- The paper introduces a region-focused dual-resolution token pooling method that efficiently captures both volumetric and region-specific details in 3D CT scans.
- It integrates mask-driven segmentation and patient-specific attribute extraction to produce structured, fine-grained diagnostic reports.
- Empirical results demonstrate superior performance with enhanced BLEU, clinical accuracy, and reduced hallucinations compared to existing global aggregation models.
MedRegion-CT: Region-Focused Multimodal LLM for Comprehensive 3D CT Report Generation
Motivation and Problem Scope
Despite major advances in Vision-Language Pre-training (VLP), recent 3D multimodal LLMs targeting CT-based report generation remain dominated by coarse global feature aggregation, without robust mechanisms for explicit region localization or patient-specific context. This is incongruent with real-world diagnostic workflows, where radiologists systematically assess distinct anatomical subregions, reconcile image and clinical findings, and document fine-grained, regionally specific abnormalities. Existing VLP frameworks, though effective for 2D image–text tasks, struggle to bridge the gap between high-dimensional 3D CT volumes and concise, radiologically accurate structured reports.
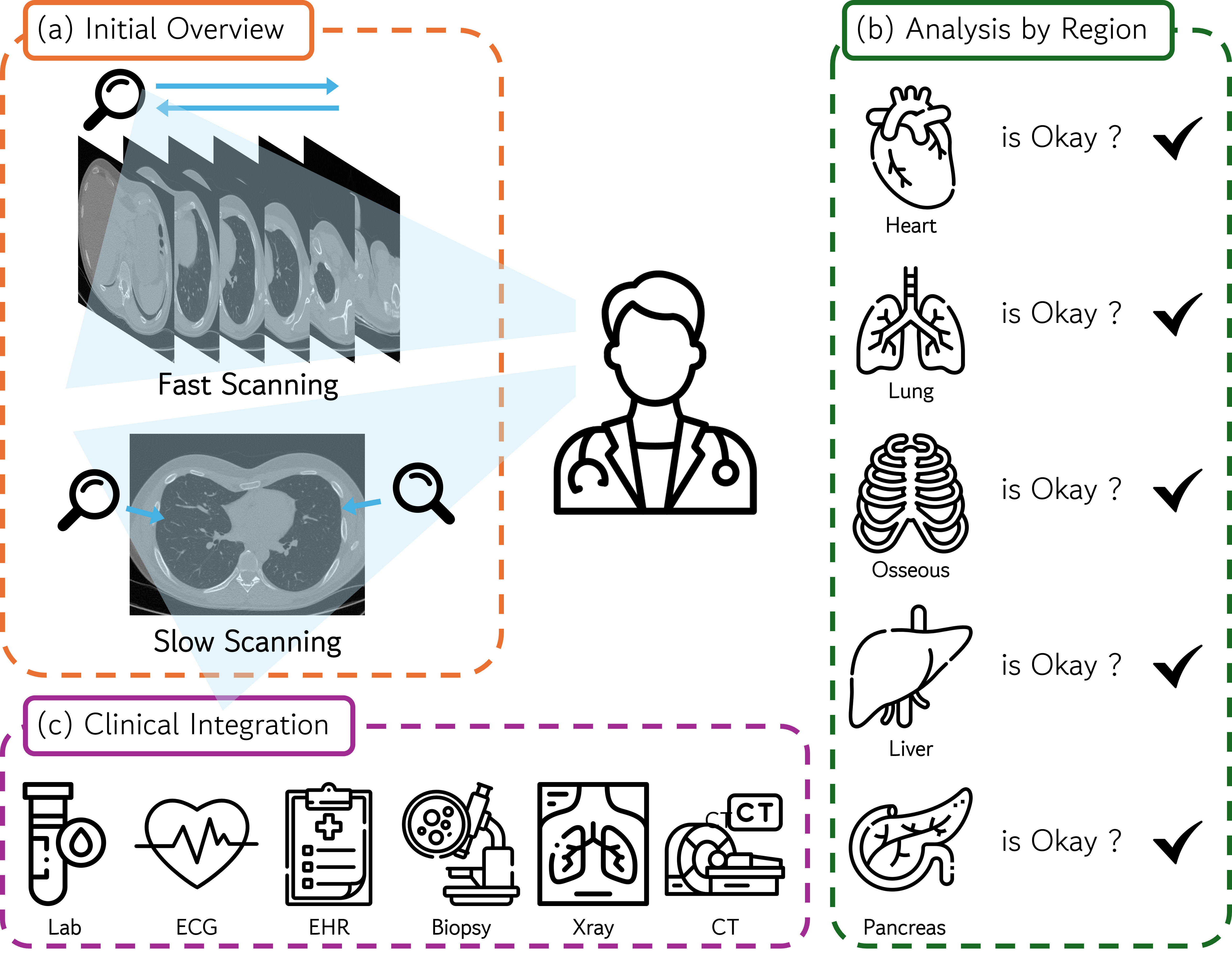
Figure 1: A detailed encapsulation of the modern radiological workflow, emphasizing region-level analysis and integrative clinical interpretation.
Architecture: Region Representative Pooling and Region-Centric Integration
MedRegion-CT introduces a region-focused MLLM architecture, with three critical modules tailored to 3D CT scenarios:
- Region Representative (R2) Token Pooling: Each CT scan is processed in a slice-wise fashion with a frozen 2D vision encoder. Token-level features are reduced by pooling: "fast" tokens densely summarize all slices for spatial continuity, while "slow" tokens sparsely sample regionally informative slices using region-centric heuristics (highest pseudo-mask pixel count), rather than uniform sampling. This dual-resolution token representation drastically reduces computational complexity while capturing volumetric and region-specific context.
- Mask-Driven Visual Extractor: Universal segmentation (SAT model) generates pseudo-masks for six predefined regions. These drive extraction of mask and spatial tokens through a modified MAIRA-SEG pipeline, but now extended to 3D. Mask pooling operates on R2 tokens, generating fixed-length segmentation token blocks for major organs/lesions. Tokens are positionally aligned to the input prompt, independently from mask presence for compositionality.
- Patient-Specific Attribute Extraction: Deterministic, scripted algorithms mine morphological statistics (e.g., volume, count, diameters, locations) from the pseudo-masks. These are formatted as auxiliary textual prompts, enabling the LLM to explicitly condition outputs on nuanced, quantitative, patient-level data.
Figure 2: An overview of MedRegion-CT, illustrating its modular flow—R2 token pooling, mask pooling, and integration of attribute-driven prompts.
Structured Training and Reporting Protocol
Training data from RadGenome-Chest CT is partitioned according to six anatomical regions (lung, large airways, mediastinum, heart/great vessels, osseous structures, upper abdomen); ground truth reports are likewise decomposed and realigned. The architecture output is a concatentation of per-region reports, mirroring clinical structured reporting. The LLM (LLaMA3-8B) receives three token streams—visual (Tvision), segmentation (Tseg), and attribute (Tattr) tokens—along with an explicit instruction prompt, producing auto-generated reports with aligned granularity.
Evaluation and Empirical Results
Quantitative benchmarks use both NLG metrics (BLEU-4, ROUGE-L, METEOR) and clinical LLM metrics (Clinical Accuracy (CA, by RadBERT), GREEN, GPT-4 evaluator). On all principal axes, MedRegion-CT exhibits superior performance: BLEU-4 0.290, CA 0.450, GPT-4 score 48.837, outperforming strong open-source 3D report generators such as M3D, MedBLIP, RadFM, and CT2Rep. Importantly, ablation experiments confirm all three architectural contributions are necessary: using only region pool tokens causes catastrophic failure in lesion localization and specificity; omitting mask/attribute modules impairs clinical and contextual fidelity.
Qualitative analyses (COVID-19 pneumonia case) underscore semantic precision: MedRegion-CT uniquely captures bilateral GGO, absence of spurious findings, and contextually accurate recommendations, while baselines introduce hallucinated lesions or omit critical positives.
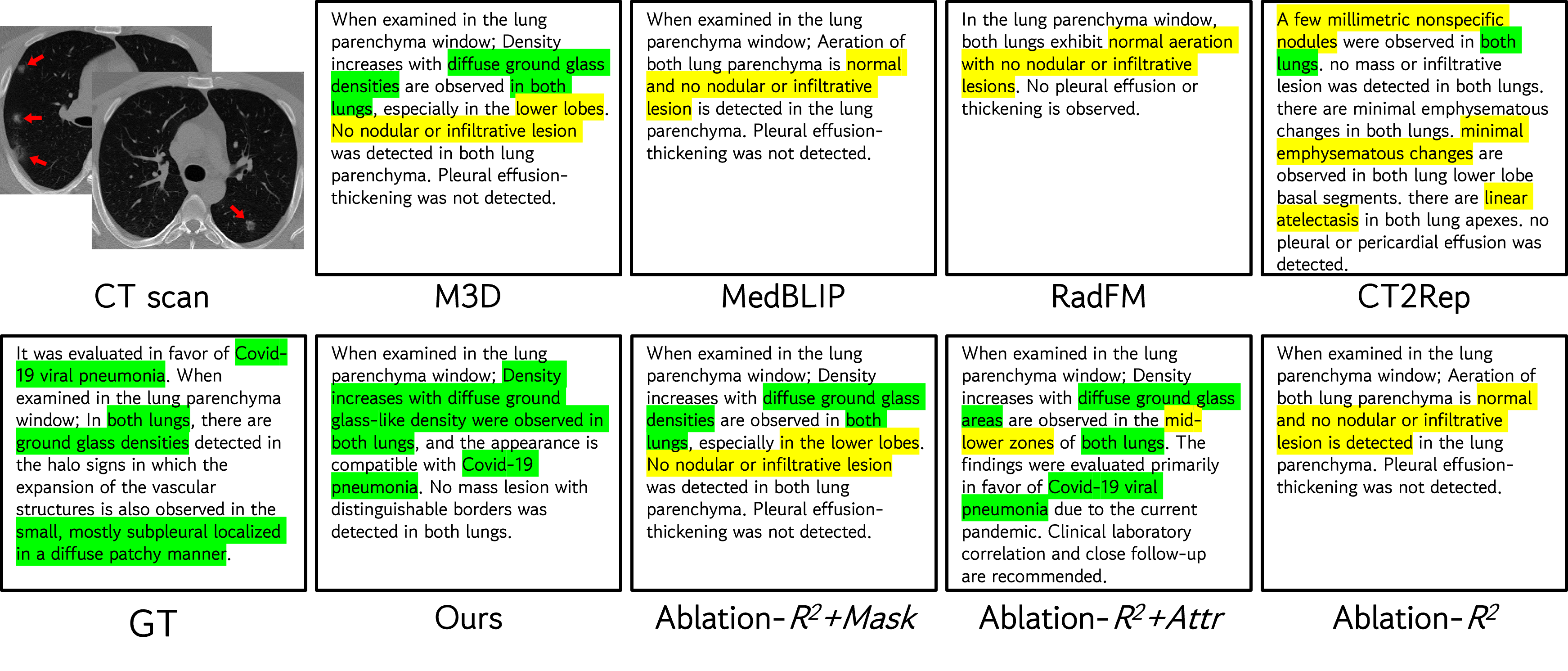
Figure 3: Report-level qualitative comparison visualizing the diagnostic granularity and reduction of hallucinated findings achieved by MedRegion-CT versus strong baselines.
Theoretical and Practical Implications
Region-centric pooling and per-region report structuring mark a decisive shift from global volume-level representation, enabling scalable integration of clinical prior knowledge and interpretability. The attribute extractor provides an explicit channel for quantitative, machine-assessed metadata—a pivotal step towards explainability and structured quality control in LLM-driven reporting. This system is modular regarding base segmentation method and can generalize to additional anatomical or pathologic regions with commensurate mask support.
Model interpretability is enhanced by token-level mask alignment and prompt engineering: every region, organ, and lesion's quantitative representation is both tokenized for the LLM and mirrored in textual form, strengthening traceability and debuggability.
Outlook and Future Directions
The supervised, region-focused strategy demonstrated by MedRegion-CT establishes a paradigm for multi-resolution pooling and direct integration of image-derived statistics into LLMs for clinical reporting. Future avenues include:
- Expansion to non-chest CT domains and other 3D modalities (MRI, PET) by reparameterizing region definitions and mask extraction pipelines.
- Task generalization to complex diagnostic pipelines (e.g., cancer staging, response assessment) where temporal and multi-region continuity is essential.
- Tighter model–clinician integration by providing uncertainty quantification and calibration of attribute-driven explanations.
- Evaluation of robustness to out-of-distribution (OOD) pathology, rare findings, and transfer to limited-labeled or weakly grounded datasets.
- Potential for unsupervised or active learning refinement in the attribute and mask extraction subsystems.
Conclusion
MedRegion-CT advances region-focused 3D medical report generation by coalescing efficient R2 token pooling, mask-driven segmentation tokenization, and deterministic attribute prompting within a single MLLM pipeline. The combination leads to improved granularity, interpretability, and clinical fidelity over prior global-centric approaches. The modular design and empirical superiority across both linguistic and clinical indices suggest high potential for deployment in real-world clinical decision support and for transfer to other structured diagnostic scenarios.