ThinkSound: Chain-of-Thought Reasoning in Multimodal Large Language Models for Audio Generation and Editing
Abstract: While end-to-end video-to-audio generation has greatly improved, producing high-fidelity audio that authentically captures the nuances of visual content remains challenging. Like professionals in the creative industries, this generation requires sophisticated reasoning about items such as visual dynamics, acoustic environments, and temporal relationships. We present ThinkSound, a novel framework that leverages Chain-of-Thought (CoT) reasoning to enable stepwise, interactive audio generation and editing for videos. Our approach decomposes the process into three complementary stages: foundational foley generation that creates semantically coherent soundscapes, interactive object-centric refinement through precise user interactions, and targeted editing guided by natural language instructions. At each stage, a multimodal LLM generates contextually aligned CoT reasoning that guides a unified audio foundation model. Furthermore, we introduce AudioCoT, a comprehensive dataset with structured reasoning annotations that establishes connections between visual content, textual descriptions, and sound synthesis. Experiments demonstrate that ThinkSound achieves state-of-the-art performance in video-to-audio generation across both audio metrics and CoT metrics, and excels in the out-of-distribution Movie Gen Audio benchmark. The project page is available at https://ThinkSound-Project.github.io.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces ThinkSound, a smart system that adds realistic sound to videos. It does this by “thinking” step-by-step, like a human sound designer, to figure out what sounds should happen, when they should happen, and how they should fit the scene. ThinkSound can also let users refine sounds by clicking on objects in the video and edit sounds using plain-language instructions.
Key Objectives
Here are the main goals of the research, explained simply:
- Make video sound more realistic and better timed with what’s happening on screen, not just generic noise.
- Teach an AI to “think in steps” about sound, so it can handle complex scenes with multiple actions and events.
- Create an easy way for users to control sounds in a video by pointing to specific objects and using natural language (like “make the footsteps louder”).
- Build a single powerful audio model that can handle many tasks: making new sounds, improving them, and editing them.
- Provide a new dataset called AudioCoT that pairs videos, text descriptions, and sound reasoning to train better models.
Methods and Approach
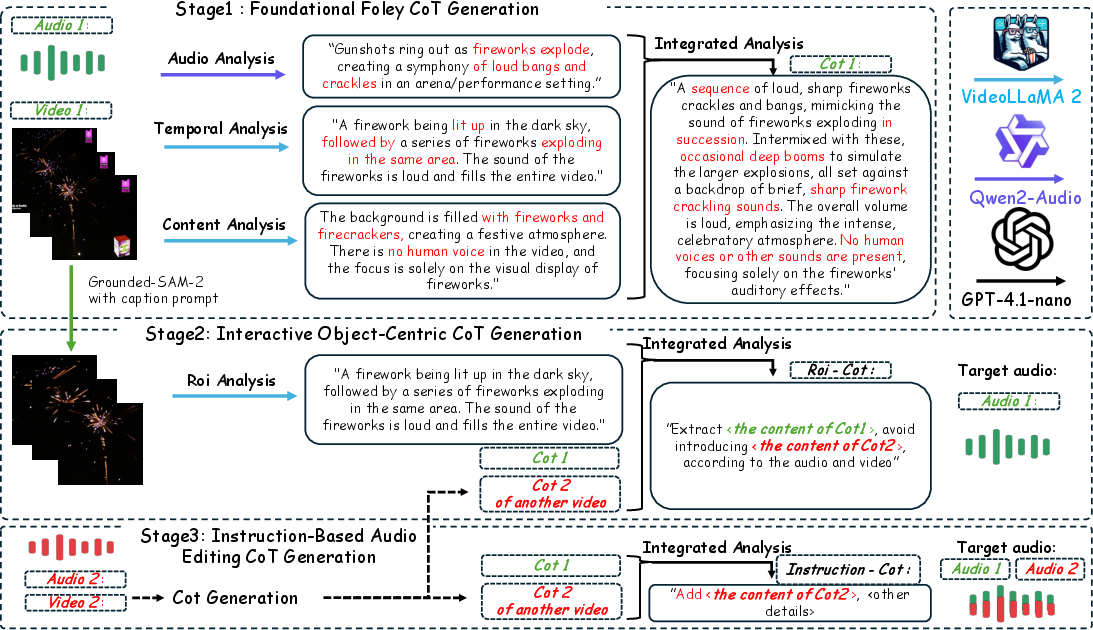
ThinkSound works in three stages, guided by a “Chain-of-Thought” (CoT) plan—this is just the AI explaining its own step-by-step reasoning.
- Foundational foley generation “Foley” means sound effects added to movies (like footsteps, door clicks, wind). First, the AI watches the whole video and writes a clear plan: what sounds should happen, in what order, how loud they should be, and how they interact. Then it generates the main soundscape that matches the scene.
- Interactive object-focused refinement If you click on an object in the video (say, a dog), the AI zooms in on that area and refines the sound just for that object. It thinks about what the dog should sound like right now (barking? paw steps?) and blends that sound smoothly with the existing audio.
- Instruction-based audio editing You can edit the audio by typing instructions like “remove car engine noise,” “extend the rain,” “fill in missing audio,” or “add a door slam.” The AI translates your request into a step-by-step plan and applies it without breaking the overall soundtrack.
How it’s built:
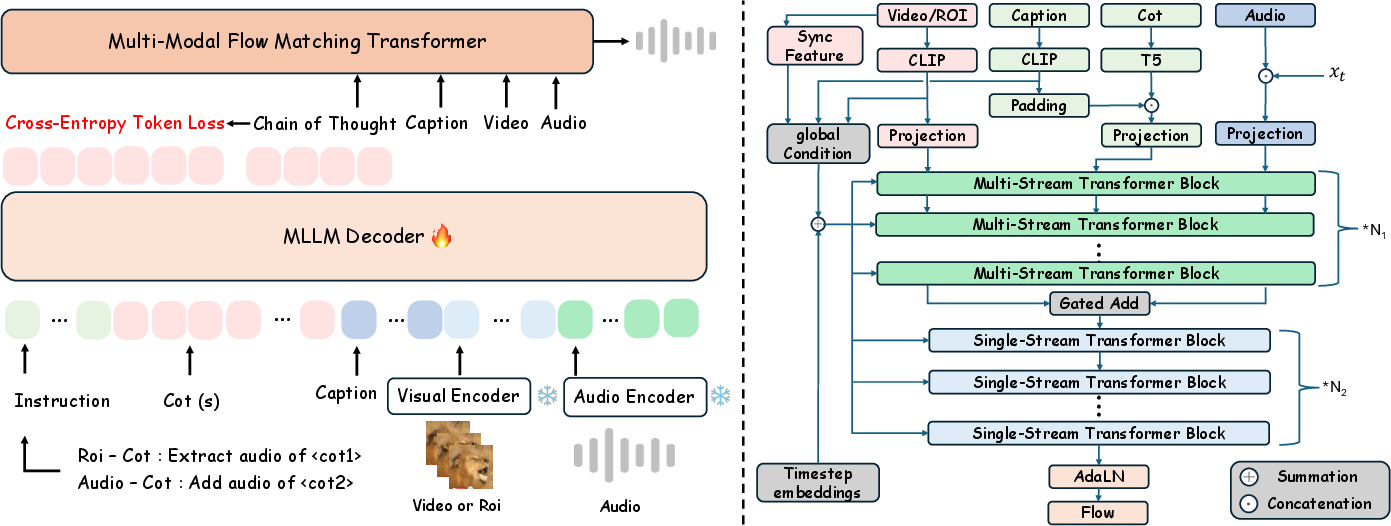
- Multimodal LLM (MLLM): This is an AI that understands videos, text, and audio together. ThinkSound fine-tunes an existing model (VideoLLaMA2) to produce clear CoT steps for sound generation and editing.
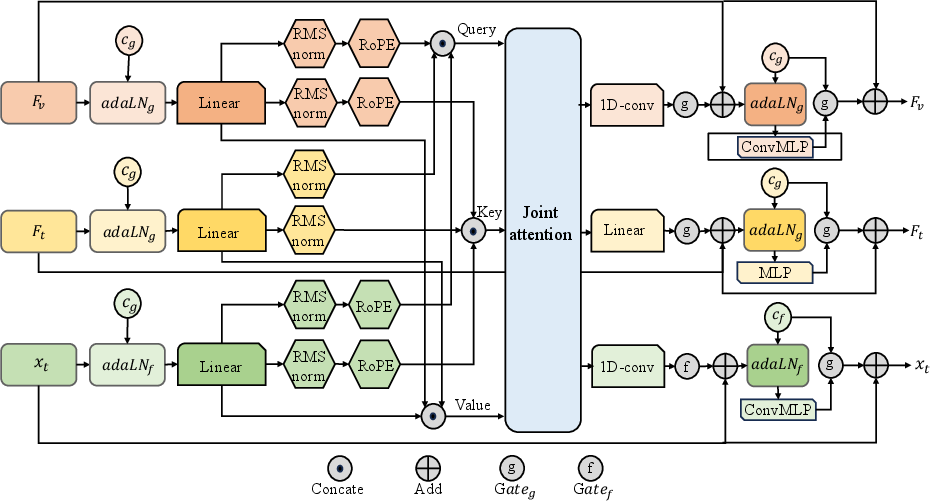
- Unified audio foundation model: This is the “sound maker” that turns the step-by-step plan into actual audio. It uses a technique called “flow matching,” which you can think of like guiding random noise to slowly become a clear, correct sound by following a path. It also uses tools like a VAE (a smart compressor for sound) and special encoders for text and video features.
- AudioCoT dataset: A large collection of video-and-audio clips, audio-and-text pairs, and detailed reasoning steps. It teaches the AI how to connect visuals, descriptions, and sounds in a structured way.
- Click-based object selection: The system can find and track objects in the video (like cars or doors) and focus sound changes on them.
Simple analogy: Imagine a chef reading a step-by-step recipe. The LLM writes the recipe (“first footsteps, then door opens, then wind gets louder”), and the audio model cooks the sound following that recipe. If you point to the “salt” (an object) or say “make it spicier” (an instruction), the chef adjusts just that part without ruining the whole dish.
Main Findings
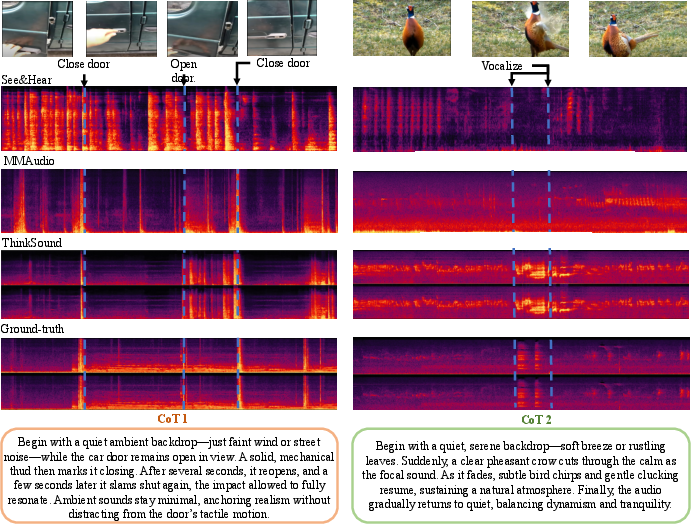
- Better sound quality and timing: ThinkSound creates audio that matches video events more accurately than other systems. Sounds start and stop when they should and feel more “in the scene.”
- Stronger understanding of complex scenes: Because it reasons step-by-step, ThinkSound handles tricky moments—like a car door closing, opening, then closing again—without mixing up the order.
- Improved alignment with text and visuals: Tests show ThinkSound’s audio fits the video and the CoT plan more closely.
- Works well on new, unseen videos: On an outside benchmark it hadn’t trained on, ThinkSound still performed the best or tied for best in key measures.
- CoT really helps: When the researchers removed the step-by-step reasoning, the results clearly got worse—proof that “thinking out loud” guides better sound.
Implications and Impact
ThinkSound brings us closer to truly realistic and controllable sound for videos. This can help:
- Filmmakers and game developers create rich, believable soundtracks faster.
- Creators on social media make better videos without needing expert audio skills.
- Education and accessibility tools that need clear audio synced to visuals.
In the future, the team plans to add more knowledge about real-world acoustics (like echoes and how sound travels in rooms) and improve reasoning for scenes with many moving objects. Overall, ThinkSound shows that when AI explains its thinking and follows a clear plan, it can make smarter, more convincing audio for almost any video.
Collections
Sign up for free to add this paper to one or more collections.