- The paper introduces MARBLE, a novel benchmark that rigorously evaluates multimodal LLMs’ ability to perform complex spatial reasoning and multi-step planning using tasks derived from Portal 2 environments and 3D puzzles.
- The evaluation reveals that current models, including leading open- and closed-source MLLMs, struggle with maintaining coherent multi-step reasoning, often performing at or near random baseline levels on challenging tasks.
- The study highlights that even modest increases in combinatorial complexity and perceptual challenges drastically reduce model accuracy, underscoring the need for enhanced perception-reasoning integration and tool-assisted iterative feedback.
MARBLE: A Benchmark for Multimodal Spatial Reasoning and Planning
Motivation and Benchmark Design
The MARBLE benchmark ("MultimodAl Reasoning Benchmark for LLMs") is introduced to rigorously evaluate the capacity of multimodal LLMs (MLLMs) for complex spatial reasoning and multi-step planning under physical constraints (2506.22992). Existing multimodal benchmarks primarily focus on shallow single-step reasoning or factual retrieval, lacking diagnostics for challenging stepwise, multimodally grounded reasoning. MARBLE addresses this gap by formulating two cognitively demanding tasks: (1) spatial reasoning and planning derived from Portal 2 video game environments, and (2) 3D jigsaw cube assembly inspired by the Happy Cube puzzle. Both tasks require the integration of visual and textual information to generate detailed solution plans, not just final answers.
The Portal-2 task decomposes complex challenges into multimodal input (screenshots, textual context) and requires construction or evaluation of multi-step chains of thought (CoT), including plan correction and fill-in-the-blank evaluation scenarios.

Figure 2: Overview of the Portal-2 Dataset of the MARBLE-Benchmark, illustrating a basic problem requiring a sequence of structured reasoning steps.
The Cube assembly task demands accurate piece-to-face assignment and orientation in a high-combinatorial space, emphasizing the joint challenge of perception and spatial reasoning.
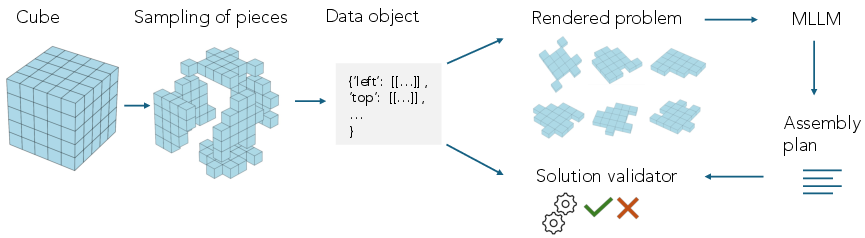
Figure 4: Overview of the Cube workflow: data generation, rendering, and solution validation for 3D multimodal reasoning.
Evaluation Methodology and Model Selection
Twelve models are tested, encompassing a range of open- and closed-source MLLMs (e.g., Qwen2.5-VL-72B, GPT-4o, Gemini-2.5-pro, Claude-3.7-Sonnet) as well as text-only models (e.g., DeepSeek-R1, Qwen3). Visual-only models are provided with images and text, while text-only models use textual representations of the visual content. The benchmark strictly evaluates plan correctness (binary classification) and fill-the-blanks (step insertion among candidates) in the Portal-2 task, and open-ended solution validity in Cube assembly.
Empirical Findings
Portal-2 Spatial Reasoning
On the most challenging plan-correctness subtask, all MLLMs perform at or near the random baseline (~6% F1), including leading closed-source and open-source models. For the easier fill-the-blanks subtask, only 8 of 12 models outperform random guessing, and the best performance (GPT-o3: 17.6%) remains far below levels required for robust multimodal reasoning.
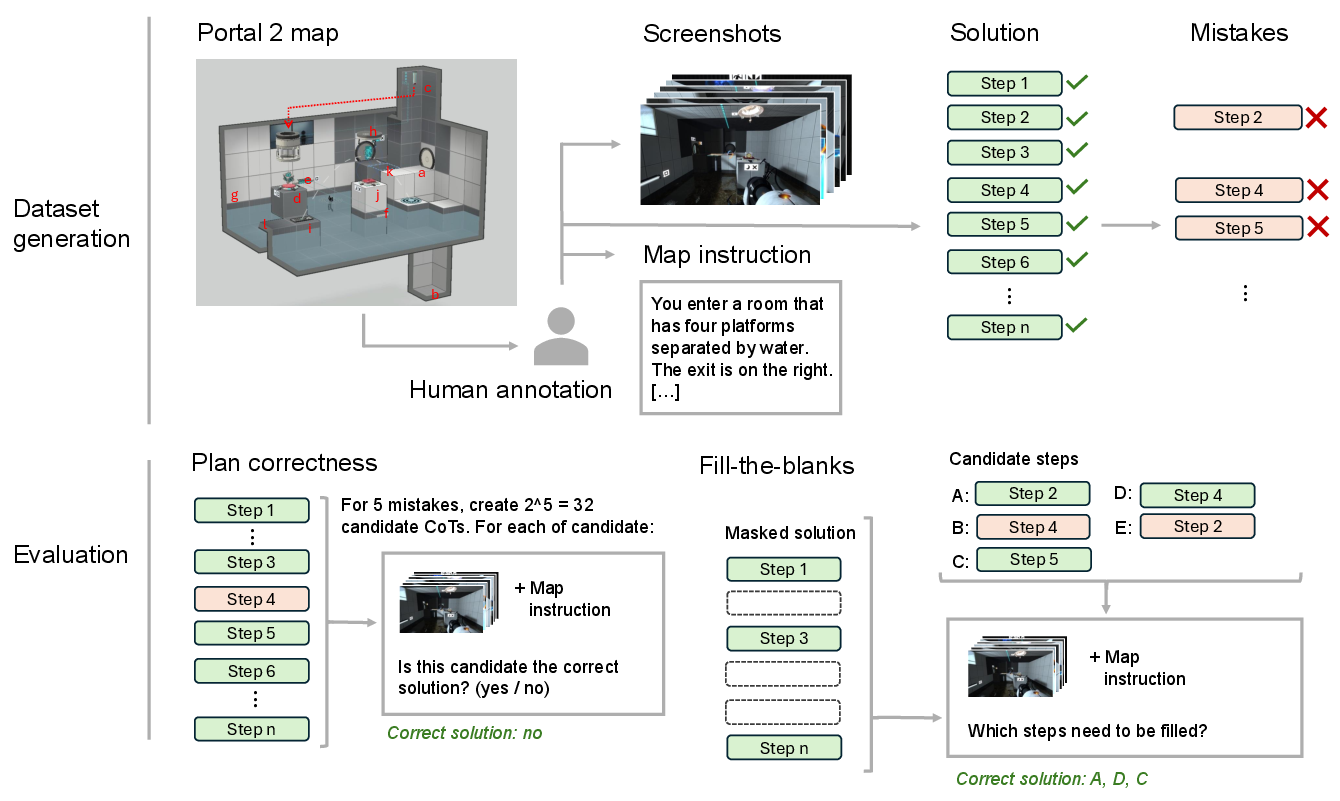
Figure 3: Data generation and evaluation pipeline for the Portal-2 task, highlighting multimodal annotation, solution/mistake construction, and evaluation modes.
Performance is sensitive to the number of missing steps: when a single blank is present, models (e.g., Qwen2.5-VL-72B) can achieve ~70% accuracy, but accuracy drops sharply with additional missing information, illustrating a critical inability to maintain solution coherence over longer reasoning chains or larger search spaces.
Cube Assembly and Perception Challenges
For the full Cube assembly task, all models fail completely (0% accuracy). In the reduced CUBE-easy condition—where inputs are textual, piece flips are unnecessary, and four of six pieces are pre-placed—GPT-o3 achieves the highest accuracy at 72.0%, while all other models remain orders of magnitude lower. This highlights that even moderate increases in search space or combinatorial complexity rapidly degrade MLLM performance.
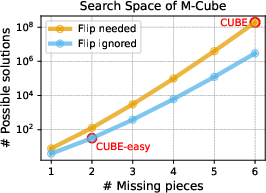
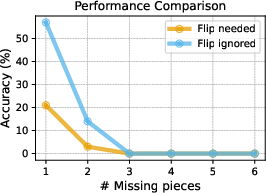
Figure 6: Search space of the Cube dataset under various configurations, demonstrating combinatorial explosion and the challenge for current models.
Systematic perception tests reveal further bottlenecks: asked to transcribe the structured grid of a single jigsaw piece from images, all MLLMs achieve only ~70–76% per-cell accuracy and universally fail at reconstructing entire pieces. This perceptual weakness directly impedes downstream spatial reasoning.

Figure 5: Perception bottleneck—MLLMs struggle to transcribe 3D piece geometry into structured arrays, with best cell-level accuracy at 76% and no model reconstructing entire pieces correctly.
Experiments isolating reasoning (by providing ground-truth text arrays) demonstrate limited success: DeepSeek-R1, for instance, attains 57% accuracy with a single missing piece but fails entirely beyond three missing pieces, underscoring the inability to search high-dimensional, multimodal solution spaces effectively.
Incorporating tool use, specifically an external solution validator providing binary or diagnostic feedback, yields modest improvements only on the easiest subtask (CUBE-easy), with iterative diagnostic feedback raising GPT-o4-mini's accuracy from 10% to approximately 28%. However, no feedback regime enables models to solve the full CUBE task, further emphasizing the gap between current MLLM capabilities and the requirements of rigorous spatial, multimodal planning.

Figure 1: Example demonstrating iterative interaction between MLLM and solution validator in the Cube task, with diagnostic feedback supporting modest performance gains on simplified tasks.
Implications and Future Directions
MARBLE exposes fundamental limits of current multimodal models in both visual perception and compositional, multi-step spatial reasoning. All tested MLLMs fail dramatically on realistic instances requiring chained multimodal reasoning and exploration of large solution spaces. Notably, even the best-performing models on simplified tasks are susceptible to perceptual errors and combinatorial reasoning failures.
Practical implications are significant: robust multimodal agents for scientific, engineering, or embodied reasoning tasks exceed the current state-of-the-art by a wide margin. The benchmark's focus on diagnosing the entire reasoning trajectory, including intermediate step validation, provides granular error attribution and a platform for the development of more general, tool-using, and compositional MLLMs.
From a theoretical perspective, the dichotomy between shallow question answering and stepwise, multimodally grounded planning is clarified, motivating the design of architectures and training regimes that intertwine perception and non-myopic, physically consistent reasoning.
Future model development may benefit from:
- End-to-end architectures with explicit perception-reasoning modularity,
- Enhanced search and verification modules for high-dimensional combinatorial problems,
- Tight integration with tools and iterative feedback as a core reasoning component,
- Pretraining signals emphasizing chains-of-thought over both modalities.
Conclusion
MARBLE constitutes a rigorous benchmark exposing the inability of current MLLMs to tackle multi-step, multimodal spatial reasoning and planning. The findings highlight critical failings in both perception and long-horizon reasoning, especially as combinatorial complexity rises. Systematic diagnostic tasks—distinguishing perception from reasoning, and testing tool-assisted refinement—demonstrate that substantial advances are required before multimodal agents can meaningfully approach human-level competence on spatially and physically grounded tasks. The benchmark is positioned to drive methodological innovation in both model design and multimodal supervision, necessary for progress in embodied and general-purpose artificial intelligence.