- The paper introduces incoherence as a novel, oracle-less measure for evaluating errors in LLM-generated code by quantifying divergence between independently sampled outputs.
- The paper establishes a probabilistic framework linking incoherence with functional error, achieving high correlation (Spearman's ρ ≥ 0.92) with traditional oracle-based evaluations.
- The paper demonstrates that incoherence effectively identifies approximately two-thirds of incorrect programs, providing a scalable method for assessing LLM code correctness.
Incoherence as Oracle-less Measure of Error in LLM-Based Code Generation
Introduction
The paper "Incoherence as Oracle-less Measure of Error in LLM-Based Code Generation" (2507.00057) introduces an innovative approach for evaluating the correctness of code generated by LLMs without relying on a ground-truth oracle. The central challenge addressed is the frequent confabulation of LLMs, which can produce syntactically correct but functionally erroneous code. This issue is particularly critical in real-world deployments lacking existing implementations or formal specifications.
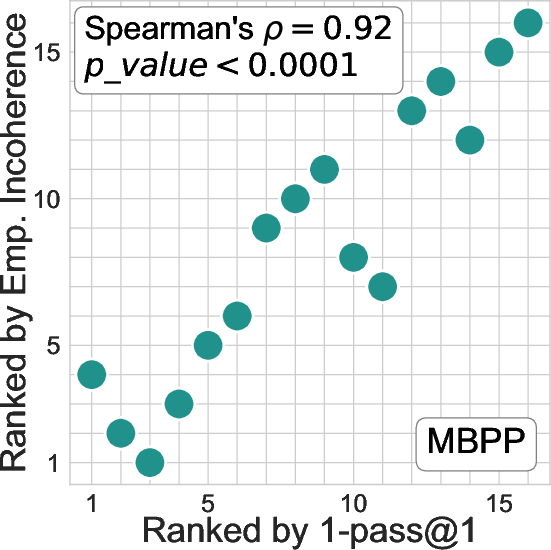
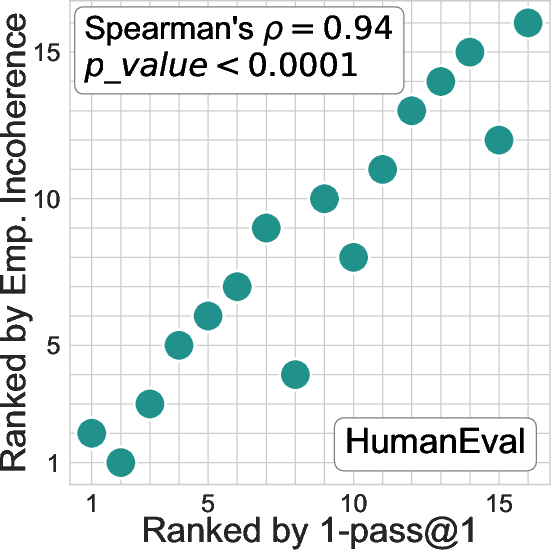
Figure 1: Rankings of 16 LLMs on the two most popular code generation benchmarks, MBPP and HumanEval.
This study builds on recent efforts to detect hallucinations in LLM outputs by leveraging the disagreement among independently sampled responses. The authors propose a novel measure called incoherence, which interprets disagreement between generated code samples as an indicator of incorrectness. By rigorously defining this measure, the authors bridge heuristic methods with a theoretically justified proxy for assessing model error.
Methodology
The proposed incoherence measure quantifies the behavioral divergence among independently generated program samples for a given task. Specifically, the authors define incoherence as the probability that two programs generated by an LLM will produce different outputs on the same input. The fundamental insight is leveraging this divergence to infer error likelihood: if two programs behave differently, at least one must be incorrect.
The study formalizes this concept within a probabilistic framework. Given a task d, two implementations generated by an LLM, and an input sampled from a distribution representing typical usage, incoherence measures functional divergence. This rigorous approach also provides a lower bound on the error, establishing that incoherence cannot exceed twice the model's functional error.
Experimental Results
Experiments were conducted on 16 state-of-the-art LLMs across two benchmarks, MBPP and HumanEval. The results affirmed the robustness of incoherence as an oracle-less evaluation metric. Notably, the incoherence measure closely matches traditional oracle-based evaluations (e.g., pass@1) in ranking LLMs by correctness, achieving high correlation values (Spearman's ρ≥0.92).
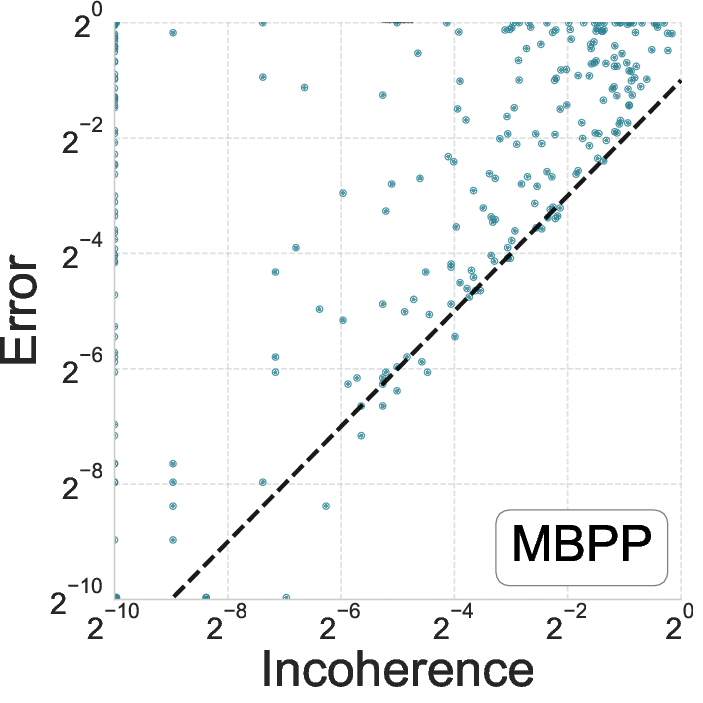
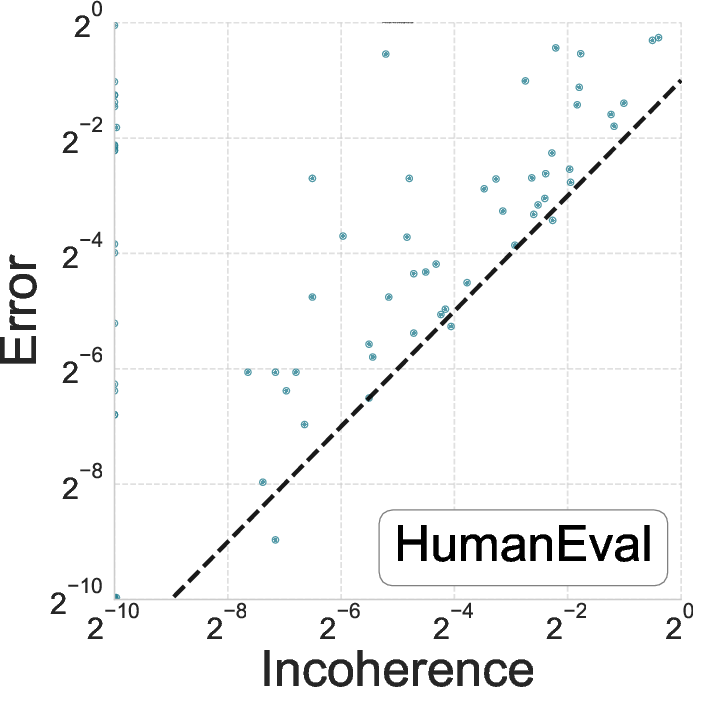
Figure 2: Relationship between error and incoherence for GPT-4o on MBPP and HumanEval benchmarks.
The incoherence measure successfully identified approximately two-thirds of incorrect programs, demonstrating its efficacy as a correctness proxy. Moreover, when incoherence was zero, the empirical error was significantly lower than average, reinforcing its utility in indicating trustworthiness.
Practical Implications and Future Directions
The implications of this research are profound for the deployment of LLMs in software engineering. The incoherence measure provides a cost-effective, scalable solution for evaluating code correctness without requiring exhaustive oracle data. This method mitigates the labor-intensive process of benchmark creation and reduces potential risks associated with data leakage and overfitting in model evaluations.
The authors suggest several practical considerations for implementing this approach, such as determining the optimal number of program samples and inputs to balance resource costs and detection efficacy. Future work may build on these insights to extend incoherence-based evaluations to more complex programming domains and languages.
Conclusion
The study presents a significant advancement in assessing the correctness of LLM-generated code through an oracle-less framework. By introducing incoherence as a statistically grounded measure of error, the authors offer a robust tool for ensuring the reliability of automated code generation. This contribution not only enhances the trustworthiness of LLM applications but also lays the groundwork for further innovations in AI-driven software development.