- The paper demonstrates that instance-level unstructured reasoning achieves up to an 18.90% accuracy improvement over structured JSON plans in benchmarks like MATH.
- The Self-Discover framework adapts reasoning strategies for individual instances, revealing context-dependent effectiveness across tasks such as BBH and T4D.
- Few-shot guidance notably enhances performance in coherent tasks, though its benefit may wane with diverse problem types due to introduced noise.
Effects of Structure on Reasoning in Instance-Level Self-Discover
Introduction
The integration of LLMs into complex systems has led to the adoption of structured output formats, such as JSON, for predictable and controllable model behavior. However, the emergence of techniques like Chain of Thought (CoT) has brought about models capable of strong reasoning, albeit with challenges such as increased computational demands. The paper introduces an instance-level adaptation of the Self-Discover framework to compare dynamically generated structured JSON reasoning with unstructured natural language reasoning, demonstrating that unstructured approaches outperform structured ones in reasoning tasks.
Self-Discover Framework
The Self-Discover framework allows LLMs to dynamically generate task-specific JSON structures, offering a flexible approach to reasoning. However, concerns exist that structured formats might degrade LLM performance. The framework, detailed in the accompanying figures, involves multiple stages for generating reasoning structures and executing plans. The new instance-level version focuses on generating reasoning plans for individual task instances, rather than for the entire task type, evaluating both structured and unstructured reasoning approaches.

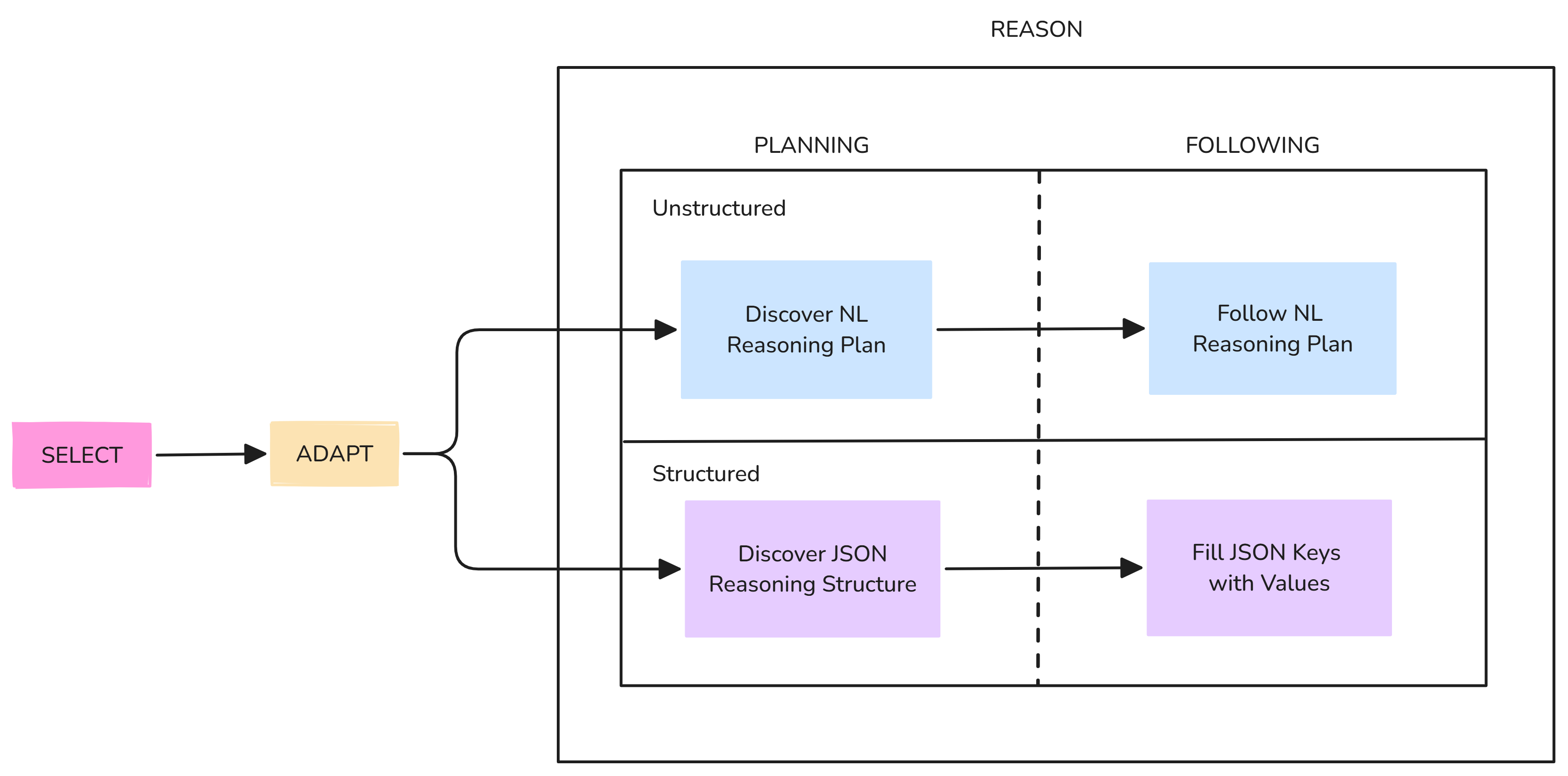
Figure 1: The original Self-Discover framework, illustrating its phase-based reasoning process.
Experimentation Setup
The experiments assess the performance of both structured and unstructured reasoning in the Self-Discover framework across various benchmarks: BBH (BIG-Bench Hard), T4D (Thinking for Doing), and MATH. The approach involves two main configurations: zero-shot and five-shot settings to gauge the potential advantages of providing contextual examples.
Results
- Unstructured vs. Structured Reasoning: Unstructured reasoning consistently outperformed structured reasoning. Notably, in the MATH benchmark, unstructured plans achieved up to an 18.90% improvement in accuracy compared to structured JSON plans.
- Granularity of Reasoning Plan Generation: The results highlight context-dependency in the effectiveness of reasoning strategies. Instance-level reasoning demonstrated advantages in diverse benchmarks like BBH, while task-level reasoning was more effective on coherent benchmarks such as T4D.
- Impact of Few-Shot Guidance: Providing few-shot guidance enhanced performance in coherent tasks (e.g., T4D), leading to significant improvements in accuracy in unstructured plans. However, its utility was limited in tasks with diverse problem types where additional examples introduced noise.

Figure 2: General prompt structure for the SELECT and ADAPT stages in Self-Discover.

Figure 3: Prompt structure for the REASON stage, illustrating the distinct processes for structured and unstructured plans.
Discussion
The paper provides compelling evidence to reassess the reliance on structured formats in problem-solving tasks with LLMs. The findings suggest that unstructured reasoning can better align with the inherent training of LLMs, potentially accelerating reasoning capacity in AI systems. In contexts where interpretability and precision are crucial, however, structured outputs may still hold value. Future work could explore more adaptive systems that dynamically select reasoning styles and granularity based on the task context.
Conclusion
The paper demonstrates the advantages of unstructured reasoning over structured approaches in LLMs, particularly when employing instance-level Self-Discover techniques. The insights emphasize context-adaptive reasoning as a potentially superior strategy in complex AI applications, challenging the prevailing reliance on structured outputs. Further research into the trade-offs and optimized strategies for different types of reasoning tasks remains an important area for development in AI.
Overall, the study underscores the need to explore flexible reasoning structures in the deployment of LLM systems to harness their full potential effectively.