- The paper introduces MultiFinRAG, a framework that optimizes multimodal retrieval-augmented generation for financial QA.
- The paper employs batch multimodal extraction and a tiered retrieval strategy, significantly enhancing accuracy across text, image, and table inputs.
- The system demonstrates robust performance in multimodal reasoning, offering a computationally efficient solution for complex financial document analysis.
An Optimized Multimodal Retrieval-Augmented Generation Framework
Introduction
The paper introduces "MultiFinRAG," a Retrieval-Augmented Generation (RAG) framework optimized for financial Question Answering (QA). This system is designed to handle the multimodality inherent in financial documents, which integrate narrative text, structured tables, and complex figures. By leveraging batch multimodal extraction and a tiered fallback strategy, MultiFinRAG improves accuracy on financial QA tasks. This framework specifically targets the limitations of traditional RAG pipelines, such as token inefficiency and loss of contextual integrity across multimodal information.
Methodology
MultiFinRAG Pipeline
The MultiFinRAG framework consists of several key components for processing financial documents, as depicted in the pipeline.
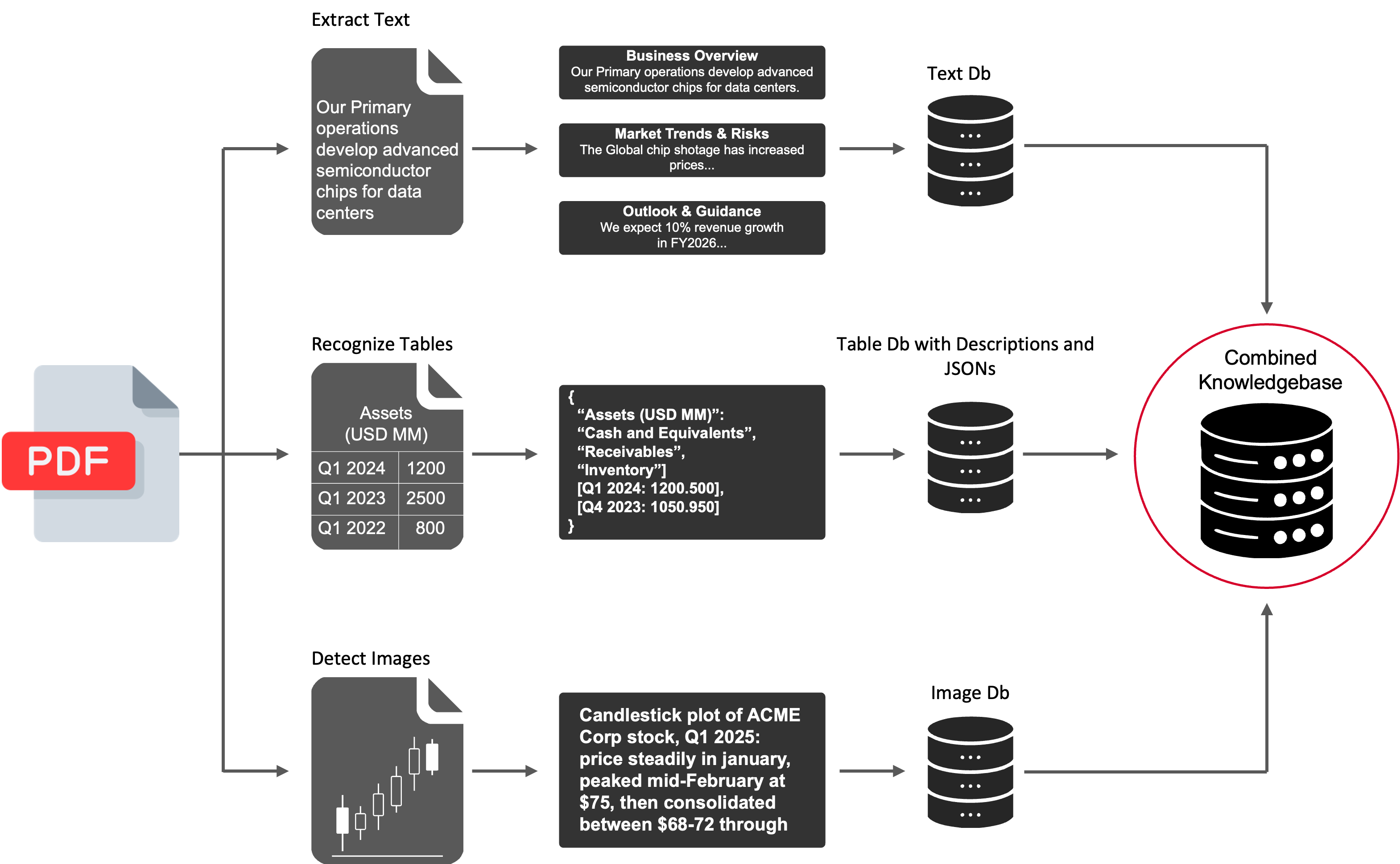
Figure 1: MultiFinRAG pipeline: knowledge base construction from PDF text, tables, and figures.
- Table Detection: Uses Detectron2Layout trained on TableBank.
- Image Detection: Utilizes Pdfminer's layout analysis.
- Multimodal Summarization: Employs Gemma3 and LLaMA 3.2 models for summarizing tables and images.
- Embedding and Retrieval: FAISS handles approximate nearest-neighbor search with text, table, and image embeddings generated by SentenceTransformer.
The system employs batch processing for both tables and images, ensuring comprehensive extraction and efficient alignment with LLMs.

Figure 2: Generated table description and JSON.
Tiered Retrieval Strategy
MultiFinRAG employs a tiered retrieval strategy to ensure comprehensive context. Initial text retrieval sets the stage, escalating to include tables and images if the text-only context is found lacking.
Decision Function
The retrieval threshold values for text, table, and image modalities were optimized through empirical evaluation, ensuring high relevance and response accuracy.
Evaluation
The framework's performance was evaluated across various question types: text-based, image-based, table-based, and those requiring multimodal reasoning.
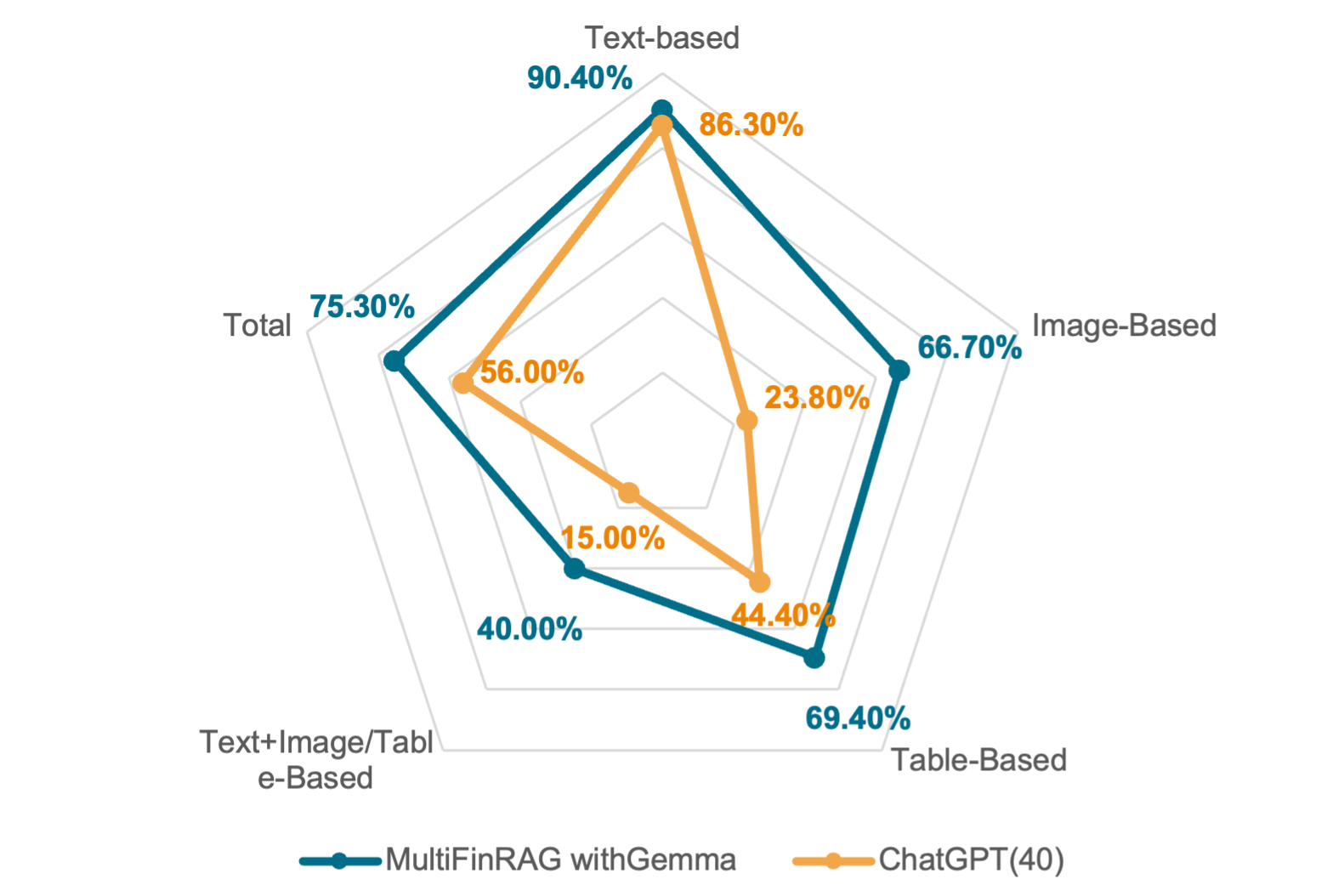
Figure 3: Accuracy Comparison by Question Type.
- Text-based: MultiFinRAG with Gemma outperforms the baseline.
- Image-based: Demonstrates substantial improvement, underscoring the advantage of multimodal extraction.
- Table-based: Significant gains over baseline, attributed to structured data handling and summary generation.
- Multimodal Reasoning: Exhibits robust performance, indicating effective cross-modal integration.
Discussion
MultiFinRAG's integration of modality-aware retrieval thresholds and lightweight LLMs demonstrates potential to revolutionize financial QA systems. By optimizing batch processing and retrieval strategies, this method achieves high accuracy while minimizing computational overhead, suitable even for commodity hardware.
Future Work
The framework could be extended with:
- Enhanced pipeline evaluations through module-wise analysis.
- Broader user studies for validating in practical workflows.
- Augmenting capabilities for structured data and robust error correction mechanisms.
- Expanding domain coverage to include diverse financial and regulatory documents.
- Fine-tuning for domain specificity through supervised training on high-quality datasets.
Conclusion
MultiFinRAG sets a new standard for Financial QA by efficiently integrating multimodal information. Its innovative use of retrieval thresholds, batch processing, and structured reasoning demonstrates significant improvements over existing systems like ChatGPT-4o, delivering high accuracy while operating with reduced computational demands.