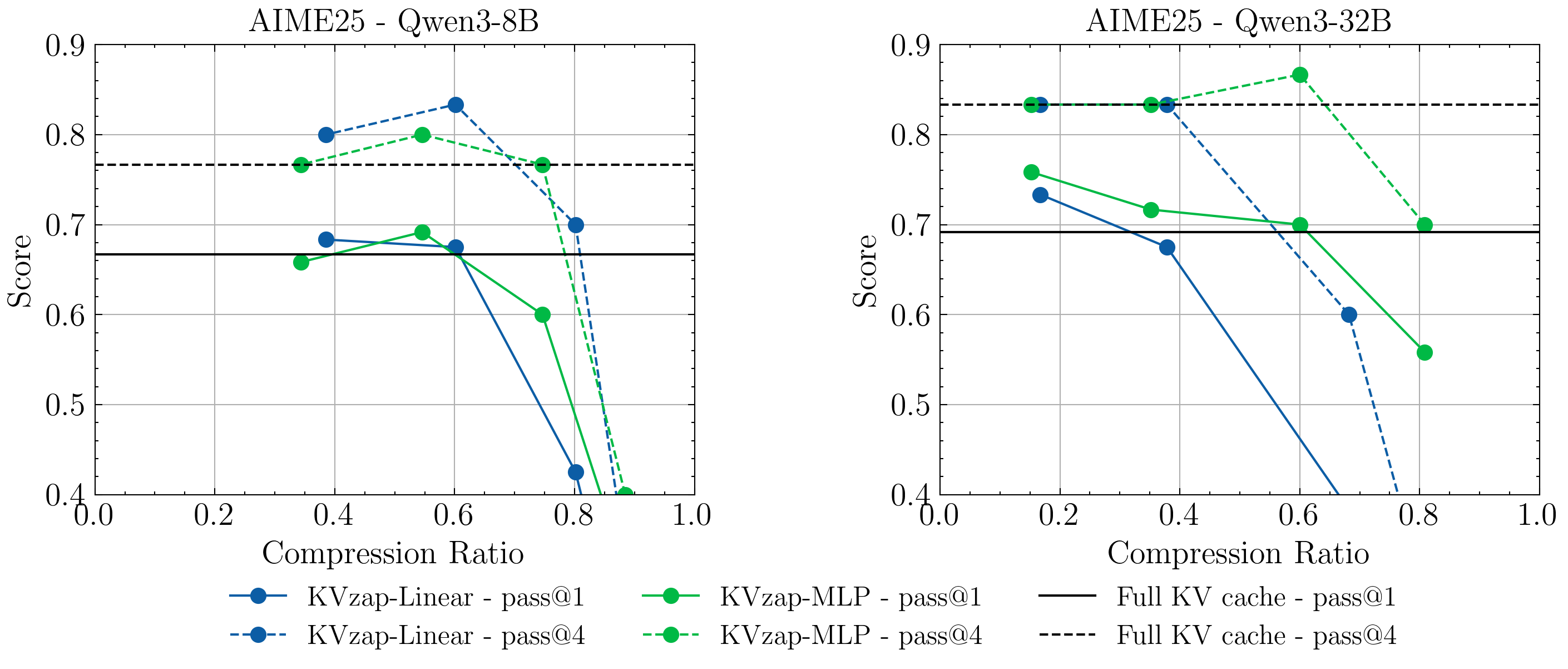
- It works in both phases: when reading long inputs and when generating long outputs, including math reasoning tasks like AIME25.
- The thresholds naturally adapt: the same cut-off gives different compression levels depending on how information-dense the data is.
- The overhead is tiny, and the method stays compatible with fast attention kernels used in popular inference engines.
- In short, KVzap is fast, adaptive, and faithful—it prunes a lot without breaking the model’s quality.
Why this is important and what comes next
Implications:
- Faster and cheaper LLM inference: Less memory used and fewer slowdowns mean you can handle longer conversations or documents on the same hardware.
- More practical long-context models: With pruning, models can handle tens of thousands of tokens more efficiently.
- Greener computing: Cutting wasted compute and memory reduces energy use.
What’s still ahead:
- Engineering work to turn compression into real, measured speedups in production systems.
- Testing on larger models and more kinds of tasks, especially those using sparse attention.
- Exploring end-to-end training so models learn to prune during training, which might push performance even further.
Bottom line: KVzap shows that LLMs don’t need to keep every past token in memory. With a smart, tiny helper model and an adaptive threshold, you can safely declutter the KV cache, make models run faster, and keep their answers just as accurate.
Knowledge Gaps
Below is a concise, action-oriented list of the knowledge gaps, limitations, and open questions left unresolved by the paper. Each item is framed so it can guide concrete follow-up work.
- Scaling and architectural generalization: validate KVzap on larger (≥70B/235B) dense models, MoE architectures, MLA-style low-rank KV (e.g., DeepSeek V2), sparse/hybrid attention (e.g., DeepSeek V3.2), and hybrid Transformer–SSM models.
- Real integration and speedups: demonstrate end-to-end integration in production engines (vLLM, SGLang, TRT-LLM) with kernel support for variable per-head cache lengths; report wall-clock latency/throughput gains, GPU memory savings, and allocator behavior.
- Kernel compatibility in practice: empirically evaluate compatibility and performance with FlashAttention2 and PagedAttention (beyond claims), including paging, fragmentation, preemption, and heterogeneous head lengths.
- Pre-attention pruning: assess pruning before attention to accelerate prefilling (not just post-attention eviction), including correctness and speed trade-offs.
- Threshold selection and control: develop automatic, per-input calibration to meet target memory/latency budgets or target accuracy, rather than relying on fixed global τ; explore per-layer/head adaptive thresholds.
- Budget predictability: characterize and control variability of compression ratios under fixed τ for service-level capacity planning; design mechanisms to hit a specified budget deterministically.
- Training-label cost and alternatives: reduce reliance on expensive KVzip+ labels; evaluate cheaper supervision (e.g., Expected Attention approximations, self-supervised proxies) or weak-to-strong distillation.
- Theoretical guarantees: derive bounds on loss, perplexity, or attention approximation error under KVzap thresholding; characterize worst-case pruning risk.
- Ultra-long context regimes: rigorously evaluate at 64k–128k tokens on real tasks (not only RULER-4k/16k) and analyze failure modes at extreme lengths.
- Distribution shift and robustness: test robustness to domain shifts, adversarial prompts, dense code/math, multilingual scripts, and noisy inputs; quantify degradation and propose safeguards.
- Transferability across models: study whether a surrogate trained on one model (or size) transfers to related checkpoints (e.g., fine-tunes, instruction-tuned variants) or requires per-model retraining.
- Joint modeling across layers/heads: move beyond independent per-layer surrogates; test multi-layer or cross-head models that capture inter-head dependencies and global context signals.
- Positional information: address positional information gaps observed (need for sliding window) via explicit positional features, rotary-phase inputs, or concatenating shallow features from earlier layers.
- Interaction with quantization/pruning: measure effects under KV/weight quantization (int8, fp8, NF4), structured sparsity, and head-pruning; assess compounded errors and optimal ordering.
- Decoding behaviors: evaluate with beam search, diverse sampling temperatures, speculative decoding, and multi-token prediction; quantify interactions and compatibility.
- Streaming and multi-turn chat: study long-running, multi-turn sessions with interleaved user/assistant turns, including re-reference to early context and potential regressions over time.
- Safety and factuality: measure impacts on hallucination rates, calibration, toxicity/safety filters, and factual QA beyond benchmark accuracy.
- Fine-grained error analysis: identify which token types (entities, numerals, delimiters, code markers) are disproportionately pruned and link to task-specific failures.
- Statistical rigor: report confidence intervals, multiple seeds, and significance tests; analyze variance across subsets (e.g., small LongBench subsets) to separate noise from effect.
- Surrogate capacity/search: explore richer architectures (e.g., per-head adapters, low-rank plus gating, small cross-layer attention) and hyperparameter tuning beyond MLP width D_h/8.
- Online adaptation: investigate continual/online learning of surrogates and thresholds during deployment to adapt to domains/users without catastrophic drift.
- Eviction scheduling correctness: formalize and test the decoding-time score buffering and eviction timing, ensuring determinism and no cross-step inconsistencies.
- Compositional compression: systematically combine T-axis pruning with H/D/L-axis techniques (GQA, MLA, sliding-window layers) and with retrieval/sparse attention; quantify additive vs interfering effects.
- Memory fragmentation: analyze page/block fragmentation and utilization under non-uniform head-wise cache lengths; propose allocator/pager strategies to mitigate waste.
- Training cost and footprint: report compute/energy cost to generate KVzip+ labels and train per-model surrogates; develop efficient pipelines to scale across many models/versions.
- Rare long-range dependencies: design detection/safeguards for low-score but critical tokens (e.g., anchors for multi-hop reasoning), possibly via uncertainty thresholds or canary rules.
- Structured outputs and tool use: evaluate on function-calling, JSON/XML-constrained generation, code completion/execution, and tool-use pipelines where pruning errors can be catastrophic.
- Encoder–decoder and non-autoregressive settings: test applicability to seq2seq models (e.g., translation, summarization) and NAR/CTC/latent-variable decoders with different KV access patterns.
Practical Applications
Immediate Applications
Below are concrete, deployable uses that leverage KVzap’s input-adaptive KV cache pruning (2–4× compression with negligible accuracy loss) and its compatibility with both prefilling and decoding. Each item lists potential tools/workflows and key assumptions/dependencies that may affect feasibility.
- Industry — LLM inference serving cost and capacity gains
- Application: Reduce GPU memory footprint and increase batch size/throughput for production LLM endpoints without retraining base models.
- Sectors: Software, cloud/infra, enterprise IT, AI platforms.
- Tools/workflows:
- Integrate KVzap from the kvpress repo into serving stacks (vLLM/SGLang/TRT-LLM plugins or forks).
- Autoscaling “τ auto-tuner” to target memory/latency SLAs.
- “KVzap Dashboard” to monitor compression ratio vs. quality regressions; shadow A/B evaluation pipelines.
- Assumptions/dependencies: Requires kernel support for variable-length KV (PagedAttention variants) to convert memory savings into wall-clock speedups; per-model surrogate availability (currently Qwen3/Llama-3.1-8B); τ needs workload-specific tuning.
- Industry — Long-context RAG and analytics at lower cost
- Application: Serve longer prompts (contracts, filings, manuals) and multi-doc QA with less memory, improving hit rates and reducing truncation.
- Sectors: Legal, finance, enterprise search, compliance, customer support.
- Tools/workflows:
- RAG pipelines with KVzap-enabled prefilling; preset τ profiles by corpus type (synthetic vs. real-world).
- Contract/eDiscovery platforms enabling 128k+ token contexts on fewer/cheaper GPUs.
- Assumptions/dependencies: Quality depends on data density (e.g., LongBench is harder than RULER); sliding window w must preserve recent locality (w≈128 recommended).
- Industry — Reasoning-intensive assistants with long outputs
- Application: Maintain reasoning quality while pruning during decoding (math/code CoT, report drafting).
- Sectors: Software engineering, data science, operations, knowledge work.
- Tools/workflows:
- τ schedulers that decrease pruning late in generation or around tool-use steps.
- Guardrails to disable pruning for safety-critical spans.
- Assumptions/dependencies: Some tasks are more sensitive at very high compression; deploy per-task τ caps and health checks.
- Industry — Code intelligence on large repositories
- Application: IDE and CI assistants can hold more files and history in context without upgrading hardware.
- Sectors: Software engineering, DevOps.
- Tools/workflows:
- Repo-aware “adaptive τ” based on file redundancy/duplication; sliding window for recent edits.
- CI quality gates that compare pruned vs. full-KV outputs on golden tasks.
- Assumptions/dependencies: Mixed-language/codebases may alter optimal τ; monitor subset-specific regressions.
- Healthcare — Long EHR summarization and longitudinal chart review
- Application: Summarize patient histories spanning years while running on constrained hospital GPUs.
- Tools/workflows:
- KVzap-enabled clinical summarization services; τ presets for narrative vs. tabular EHR notes.
- Assumptions/dependencies: Requires thorough validation for clinical safety; PHI kept on-prem; domain shift from training data.
- Finance — Earnings calls, filings, and compliance scanning
- Application: Longer multi-document context for risk analysis and compliance checks at lower serving cost.
- Tools/workflows:
- Batch inference with higher concurrency using freed KV memory.
- τ tied to document redundancy (e.g., repetitive filings).
- Assumptions/dependencies: Legal/audit teams may require audit logs showing compression ratios and any accuracy effects.
- Education — Essay grading and long-history tutoring
- Application: Ingest entire course histories, large essays, and project reports with smaller memory budgets.
- Tools/workflows:
- LMS plugins with KVzap-enabled long-context grading; “per-lesson τ” templates.
- Assumptions/dependencies: Maintain grading rubrics and reference answers for periodic quality audits.
- Daily life — On-device and edge assistants with longer memory
- Application: Offline summarization, note-taking, and personal assistants on laptops/handhelds with limited VRAM.
- Tools/workflows:
- KVzap added to llama.cpp/MLC forks; prebuilt surrogate packages per model.
- Assumptions/dependencies: Mobile kernels must support variable KV; battery/thermal constraints; smaller models benefit most.
- Cross-cutting — Observability, safety, and governance overlays
- Application: Ensure pruning stays “faithful” in production.
- Tools/workflows:
- Compression-aware logging, fail-open policies when anomaly detectors trigger (e.g., sudden accuracy/latency shifts).
- Assumptions/dependencies: Requires data flywheels (canaries, golden sets); minor engineering to wire τ and telemetry.
Long-Term Applications
These opportunities depend on further research, scaling, kernel optimization, and broader ecosystem support.
- Industry/Infra — Kernel and hardware co-design for pruned-KV serving
- Application: Flash/PagedAttention variants with first-class support for non-uniform KV lengths and variable blocks; memory allocators optimized for sparse T-axis.
- Sectors: Cloud, GPU/accelerator vendors, inference engines.
- Tools/products:
- “PagedAttention-VarLen” kernels; memory-compaction schedulers; CUDA/Triton kernels exploiting idle FLOPs during KV fetch.
- Assumptions/dependencies: Vendor cooperation; rigorous benchmarks to demonstrate wall-clock gains beyond memory savings.
- Modeling — End-to-end, pruning-aware training
- Application: Train models with integrated pruning objectives (KVzap-like signals or DMS-style losses) for better retention policies and stability.
- Sectors: Foundation model labs, academia.
- Tools/products:
- Training libraries to distill KVzip+/KVzap signals; curriculum schedules for pruning during pretraining/finetuning.
- Assumptions/dependencies: Requires large-scale training resources; measure broader-task generalization and safety.
- Tools — AutoML for surrogate training and τ controllers
- Application: One-click generation of per-layer surrogates for any base model and automated τ selection by dataset/task.
- Sectors: MLOps, platform engineering.
- Tools/products:
- “KVzap Studio”: data selection, surrogate search, and τ auto-tuning to a target quality/latency envelope.
- Assumptions/dependencies: High-quality diverse training data; guard against domain shift.
- Robotics/Edge — Longer-horizon planning and dialogue on resource-constrained hardware
- Application: Keep more situational context and instruction history on onboard compute.
- Sectors: Robotics, IoT, automotive.
- Tools/products:
- KVzap-optimized agent stacks; safety envelopes that relax pruning around critical control tokens.
- Assumptions/dependencies: Real-time constraints; strong safety validation and fallback modes.
- Knowledge-intensive domains — Million-token class applications
- Application: E-discovery, litigation support, scientific systematic reviews, and software monorepo assistants with near “whole-corpus” contexts.
- Sectors: Legal, science/biomed, software.
- Tools/products:
- Hybrid sparse retrieval + KVzap pruning; progressive τ schedules across stages of analysis.
- Assumptions/dependencies: Additional scaling research; careful evaluation on real corpora to avoid subtle regressions.
- Multi-agent systems — Shared KV memory pooling
- Application: Pool pruned KV across agents for collaboration while staying within memory budgets.
- Sectors: Agent platforms, orchestration frameworks.
- Tools/products:
- KV-aware schedulers that allocate memory by agent/task importance; cross-agent KV reuse primitives.
- Assumptions/dependencies: Security isolation and leakage prevention; kernel/engine support for shared pools.
- Sustainability and policy — Emissions-aware serving standards
- Application: Encourage or mandate memory/energy-efficient inference (e.g., KV pruning) in public procurement and reporting.
- Sectors: Public sector, ESG/compliance.
- Tools/products:
- “Green Inference” badges; carbon dashboards attributing savings to pruning.
- Assumptions/dependencies: Transparent, auditable metrics; sector-specific accuracy thresholds.
- Safety and compliance certification for pruned inference
- Application: Standardized testing that certifies pruning-safe operation for regulated settings (healthcare, finance, public services).
- Tools/products:
- Test suites covering rare but critical failure modes; policy packs that pin τ and sliding-window parameters.
- Assumptions/dependencies: Community-agreed benchmarks; legal acceptance of pruning as a non-material modification.
- Productization — Memory-efficient long-context LLM SKUs
- Application: Offer “KVzap-enabled” model endpoints with guaranteed 2–4× memory compression and quality SLAs.
- Sectors: Cloud providers, AI API vendors.
- Tools/products:
- Tiered pricing by τ/quality; knobs for customers to trade accuracy for cost/latency.
- Assumptions/dependencies: Mature kernel support and robust observability to enforce SLAs across workloads.
Glossary
- AdaKV: A KV cache pruning method that adaptively allocates pruning budgets across heads or layers. "whether per-head or per-layer (AdaKV, \citep{adakv})."
- AIME25: A reasoning benchmark of 30 Olympiad-level, integer-answer math problems. "The AIME25 benchmark \citep{aime25} consists of 30 Olympiad-level, integer-answer problems from the 2025 American Invitational Mathematics Examination."
- Autoregressive generation: Token-by-token generation where each new token conditions on previously generated tokens. "reused during autoregressive generation."
- bfloat16: A 16-bit floating-point format with an 8-bit exponent, commonly used for efficient training/inference. "For example, in bfloat16 precision, the KV cache for a vanilla transformer like Llama1-65B \citep{llama1} (, , ) requires 335~GB of memory at k."
- Compactor: A KV cache compression method based on approximate leverage scores. "including Expected Attention \citep{expected_attention}, Duo Attention \citep{duoattention}, and Compactor \citep{compactor}."
- Copy-and-paste pretext task: An auxiliary task that repeats the prompt to score token importance for pruning. "KVzip relies on a copy-and-paste pretext task to score the most important KV pairs."
- Decoding: The generation phase that produces output tokens, often after building the cache during prefilling. "Second, it cannot be used during decoding, which makes it unsuitable for reasoning tasks that generate thousands of tokens."
- Duo Attention: A long-context inference method combining retrieval and streaming attention heads. "including Expected Attention \citep{expected_attention}, Duo Attention \citep{duoattention}, and Compactor \citep{compactor}."
- Eviction policy: The strategy for deciding which KV entries to remove from the cache. "Another key difference lies in the eviction policy."
- Expected Attention: A pruning approach estimating attention from future query distributions to guide KV cache compression. "We enhance the KVzip scoring with a normalization term inspired by \citep{expected_attention}, creating KVzip+."
- Feed-forward network (FFN): The MLP sublayer within transformer blocks applied after attention. "and the feed-forward network (FFN)."
- FlashAttention2: An optimized attention kernel improving speed and memory efficiency for transformers. "compatible with kernels like FlashAttention2 \citep{flashattention2} or PagedAttention \citep{pagedattention}"
- Greedy decoding: A deterministic decoding strategy selecting the highest-probability token at each step. "For RULER and LongBench, we used greedy decoding and disabled reasoning"
- Grouped Query Attention (GQA): An attention variant sharing keys/values across multiple queries to reduce KV cache size. "Grouped Query Attention (GQA, \citep{gqa}) shares keys and values across multiple queries, yielding KV cache compression factors of 4× ..."
- Hidden state: The internal per-token representation produced within each model layer. "to predict scores directly from the input hidden states "
- KV cache: The stored keys and values across sequence positions used to speed up attention during inference. "Growing context lengths in transformer-based LLMs have made the key-value (KV) cache a critical inference bottleneck."
- KV pair: The key and value vectors associated with a token and head that are stored in the KV cache. "discarding KV pairs whose predicted score falls below a fixed threshold ."
- KVzap: The paper’s proposed fast, input-adaptive KV cache pruning method using surrogate models over hidden states. "we introduce KVzap, a new KV cache pruning technique which applies these surrogate models to the hidden states to prune KV pairs below a fixed threshold ."
- KVzip: A query-agnostic KV cache compression method that scores importance via a copy-and-paste pretext task. "KVzip \citep{kvzip} currently stands as the state-of-the-art KV cache pruning method"
- KVzip+: An enhanced version of KVzip scoring that normalizes contributions using output-projected values and hidden-state norms. "We enhance the KVzip scoring with a normalization term inspired by \citep{expected_attention}, creating KVzip+."
- LongBench: A multilingual, multitask benchmark suite for evaluating long-context understanding. "LongBench \citep{longbench} evaluates long-context capabilities across six task categories—single-document QA, multi-document QA, summarization, few-shot learning, synthetic tasks, and code completion—spanning 21 subsets in English and Chinese."
- Memory-bandwidth bound: A regime where performance is limited by memory transfer rather than compute. "during decoding— which is strictly memory-bandwidth bound—KVzap’s additional FLOPs effectively utilize idle GPU cycles"
- Multi-head Latent Attention (MLA): An attention mechanism that performs a low-rank decomposition of keys and values to reduce dimensionality. "DeepSeek V2 \citep{deepseekv2} introduces Multi-head Latent Attention (MLA) to perform a low-rank decomposition of keys and values"
- Output projection matrix (W_O): The matrix that maps concatenated head outputs back to the model’s hidden dimension. "where is the input hidden state, the output hidden state, the output projection matrix, and the value vector."
- PagedAttention: A memory management approach and kernel for serving LLMs that handles paged KV cache blocks efficiently. "requiring PagedAttention kernels \citep{pagedattention} that handle variable-length blocks."
- Pass@k: A metric indicating whether at least one of k sampled generations solves a task. "Comparison of pass@1 (solid lines) and pass@4 (dashed lines)"
- Prefilling: The phase where the input prompt is processed to populate the KV cache before generation. "Phase-agnostic. The method must apply to both prefilling (long context) and decoding (reasoning tasks)."
- Quadratic attention cost: The O(T2) computational scaling of full attention with sequence length T. "in long-context regimes the quadratic attention cost dominates"
- Residual stream: The main representation pathway updated by adding attention and FFN outputs to the input hidden state. "represents token 's contribution to the residual stream ."
- RULER: A long-context benchmark evaluating retrieval, reasoning, and aggregation across varying context lengths. "RULER \citep{ruler} evaluates long-context capabilities across four task categories—retrieval, multi-hop tracing, aggregation, and question answering—over 13 subsets with sequence lengths ranging from 4k to 128k."
- Sliding window: A fixed-size recent-token buffer retained unpruned to preserve local context. "we keep a sliding window of the most recent tokens"
- Sliding window attention: An attention pattern restricted to a moving window to reduce memory/computation. "interleave attention layers with sliding window attention (2× compression for GPT-OSS-120B \citep{gptoss}, 6× for Gemma3 \citep{gemma3})"
- Sparse attention: Attention mechanisms that compute attention over a subset of past tokens to reduce compute or improve throughput. "Sparse attention mechanisms, such as DSA in DeepSeek V3.2 \citep{DeepSeekV32}, retrieve only the most relevant KV pairs at each decoding step"
- State space models: Sequence models with linear-time recurrence that can replace some attention layers in hybrids. "or state space models (8× compression for Jamba \citep{jamba}, 4× compression for Kimi-Linear \citep{kimilinear}, 4.8× for Nemotron3 Nano \citep{nemotron3})."
- StreamingLLM: A technique for streaming inference that stabilizes attention via attention sinks. "following StreamingLLM \citep{streamingllm}"
- Surrogate model: A lightweight predictive model trained to approximate a more expensive scoring or decision rule. "We demonstrate that KVzip+ scores can be approximated by a lightweight surrogate model trained on top of the model's hidden states."
- SwiGLU: A gated activation function (Swish-Gated Linear Unit) commonly used in transformer FFNs. "and a SwiGLU FFN intermediate dimension $D_{\text{int}$, the FLOPs from linear projections are:"
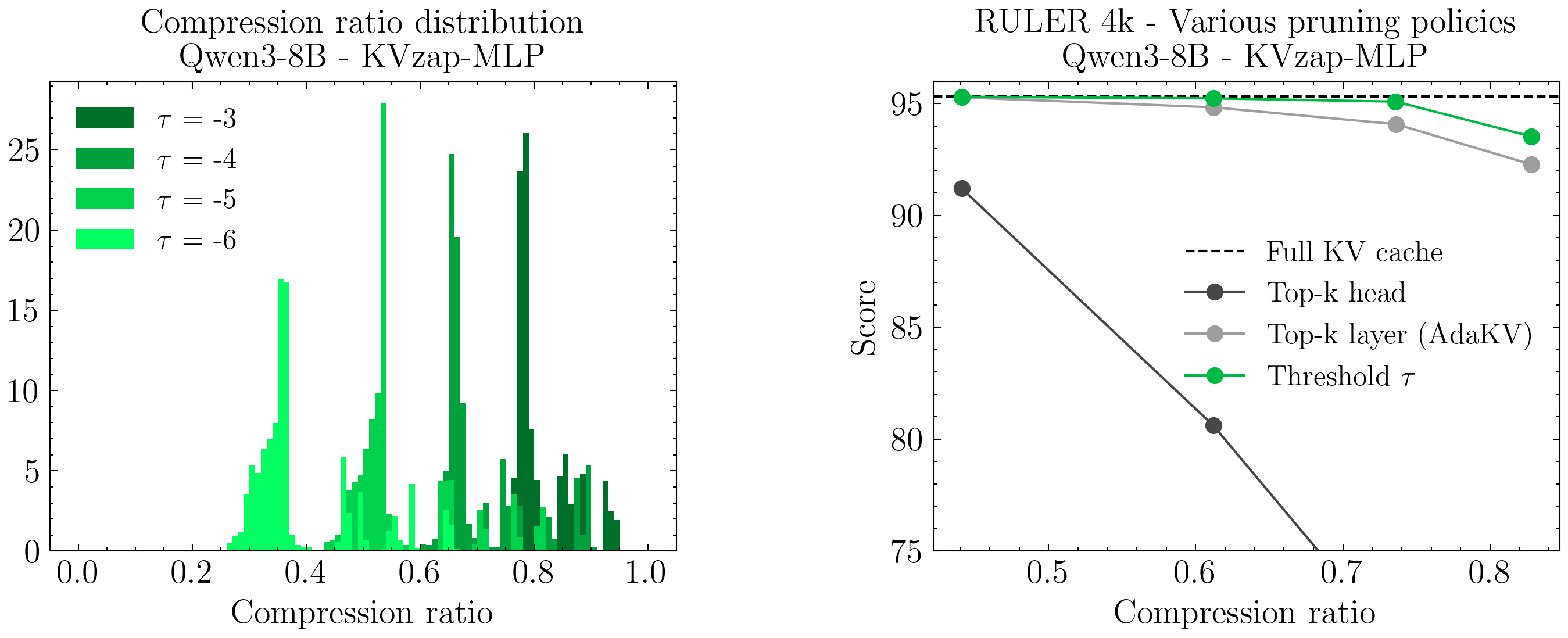
- Thresholding: A pruning approach that removes items whose score falls below a set threshold rather than keeping a fixed quota. "KVzap uses thresholding, discarding KV pairs whose predicted score falls below a fixed threshold ."
- Time to first token: The latency before a model produces its first output token. "increasing GPU peak memory usage and time to first token while reducing decoding throughput."
- Top-k selection: Selecting the k highest-scoring tokens/items according to a model or heuristic. "thresholding outperforms fixed-ratio top- selection, whether per-head or per-layer (AdaKV, \citep{adakv})."
- Top-p sampling: Nucleus sampling that draws from the smallest set of tokens whose cumulative probability exceeds p. "(, top-, top-)"
Collections
Sign up for free to add this paper to one or more collections.