Published 21 Jun 2025 in cs.LG and cs.AI | (2506.17859v2)
Abstract: Recent work analyzing in-context learning (ICL) has identified a broad set of strategies that describe model behavior in different experimental conditions. We aim to unify these findings by asking why a model learns these disparate strategies in the first place. Specifically, we start with the observation that when trained to learn a mixture of tasks, as is popular in the literature, the strategies learned by a model for performing ICL can be captured by a family of Bayesian predictors: a memorizing predictor, which assumes a discrete prior on the set of seen tasks, and a generalizing predictor, where the prior matches the underlying task distribution. Adopting the normative lens of rational analysis, where a learner's behavior is explained as an optimal adaptation to data given computational constraints, we develop a hierarchical Bayesian framework that almost perfectly predicts Transformer next-token predictions throughout training -- without assuming access to its weights. Under this framework, pretraining is viewed as a process of updating the posterior probability of different strategies, and inference-time behavior as a posterior-weighted average over these strategies' predictions. Our framework draws on common assumptions about neural network learning dynamics, which make explicit a tradeoff between loss and complexity among candidate strategies: beyond how well it explains the data, a model's preference towards implementing a strategy is dictated by its complexity. This helps explain well-known ICL phenomena, while offering novel predictions: e.g., we show a superlinear trend in the timescale for transitioning from generalization to memorization as task diversity increases. Overall, our work advances an explanatory and predictive account of ICL grounded in tradeoffs between strategy loss and complexity.
The paper introduces a hierarchical Bayesian framework that explains how transformers balance memorization and generalization through a loss-complexity tradeoff.
It shows that as training progresses, models shift from a simpler generalizing predictor to a more precise memorizing predictor, aligning with Bayes-optimal predictions.
Experiments in settings like balls and urns, linear regression, and classification empirically validate the rational emergence of effective in-context learning strategies.
Rational Emergence of In-Context Learning Strategies
The paper "In-Context Learning Strategies Emerge Rationally" (2506.17859) presents a unifying framework for understanding why LLMs learn different in-context learning (ICL) strategies under varying experimental conditions. It challenges existing behavioral, developmental, and mechanistic accounts by framing ICL strategy selection as a rational adaptation to data and computational constraints, drawing on principles from cognitive science.
Key Observations and Experimental Settings
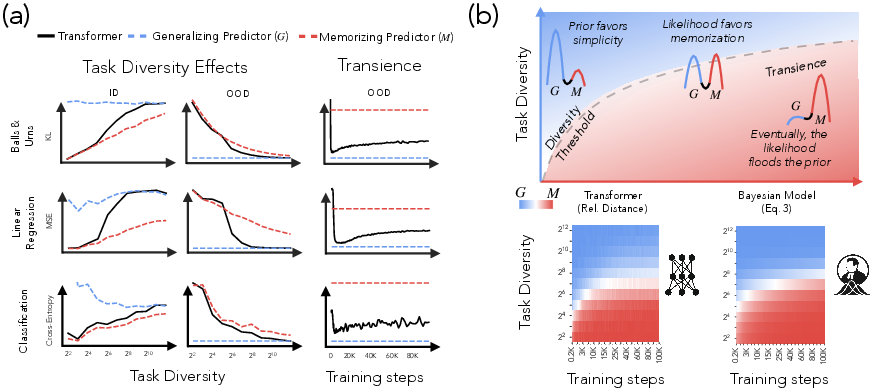
The authors observe that in typical ICL settings involving a mixture of tasks, models tend to learn strategies that align with Bayes-optimal approaches, either generalizing to the overall distribution of tasks or specializing in the specific tasks seen during training (Figure 1).
Figure 1: A model transitions between memorizing and generalizing predictors as data diversity and training increase, explained by a hierarchical Bayesian framework.
The strategies can be unified under two Bayesian predictors: a memorizing predictor that assumes a discrete prior over seen tasks, and a generalizing predictor that assumes a continuous prior matching the underlying task distribution.
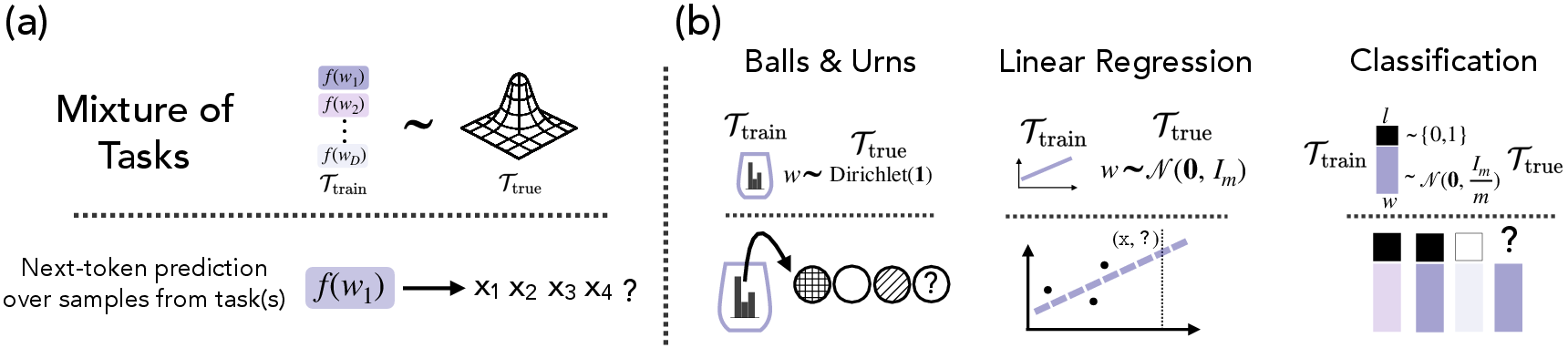
To validate this observation, the authors analyze three distinct experimental settings (Figure 2):
Figure 2: A general formulation is used for three distinct instantiations: Balls and Urns, Linear Regression, and Classification.
Balls and Urns: A simplified Markov modeling setting where the goal is to estimate the distribution of ball types drawn from an urn.
Linear Regression: A standard few-shot learning task where the model learns to solve linear regression problems in context.
Binary Classification: A few-shot learning task where the model predicts labels for noisy item-label pairs.
These settings allow the authors to explore both few-shot learning and belief update formulations of ICL.
Rational Analysis and Hierarchical Bayesian Framework
The core contribution of the paper is a hierarchical Bayesian framework that models ICL as a posterior-weighted average of the memorizing and generalizing predictors. This framework builds on the rational analysis approach from cognitive science, which explains learner behavior as an optimal adaptation to data given computational constraints.
The framework incorporates two key assumptions about neural network learning dynamics:
Power-law scaling of loss with dataset size:L(N)≈L(∞)+NαA, where L(N) is the average loss at time N, and α governs the learning rate.
Simplicity bias: The preference for a predictor Q is given by p(Q)=2−K(Q)β, where K(Q) is the Kolmogorov complexity and β modulates the complexity penalty.
These assumptions lead to a closed-form expression (Eq. 4) for the log-posterior odds η(N,D) of the memorizing predictor:
where ΔL(D) is the difference in loss between the two predictors, and ΔK(D) is the difference in Kolmogorov complexity. This equation highlights the tradeoff between loss and complexity that drives model preference for different strategies.
The posterior probabilities are then computed using a sigmoid function:
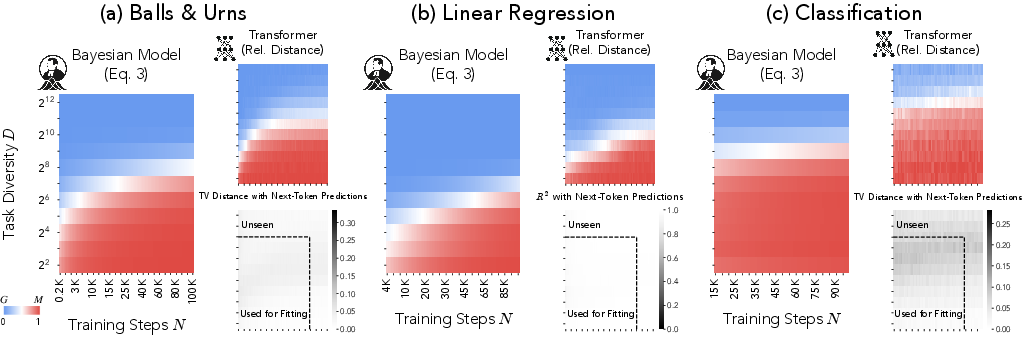
This model accurately predicts Transformer next-token predictions across various settings and reproduces key ICL phenomena such as task diversity effects and transient generalization (Figure 3).
Figure 3: The posterior probability of the memorizing predictor captures the transition between strategies.
Novel Predictions and Loss-Complexity Tradeoff
The framework makes several novel predictions about Transformer behavior, including:
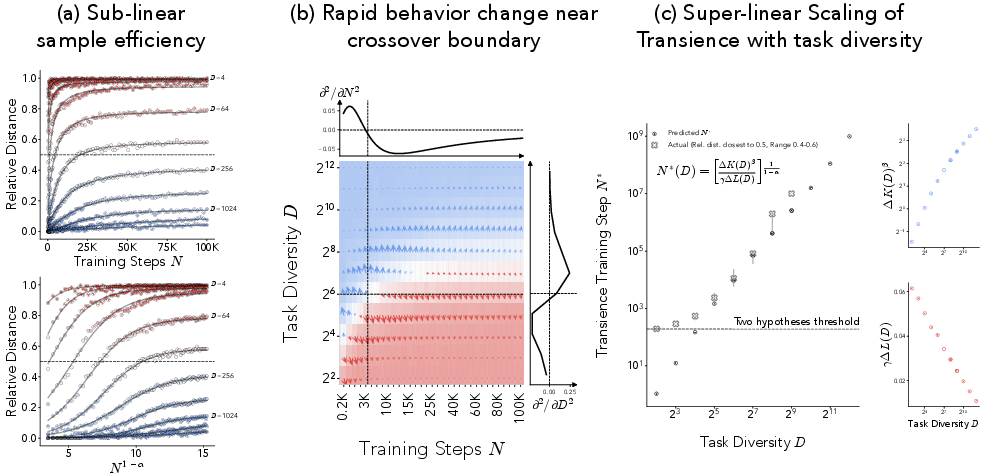
Sub-linear growth of the posterior probability of the memorizing predictor with respect to training steps N, and sigmoidal growth with respect to N1−α (Figure 5a).
A rapid change in model behavior near the crossover point where the log-posterior odds are equal (Figure 5b).
Super-linear scaling of the time to transience N∗ with task diversity D (Figure 5c).
Figure 4: Predictions of sub-linear growth, rapid behavior change, and super-linear scaling are made from the framework.
These predictions are validated empirically, providing further support for the framework. The authors also demonstrate that increasing the MLP width raises the transition boundary between memorization and generalization, suggesting that larger models penalize complexity less.
The loss-complexity tradeoff is central to the authors' interpretation. Early in training, the model favors the simpler generalizing predictor. However, as training progresses, the lower loss of the memorizing predictor eventually outweighs its higher complexity, leading to transient generalization.
Relation to Prior Bayesian Models of ICL
The work contrasts with prior Bayesian accounts of ICL that typically frame ICL as implementing a single predictor. In contrast, this work accounts for the fact that multiple predictors are required to fully capture model behavior across conditions. The authors note the similarity of their conclusions to those reached by \citet{carroll2025dynamics} and \citet{elmoznino2025incontextlearningoccamsrazor}, both of which highlight a trade-off between loss and solution complexity in pretraining.
Conclusion
The paper offers a compelling and unifying account of ICL by framing it as a rational adaptation to data and computational constraints. The hierarchical Bayesian framework accurately predicts Transformer behavior and explains key ICL phenomena through a loss-complexity tradeoff. The authors advocate for a normative perspective in understanding neural networks, viewing learning as a rational process of density estimation subject to simplicity bias and sublinear sample efficiency. This perspective can potentially provide highly predictive accounts and explanations for model behavior.
Future Directions
Future research could explore settings with more than two feasible predictors and extend the framework to out-of-distribution evaluation. A crucial limitation lies in the assumed relation between algorithmic complexity and complexity of implementation by a Transformer; future work could improve this aspect by building on recent advances defining measures of how many effective parameters are used by a model to implement a solution.