Cache What Lasts: Token Retention for Memory-Bounded KV Cache in LLMs
Abstract: Memory and computation remain core bottlenecks in long-horizon LLM inference due to the quadratic cost of self-attention and the ever-growing key-value (KV) cache. Existing strategies for memory-bounded inference, such as quantization, offloading, or heuristic KV eviction, either incur high orchestration costs or rely on unreliable attention-based proxies of importance. We propose TRIM-KV, a novel approach that learns each token's intrinsic importance at creation time via a lightweight retention gate. Each gate predicts a scalar retention score that decays over time, reflecting the long-term utility of the token for a specific layer and head. Tokens with low scores are evicted when the memory budget is exceeded, ensuring that the cache always contains the most critical tokens. TRIM-KV is trained efficiently through distillation from a frozen LLM combined with a capacity loss, requiring only gate fine-tuning and adding negligible inference overhead. Across mathematical reasoning (GSM8K, MATH-500, AIME24), procedural generation (LongProc), conversational long-memory benchmarks (LongMemEval), and long-context understanding (LongBench and SCBench), TRIM-KV consistently outperforms strong eviction and learnable retrieval baselines, especially in low-memory regimes. Remarkably, it even surpasses full-cache models in some settings, showing that selective retention can serve as a form of regularization, suppressing noise from uninformative tokens. Qualitative analyses further reveal that learned retention scores align with human intuition, naturally recovering heuristics such as sink tokens, sliding windows, and gist compression without explicit design. Beyond efficiency, retention scores provide insights into layer- and head-specific roles, suggesting a new path toward LLM interpretability.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way to help LLMs handle very long conversations or documents without running out of memory. The idea, called TRIM-KV, teaches the model to decide which past words or tokens are truly important to keep and which can be safely forgotten. This lets the model work well even when it has a strict memory limit.
What questions does the paper ask?
- How can an LLM keep working well when it can only store a limited number of past tokens (memory slots)?
- Can the model learn, in advance, which tokens will be useful later, instead of only looking at what it paid attention to recently?
- Will this learned “keep-or-drop” strategy be fast, simple to use, and actually improve results on tough tasks?
How does the method work?
The problem: limited memory in LLMs
When an LLM reads or writes text, it stores summaries of past tokens (called a “KV cache”) so it can reuse them. But the more it reads, the more memory this cache needs. If the cache gets too big, the model slows down or runs out of space.
Think of the KV cache like a backpack with limited slots. As you keep walking (generating text), you add new items (tokens). If the backpack is full, you must decide which old item to remove to make room.
The idea: a “retention gate” and fading importance
TRIM-KV adds a tiny “retention gate” to each layer and head inside the model. When a token is created, this gate gives it a score between 0 and 1 that says how important it is to keep. Over time, this score slowly fades—like ink that gets lighter as time passes. Important tokens fade slowly; unimportant ones fade quickly.
When the backpack (KV cache) is full, the system removes the token with the lowest current score. This way, the cache always keeps the most useful tokens for the long run, with a natural preference for newer important tokens.
This fading score is inspired by how human memory works: we forget some things over time unless they’re strong or important.
Training the gates: learning from a teacher and a budget
To teach the retention gates how to score tokens well, the authors:
- Use a frozen, original LLM as a “teacher” and train the gates so the new model’s outputs look like the teacher’s. This is called distillation.
- Add a “capacity loss” that acts like a strict budget reminder. If the model tries to keep too many tokens, it gets penalized. This encourages smart pruning.
Importantly, only the small gate networks are trained; the main LLM stays unchanged. This keeps training fast and simple.
Using it during inference: simple, fast eviction
At run time, the model:
- Assigns a retention score to each new token.
- If the cache exceeds the memory limit, it evicts the token with the smallest current score.
- Attention computation proceeds normally, with minimal extra cost.
This is much simpler than methods that move data between CPU and GPU or search through big caches.
What did they find?
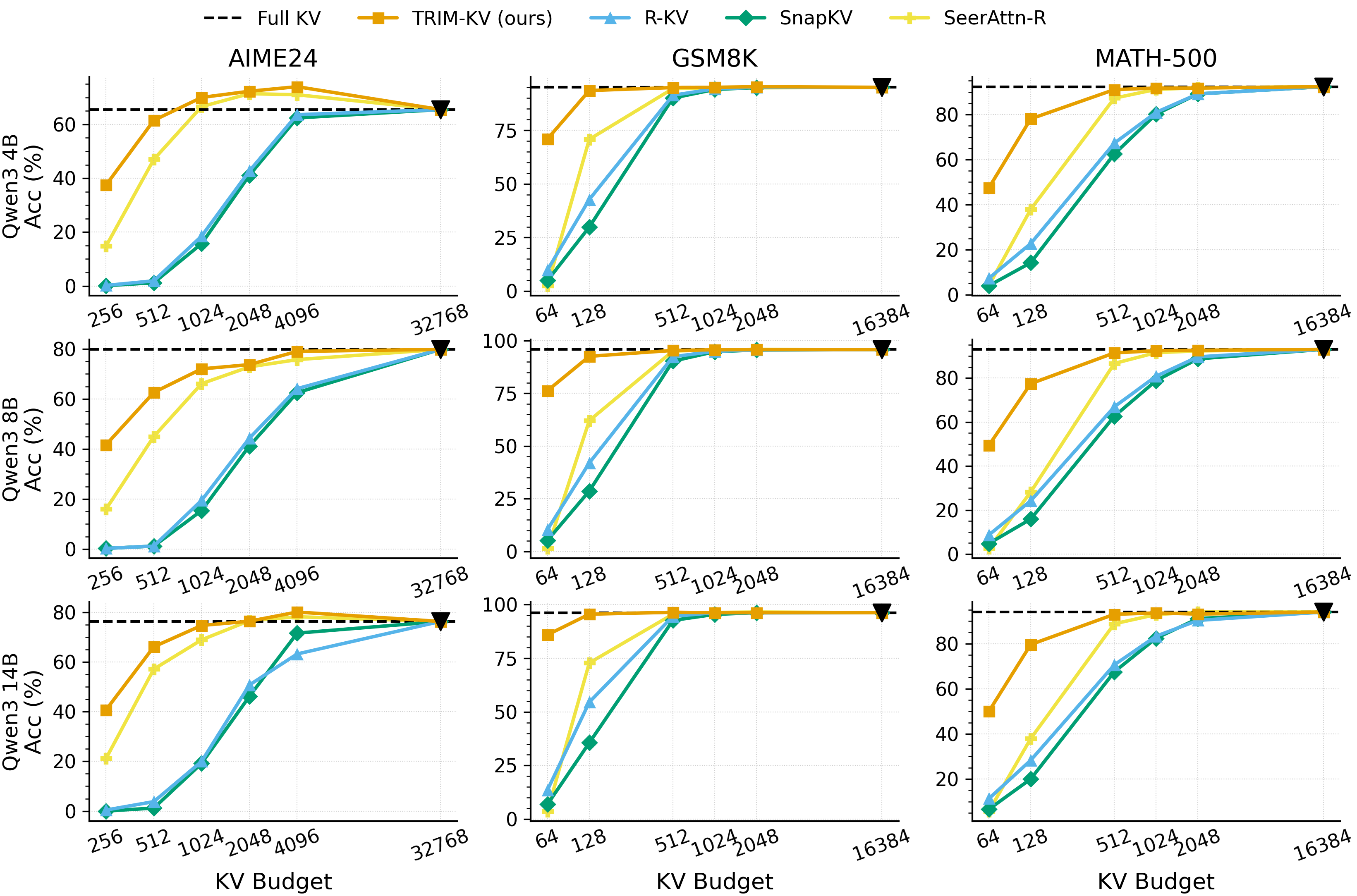
The authors tested TRIM-KV on math problems, long procedural tasks, and very long chat contexts. They report that:
- It beats popular “keep recent things” heuristics (like SnapKV, H2O, StreamingLLM) across many memory budgets, often by a large margin—especially when memory is tight.
- It even outperforms a strong learned retrieval baseline that offloads memory to the CPU, without the overhead of moving data around.
- Surprisingly, in some cases, it does better than keeping the full cache. That means dropping unhelpful tokens can act like a helpful “regularizer” that lowers noise.
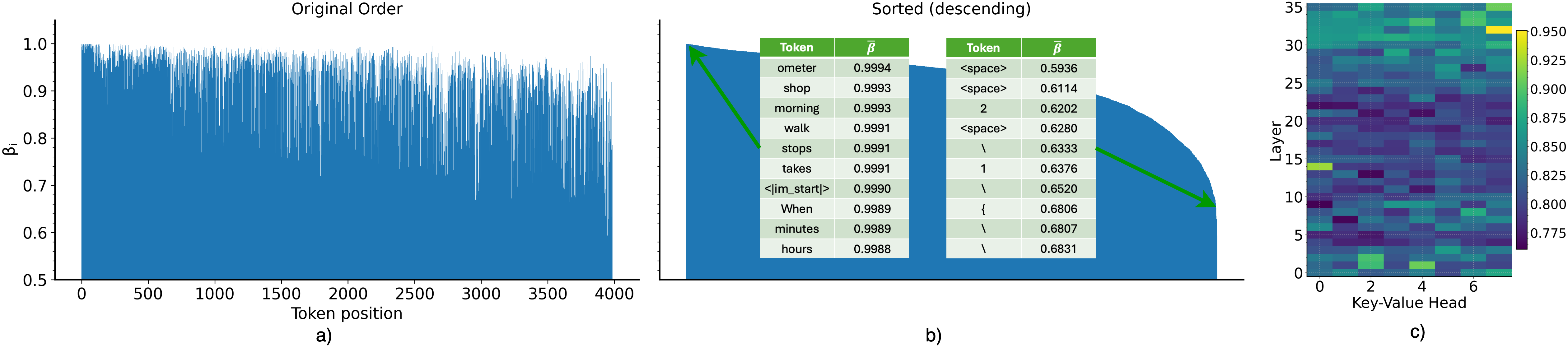
- The learned scores match human intuition. The model naturally:
- Keeps “sink” tokens (important early tokens that set the topic).
- Uses sliding windows when that helps.
- Compresses the “gist” of text when appropriate.
- The scores reveal different roles for layers and heads (parts of the model). Some prefer recent tokens; others keep numbers, variables, or sentence boundaries (like periods), which may work as mini-summaries.
Why is this important? It shows LLMs can use memory smarter, not just more. With the same or even less memory, the model can think better and faster.
Why it matters
- Efficiency: TRIM-KV lets LLMs handle long contexts on smaller GPUs or less powerful machines, reducing cost.
- Reliability: It avoids risky heuristics based only on recent attention, focusing on a token’s deeper, long-term usefulness.
- Better results: In some tasks, selective memory beats using all memory by filtering out uninformative tokens.
- Understanding models: The retention scores help us peek into how different parts of the model treat different kinds of tokens, which can improve interpretability.
Final thoughts and impact
TRIM-KV is a practical, lightweight upgrade for LLMs that helps them remember what matters and forget what doesn’t, all under a fixed memory limit. It can make long conversations, long documents, and step-by-step reasoning more efficient and sometimes even more accurate. In the future, this approach could be extended to multimodal inputs (like text plus images), tool use, or models trained from scratch with memory limits built in.
Collections
Sign up for free to add this paper to one or more collections.