- The paper introduces Grounded Chain-of-Thought (GCoT) to integrate bounding box grounding into CoT reasoning, significantly improving model performance on specialized vision tasks.
- It employs an iterative bootstrapping loop to refine sub-questions and generate bounding boxes, achieving superior accuracy with as few as 16 labeled examples.
- The paper presents a scalable, data-efficient model adaptation approach that minimizes reliance on large task-specific datasets and opens avenues for reinforcement learning enhancements.
Bootstrapping Grounded Chain-of-Thought in Multimodal LLMs for Data-Efficient Model Adaptation
Introduction
Multimodal LLMs (MLLMs), which integrate LLMs with vision encoders, are increasingly pivotal in AI research, particularly in tasks requiring natural language interpretation of images. However, these models encounter challenges when adapting to specialized tasks such as chart understanding without extensive task-specific retraining data. This paper identifies a key issue: the mismatch between the generic pre-training data—often object-centric—and specialized downstream requirements such as interpreting charts and tables. A novel approach is proposed in this paper, utilizing Chain-of-Thought (CoT) reasoning data to enhance model adaptation under data-limited scenarios.
Grounded Chain-of-Thought (GCoT) Methodology
The paper introduces Grounded Chain-of-Thought (GCoT), a bootstrapping approach designed to inject grounding information, particularly bounding boxes, into CoT data. This method aims to rectify factual errors prevalent in reasoning steps generated by pre-trained MLLMs. The GCoT generation process starts with distilled CoT data from a third-party model. From this initial data, sub-questions are extracted to guide a bootstrapping loop where bounding boxes are iteratively generated and refined through self-verification, ensuring the faithful representation of input images.
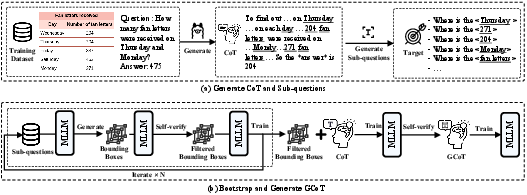
Figure 1: Overview of GCoT generation process, detailing iterative bootstrapping for bounding box creation and refinement.
Experimental Evaluation
The GCoT approach was evaluated across five specialized vision tasks involving diverse visual formats, including charts, tables, receipts, and reports. Results underscored the efficacy of GCoT in data-limited regimes, significantly outperforming traditional fine-tuning and CoT distillation methods. For example, when trained on just 16 labeled examples, GCoT demonstrated superior performance compared to zero-shot baselines, affirming its efficiency in model adaptation without extensive retraining.
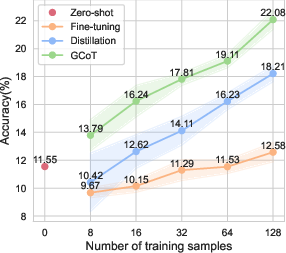
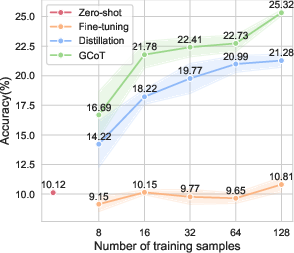
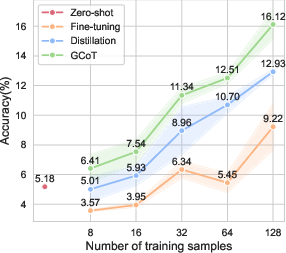
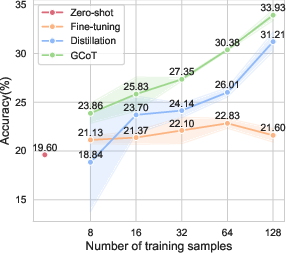
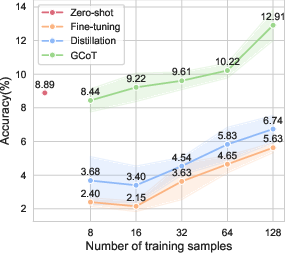
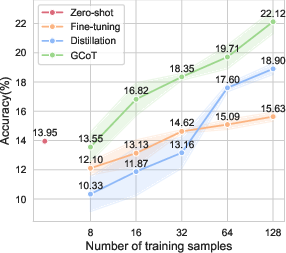
Figure 2: Average performance results across specialized vision datasets under different training sample conditions.
This research aligns with extensive efforts to improve MLLMs' performance in vision-language tasks. Previous studies have focused on enhancing modality alignment through training data from LAION400M, Visual Genome, and similar datasets. While substantial datasets have been developed for chart understanding, including ChartLLaMA and ChartAssistant, this paper advances the field by proposing a data-efficient solution that leverages CoT reasoning.
Implications and Future Directions
The GCoT methodology not only bolsters the adaptation of MLLMs to specialized tasks but also offers a scalable solution that minimizes the need for large-scale task-specific datasets. Going forward, the adoption of reinforcement learning techniques could further refine the model's grounding capability, potentially extending its applicability to more abstract visual formats such as iconography or line diagrams.
Conclusion
This paper presents a compelling approach to enhancing data efficiency in model adaptation for specialized tasks using MLLMs. By integrating grounding information into the reasoning process, the proposed GCoT method facilitates a more faithful and generalizable learning pathway. As AI models grow in complexity, methods like GCoT will be instrumental in democratizing their capabilities across diverse application domains, ensuring robust performance even with limited labeled data.
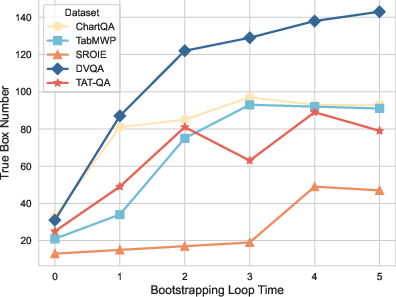
Figure 3: Analysis of bootstrapping loop impact on bounding box generation accuracy.